 by Phillip Gervasi Feb 15, 2018
by Phillip Gervasi Feb 15, 2018
Network automation doesn’t stop after devices have been provisioned and deployed. A programmatic approach to networking certainly has value as it provides agility to provisioning new devices and services, but that’s only the beginning. NetOps automation must be part of an ongoing network operations workflows as well.
The way we handle tasks such as monitoring, security incident management, and network troubleshooting is often inefficient, tedious, and performed in the dark. Automating routine tasks certainly saves time, but there’s nothing routine about network operations. A network outage or security breach is a serious matter of urgency to IT and to the business it serves, and NetOps automation provides the agility and framework to handle these tasks efficiently.
Monitoring
It can be difficult to get the customized monitoring an engineer needs. Often it’s because popular network monitoring tools collect only generic information, looking only for symptoms of a problem such as high CPU utilization or an oversubscribed link. NetOps automation solves this problem in several ways.
First, network monitoring must also proactively monitor for underlying problems, and often this is in the form of configuration errors. Network operations needs to know the network is configured correctly in the first place. Changes occur frequently, and even with the best change management, errors still occur which lead to incidents that could have been avoided. Network operations needs some form of change assurance to continually monitor configuration using the single source of truth, the network itself.
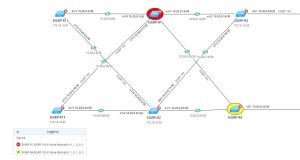
For example, a network running EIGRP using rotating keys for authentication will have an accept-time and send-lifetime configured among routers in the EIGRP domain in order to synchronize which keys to use and when. If there is a configuration error leading to mismatched authentication or expired keys, routers could lose adjacencies and break routing for an organization.
This example doesn’t describe a failed router or a broken link. It describes a misconfiguration error that can very easily be missed by an engineer or a change management board. Proactive and programmatic monitoring doesn’t rely on a good set of eyes logging into router after router; instead, it automates the process and provides configuration change assurance that can help avoid unnecessary incidents.
Programmatically accessing the single source of truth also solves the monitoring problem by providing a holistic view of the network beyond that which traditional monitoring tools can provide.
For example, seldom does network monitoring software provide layer 2 visibility into the path an application takes across a network. However, NetOps automation can be used to track which ports are in a Spanning Tree forwarding or blocking state and present that information in such a way that an engineer can trace even layer 2 paths across a large network.
Security Incident Management
The problem with infrastructure security is that it has many tentacles. It touches switches, firewalls, routers, load balancers, servers, workstations, and all the applications running over the wire.
But remember that NetOps automation provides the means for a proactive and programmatic approach to operations. In this way, operations can rely on automated processes to proactively monitor the infrastructure for configuration errors without requiring an engineer to log into an assortment of devices one at a time. Consequently, a security team can prevent a potential security incident before it occurs.
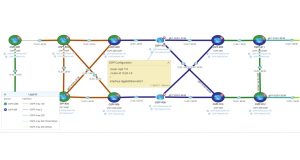
For example, a network running OSPF using MD5 authentication is an important part of securing adjacencies in an OSPF routing domain. On Cisco routers, the command ip ospf authentication message-digest enables MD5 authentication, but it must be followed up with the command ip ospf message-digest-key [key] in order to work. A common configuration error is to use the command ip ospf authentication key [key] which enables plain text authentication and has nothing to do with MD5.
In this example, an OSPF routing domain a security team thought was secure is actually completely unauthenticated and vulnerable to hijacking. This is a simple configuration error and is easily avoidable with proper configuration monitoring.
But even with correct device configurations, security incidents can occur. It’s critical that a security team has the ability to stop the bleeding of a breach as quickly as possible.
During a breach, there’s no time for security engineers to log into each device’s CLI one at a time, hunting for information. In this case, NetOps automation provides an event-triggered programmatic approach to gathering information, the lifeblood of security operations, at the time of the incident and before engineers begin troubleshooting. In this way a security team has immediate access to information that can be shared easily across teams.
Troubleshooting
Similarly, before level 1 engineers can even begin to diagnose a problem, they need to consider a significant amount of information that itself can take a long while to gather manually. NetOps automation eliminates this time-waste and therefore reduces the mean time to resolution of an incident. And if an engineer needs ephemeral data that exists only for a short time on a device, it will be very difficult to extract the key data by logging into multiple devices manually.
For example, this is profoundly powerful in the hands of a network engineer troubleshooting intermittent problems with a global company’s line of business application. There are just too many technologies to investigate at a moment’s notice, and there are just too many devices to log into.
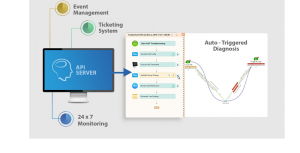
NetBrain’s Programmatic Approach
NetBrain’s approach is to fully integrate with network devices and other tools in order to create an ecosystem of automation. NetBrain starts by creating maps of a network and gathering device information from the devices themselves, an engineer’s single source of truth.
With this device-level information, NetBrain creates network baselines that teams and other tools can refer to. But remember that NetBrain operates programmatically at the device level, meaning an network engineer doesn’t have to manually log into the CLI of multiple devices. Instead, a team can set up workflows in NetBrain to monitor the network and react automatically when triggered by some event.
This is how NetBrain’s API-triggered diagnosis integration with ServiceNow operates, for example, and this is machine-to-machine communication that provides that same Day 0 agility to Day 2 operations.
NetOps automation is much more than writing scripts. This is no pipe dream making its way through the hype cycle; NetOps automation solves actual problems today and measurably improves processes for future operations.
A programmatic approach to Day 0 device provisioning certainly has value, but that’s only the beginning. NetOps automation must also be part of an ongoing network operations workflows in order to provide the same agility to proactive network monitoring, security incident management, and network troubleshooting.