The Top 5 Network Support Tickets to Automate
What frustrates you the most about network support? Nothing feels better than playing detective on an obscure network issue and being the IT hero who resolves it. But too much...

Ch-ch-ch-ch-changes, turn and face the strange, ch-ch-changes…
— David Bowie
Change is hard. Organizations of all sizes struggle with implementing the changes necessary to keep relevant and competitive in a constantly changing economy. Whether being dictated by economic, organizational or technological evolution, change has become the one constant businesses can count on. However, one area where the velocity of change eclipses all else is the network. Networks have an enormous blast radius, so changes are inherently risky. NetBrain helps reduce that risk by bringing automation to the most challenging aspects of network change management. As attendees to Cisco Live in Orlando witnessed recently, we’ve unveiled some exciting new updates to our change management capabilities.
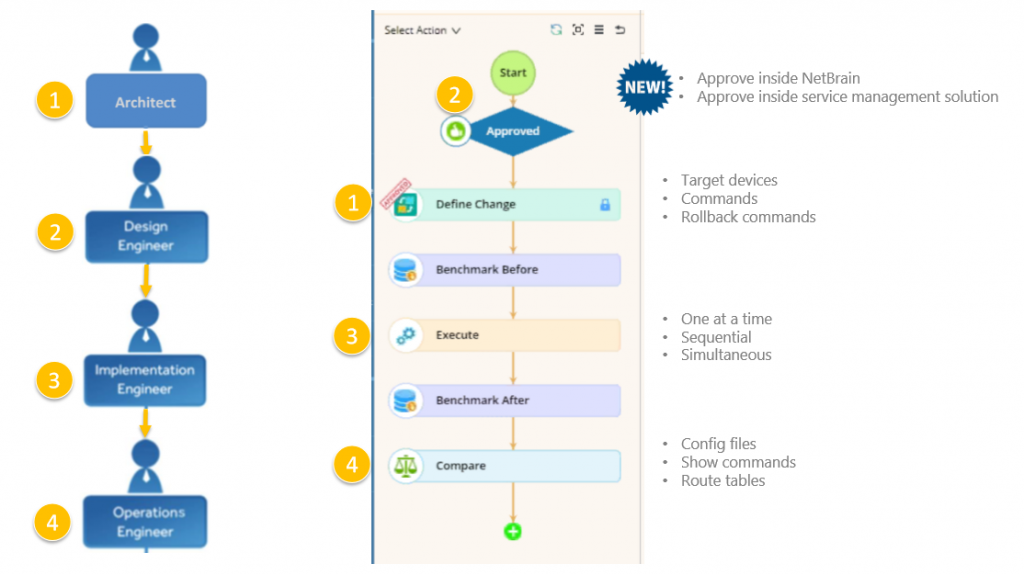
NetBrain now integrates seamlessly with your existing change workflow and whatever tool you use to approve changes (e.g., ServiceNow). It streamlines the process of checks and balances to ensure that every change is defined, approved and validated.
NetBrain now integrates seamlessly with your existing change workflow and whatever tool you use to approve changes (e.g., ServiceNow).
Check out our 1-minute video from CiscoLive! to see NetBrain change management in action.
NetBrain integrates within your existing ServiceNow change management workflow.
Actually pushing network configuration changes is not a huge challenge. Implementing 50 or so lines of configuration change takes about half an hour. Dealing with the repercussions of an ill-advised or incorrect change, however, can take hours or even days. It’s not the “I” along the PPDIO (Prepare-Plan-Design-Implement-Operate-Optimize) process that’s tricky, it’s everything else. That 30-minute push is the result of 5 days, maybe even 5 weeks, of preparing, planning, and designing the change. And then there’s verifying the impact of those changes. This is where NetBrain excels. NetBrain’s automated network change management capabilities take a holistic approach where deep network visibility and automation enable you to design changes visually, deploy changes across different devices from different vendors automatically, analyze their impact immediately, and document everything on the fly.
 Benchmark the network before and after changes for comparative analysis of config files, show commands and route tables.
Benchmark the network before and after changes for comparative analysis of config files, show commands and route tables.
As the figure above demonstrates, all potential changes to the network configuration are put through a definitive set of benchmarking evaluations to ensure that no change results in unintended consequences to other areas of the network. This workflow process increases operational efficiency and, most important, avoids costly downtime and long troubleshooting exercises cause by configuration errors.
NetBrain takes a snapshot of the network before and after changes for comparative analysis of config files, show commands and route tables.
Making it even easier, NetBrain allows network engineers to configure and approve changes inside NetBrain directly, or via an external service management system — ServiceNow, for example. Once a change gets approved in ServiceNow, you continue the process right inside NetBrain to push out the changes, validate them with our Runbook Automation technology, and roll back if necessary.
Change is hard. Change is uncomfortable. Change is absolutely necessary to keep pace with changing business conditions. While we can’t speak for all levels of your organization, when it comes to your network configurations, you can turn and face the strange with confidence when deploying NetBrain.
Learn more about NetBrain change management capabilities in our Overview of NetBrain’s Change Management Approach solution brief.