 by Paul Campbell Mar 14, 2019
by Paul Campbell Mar 14, 2019
How many of you have troubleshot, dealt with a support case, or had a customer call related to an intermittent network issue? I would imagine a lot. Most individuals in some form of an IT-related field tend to be more analytically minded. With an analytical mind, we often think that if it keeps happening, we must be able to repeat it. In most instances, you’re right. However, as I’ve been doing various forms of IT work for nearly twenty years, I can assure you that this isn’t always the case.
Intermittent network issues are events that are not so easily replicated. Nor do they come at the same time of day or always affect the same users. As someone who has tackled these kinds of problems at various positions, let me tell you they are horrible to come across. You feel helpless, and you sometimes question your sanity!
NetBrain allowed us to pinpoint the issue and have somewhere to start. Solving any problem requires understanding the problem, and without NetBrain, I’m not sure we would have been so quick to understand where to begin.
True Story: Intermittent Outages Six Weeks After an Upgrade
I once had a client that was upgrading from a legacy Cisco environment to a newer Cisco Nexus environment, back when the 7K/5K/2K architecture came out and was taking the market by storm. Part of our consulting engagement involved a network assessment before we even began. Why? We wanted to ensure a seamless transition to the new architecture and check that every base was covered. We strive for no outages, downtime, or impact of any sort. However, things do occur that are sometimes out of our control. (Foreshadowing, maybe?)
Upon completion of the cutover, all tests were passed, and all teams were happy. It wasn’t a week, two weeks, or three weeks later that we got a callback. It was about six weeks into their standard operations when the client called, concerned that they were having intermittent outages and needed our help to understand what was wrong. It was an issue that seemingly affected random applications and random users. Like most people, we didn’t immediately think the new data center core was their issue. Why? It had been six weeks! Experience told us that most problems would have occurred and been noticed within 24 hours or a week at most, if any existed at all.
Why Aren’t NMS Solutions Picking Up the Problem?
What’s the first thing we did? Fired up NetBrain and re-ran an updated discovery of the network and compared it against our post-installation map. An exact duplicate, not even one CLI command was different between the two scans. We started discussing how nothing had changed since we left, which made the IT Director and VP feel comfortable that their team didn’t mess up. (It also made us feel great too.) But it didn’t help anyone feel good about fixing the issue at hand – an intermittent gremlin that seemed to cause disconnects and black holes of traffic.
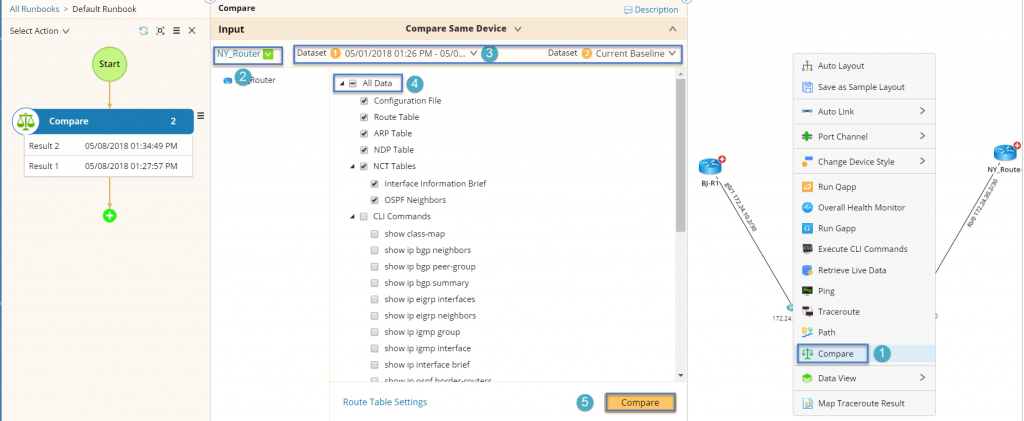 NetBrain can compare virtually any network data between live state and historical snapshots with just one click.
NetBrain can compare virtually any network data between live state and historical snapshots with just one click.
We agreed to stick around and leave a large-scale map up of the campus, data center, and a few remote sites in monitor mode overnight, ~16 hours in total. When we came back the next day, we noticed that some of the continual averages kept fluctuating widely for the second Nexus 7K. Finally, we had somewhere to start! We began with their network management solutions, which involved Splunk, SolarWinds, and a handful of other tools. They didn’t see any issues the previous night. Did they miss them, or were thresholds too low?
Going back to NetBrain, we noticed that traffic seemed to fluctuate in and out of the second Nexus 7K, which didn’t line up with the regular ingress/egress traffic pattern seen on the first Nexus 7K. Running in a pair, with as many vPC links as we had, this was odd.
You Can’t Fix What You Can’t See
What did we find? Well, we found a bug, an intermittent bug that would blackhole traffic. Bugs are inevitable; they happen on every product, software, or solution out there. We just so happened to hit a particular one in this case that would cause the backplane fabric modules to blackhole traffic as it tried to pass data from, say, slot 3 to slot 2. The backplane modules didn’t fail, so no alerts. The blackholing of traffic would occur at a buffer overflow due to other factors – the customer wasn’t pumping nearly enough data to be near the cap of data processing. A code release solved the issue. Happy customer.
NetBrain provided valuable insight into a situation where all other reasonable means of “what is normal” failed. The other tools could have been tuned in a way to catch what we needed, but it would also alert on far too many non-serious issues. NetBrain allowed us to pinpoint the issue and have somewhere to start. Solving any problem requires understanding the problem, and without NetBrain, I’m not sure we would have been so quick to understand where to begin.
One-click historical comparative analysis is just one way NetBrain helps tackle frustrating intermittent problems. It can also trigger an automated analysis from your 24×7 monitoring solution, ticketing system, IDS/SIEM the moment an issue is detected.
We call this “just in time” automation — see it in action by scheduling a demo here: show me just-in-time automation