The Top 5 Network Support Tickets to Automate
What frustrates you the most about network support? Nothing feels better than playing detective on an obscure network issue and being the IT hero who resolves it. But too much...

We get a lot of interest in NetBrain Next-Gen these days as the very core of how business manage their network operations has changed so dramatically over the past couple of years. The global pandemic was just the latest in a series of fundamental changes that are impacting the infrastructure world, so no surprise that CIOs and their teams are looking for ways of operating networks smarter, not just bigger.
The CIO knows that their business transformation has been instrumental to their growth but has now raised the stakes on the very nature of IT service delivery. They know what they need to deliver from the top down, it’s the translation of the business needs into network components where things get tough. At the end of the day, these CIOs know that when their networks stop or degrade, their business stops or degrades, and the repercussions of any hiccups in IT service delivery can be disastrous to the long-term bottom line.
Given that, one thing that keeps surprising me is how much people want to know about NetBrain’s Dynamic Maps yet they avoid diving into the higher impact automation parts of operational efficiency available now. Take for example NetBrain’s Runbook Automation. It’s one of the NetBrain Next-Gen core technologies and a very compelling feature for network engineers looking to act more efficiently and get in front of the growing chaos regularly appearing in large enterprises. And when you couple network-intent-based management, an abstraction layer, along with no-code network automation together, the paradigm of managing networks is stood on its head… top-down management is finally here!

I get that the word “automation” might be intimidating to network engineers since countless automation have come and gone, with high budgets and long development cycles, and in many cases yield no tangible results. Many network engineers continue to wait for network automation to become usable for THEIR problems, and they think that their problem is so unique that they never even really consider how those problems can be automated. So, they continue to solve problems manually, one at a time, over and over, brute-force and ad-hoc. Escalations to SMEs abound and knowledge sharing is not part of their equation.
NetBrain has produced a bespoke tool, which is not only multi-vendor but is done entirely without scripts with just your subject matter expertise. By parsing individual tasks during everyday operations as Intents into the Intent Library.
Suddenly the network engineer can create complex and abstract tasks for anyone to use without ever having to write a line of code. In this post, I’ve gathered and parsed information from our support staff and investigated 5 of the most common automation use cases NetBrain clients are implementing on their network.
#5: Outage Prevention – Around-the-clock early warning anomaly detection
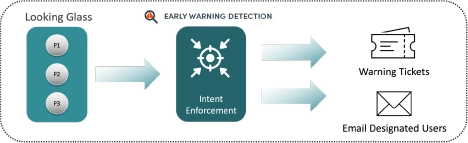
Network operations teams leverage NetBrain Next-Gen to spot problems before they manifest into production and can then proactively fix them. In essence, the real-time network is continuously compared to the long list of encoded intentions with differences indicating a potential problem in the making. Doing so eliminates more than half of all reported outages and service degradations, saving time and money.
#4: Automated Diagnostics – Time is everything, so responding instantly resolves issues quickly
Any IT department that gets large enough is going to need a ticketing system, among other services. Where this gets tough is when people find themselves hopping through different applications and silos in order to find all of the relevant and necessary information to troubleshoot an issue, or when a change process becomes stuck because it hasn’t received a stamp of approval yet.
By automatically determining the root cause of any detected issue, problems are pinpointed the moment they occur, and operations teams can spend their time fixing problems rather than trying to find them. To further reduce remediation time (MTTR), NetBrain shares across the organization all the automated best practices required to fix the most common issues quickly and consistent.
ServiceNow NetBrain integration
NetBrain offers its own internal verification system, but it can also integrate with third-party ticketing systems like ServiceNow.
Being able to link ServiceNow tickets to a map comes with multiple benefits.
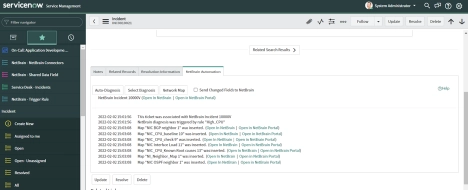
NetBrain automatically generates a map representing the ‘problem area’ identified with the ticket. During ‘Just-in-time’ automation, the system performs basic diagnoses such as an Overall Health Monitor and Raw CLI data collection and provides this information to the engineer as they arrive on the scene, eliminating the time they’d otherwise spend performing the same tasks. The best part is this isn’t limited to one application. Any ticketing system with an API can be integrated into NetBrain to achieve the same effect.
#3: Network Security: Continuous observability and verification of network security (device, border, edge, zone) to ensure it is active and allowed
The larger attack surfaces common in today’s enterprise mandates that organizations ensure security controls are in place and operating the way they were designed to operate. This enables organizations to mitigate risk while ensuring compliance. By encoding security requirements into automated intents, NetBrain Next-Gen offers the ability to continuously verify that intended security policies are in effect.
Securing network infrastructure, while absolutely critical, creates the illusion of protection. But as most NetOps teams know, the intent of that infrastructure is quickly reduced over time as changes to the network, configuration drift, performance degradation, infrastructure failure, and the emergence of new attack vectors significantly compromise the effectiveness of your security designs.
Multi-layer security demands continuous verification that networks security components are functioning as your security architects intended. That’s no easy task even when basic network automation is applied. For true security enforcement, a network automation platform must understand the intentions of the security design. Intent-based automation incorporates security Intents into your standard operating procedures through continuous network policy and rule enforcement.
#2: Protected Change – Take “uh-oh” out of the NetOps vernacular
Most importantly, NetBrain provides structured change management that establishes the condition of the network before any change is made, automates the change, and then verifies that the long list of network intents is still intact after the change has been made. As a result, network operations teams can eliminate any unintended consequences and, if problems do arise, quickly roll back to a last-known good state.
IBA leverages both human understandings in the form of Intent and machine-driven consistency and precision in the form of automation to transform the traditionally precarious change process into secure and protected change management. From design to planning to execution to validation, IBA removes doubt and fear and eliminates outages and other unintended consequences resulting from changes.
#1: Application Performance – Instill confidence in your network with higher application performance standards
Every application and IT service expects the network to support its specific needs. Within the NetBrain Next-Gen, these needs are encoded into network intents, creating an expansive list of behaviors that must exist in order for the business to operate properly. NetBrain Next-Gen continuously assures that the needs of all services are being met.
An Intent-based network automation solution must ensure the availability and performance of every individual business application’s traffic path. Identification and baselining of traffic paths and dependencies is also required to enforce the architects’ designs and policies. Continuous validation of key stats and metrics is imperative to maintaining quality application performance. And quick diagnosis and remediation of disruptions is paramount.