What Happens After BGP?
Gaining Full Path Visibility in Hybrid Cloud Networks In the modern enterprise, Border Gateway Protocol (BGP) plays a foundational role in connecting distributed networks. It is the routing protocol that...

Let’s face it – manually troubleshooting hybrid networks is painful and time-consuming. Every problem is addressed as if the problem has never occurred previously and various network engineers apply different solutions to similar problems based on their expertise and experience. The result is today’s network troubleshooting is more of an Art than a Science- which is a significant problem by itself! To make matters worse, escalation engineers are limited in number and when engaged, must repeat initial investigation steps because of limited context, workflow challenges, and differing approaches.
Case in point: a well-known electric vehicle manufacturer was drowning in service requests for specific networking data from other IT departments. For example, the security and IT infrastructure teams often needed to know the switch port that a specific device like a camera was plugged into or wanted to find ports that were not being utilized where they could deploy additional devices. Second, staying on top of weekly device change requests, password rotations, and hardware refreshes was challenging. Keeping all this running and in support of the business while responding to the stream of constant requests from other IT departments was overwhelming.
Now, more automation is required due to the sheer volume of service tickets and the leveling off of NOC personnel to handle them. Budgets are tight and skilled resources are limited. And, we know, we aren’t exactly overflowing with skilled network engineers to spare for every time a slow app is reported, or a connection drops. Many fit the bill of common repetitive issues which can easily be handled by level 1 operations if only they had the diagnostic tools. Yet, troubleshooting is seen as a team effort using a manual response protocol:
👨💻 Level 1 engineer diagnosis > 🎫 Ticket escalation > 👨💼 Level 2 engineer diagnosis, and so forth.
What’s more, there are false positives from our monitoring tools that lead to endless chasing of ghosts, like flapping. If only there was a way to filter these transient problems out.
While automation has long been the desired solution to speed up troubleshooting, most of these efforts become developer-led projects that fail to deliver enough results. And when grass-roots automation is attempted, it takes the form of user-specific scripting, which also fails to meet the efficiency goal. Neither of these approaches transforms the organization’s core reference workflow. Neither approach can be re-used across the organization, reduces MTTR, scales to a multi-vendor network, enhances collaboration, prevents issues from reoccurring, or maximizes efficiency in any significant manner.
To address these operational shortcomings, an entirely new and machine-centric approach must be implemented for network operations. It requires a fundamental change to the way network engineers think about operations, including network automation in everything they do. To do so requires an automation platform available to all engineering resources (without the need for code). These skilled engineers already know how to solve problems- they need a simple way to capture their deep problem-solving experience and make it executable by machine by anyone who wants to address the same troubleshooting situation, anywhere in the infrastructure. With the right platform, every engineer becomes a network automation engineer able to create network automation for any problem big or small in minutes, not months.
Implement a no-code automation platform that empowers all levels of staff to take part in troubleshooting automation. By eliminating script-heavy approaches, automation can be created in minutes, applied across the multi-vendor network, and reused by anyone.
Integrate automation into the troubleshooting workflow at the outset of ticket creation to act as a filter and provide initial diagnosis and mapping capabilities. This proactive approach can significantly reduce the volume of service tickets by automatically closing non-issues and streamlining basic troubleshooting tasks. For example, if there is BGP flapping, NetBrain runs auto-diagnosis 3 times at 15-minute intervals, and, if all clear, it auto-closes the ticket. That could potentially reduce your ticket volume by 1/3rd!
For known issues, your staff doesn’t have to get involved in basic troubleshooting tasks such as ping, traceroute and pulling up a map as the machine does it all. It can look for the automation to run to diagnose the issue for you giving you a clear picture of what is going on in the network.
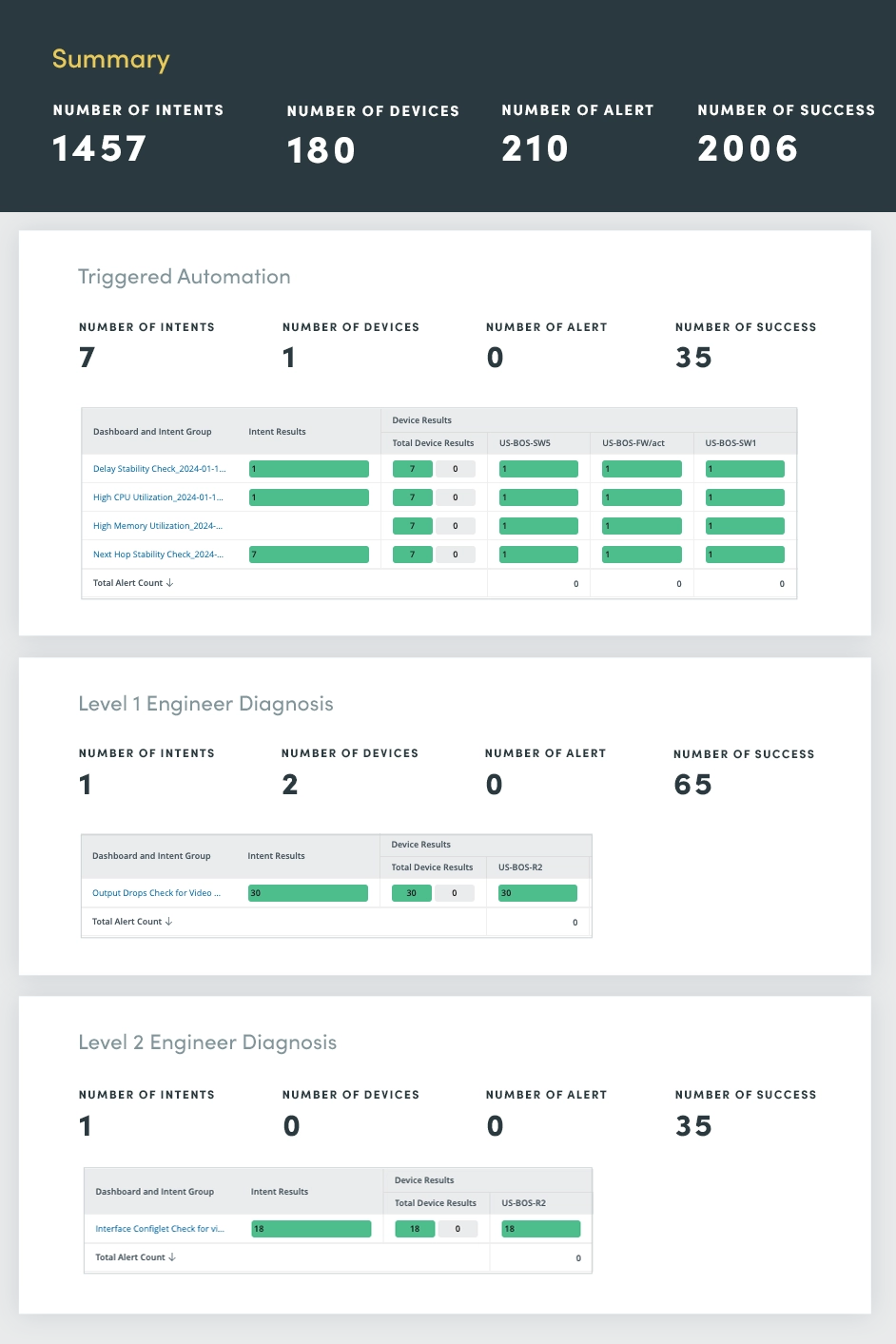
In essence, automation becomes level 0 in the NOC offloading time-consuming tasks to the machine. But, in cases where issues need to be escalated, level 1 can provide a receipt of preliminary troubleshooting in a collaborative incident dashboard removing the need for redundant troubleshooting steps at each level.
Look for a platform that offers an extensive and shareable automation library that’s offers pre-built automation for most common issues to start out with. Additionally, it should provide engineers with the capability to create custom automation in minutes without coding in a visual interface, ensuring extensibility and adaptability to evolving network requirements. When creating new automation, automation can be decoded across your multi-vendor network and stored in your library for use by any operator thus creating an automation flywheel that grows with your organization!
In fact, according to a recent EMA study of over 350 IT professionals, 45% ranked IT service management/ticketing systems their number one priority of systems to integrate with their organizations’ network automation tools. This integration facilitates event management and creates a unified troubleshooting workflow to streamline ticket handling activities.
Case in point follow-up: Let’s revisit our electric vehicle manufacturer to see how they used no-code network automation to resolve their troubleshooting and other operational challenges. As a key part of their troubleshooting workflow; they use NetBrain to generate network topology diagrams on demand to easily visualize critical network information, like the exact firewall and firewall policies that may be blocking specific application traffic. One senior network manager also singled out how helpful NetBrain is for password rotations as part of their security task list; NetBrain can detect any network devices still using old passwords (perhaps because they were online during the refresh). Detecting security and compliance issues automatically across their entire global network is a huge time-saver.
By adhering to these best practices and embracing a platform-based no-code approach to your network automation workflow, your organization can optimize troubleshooting processes, enhance operational efficiency, and alleviate the strain on limited resources.