 by Mark Harris May 17, 2018
by Mark Harris May 17, 2018
How Scheduled Automation Can Improve Network Health
Every IT organization is measured against two critical metrics: total service downtime, and mean time to repair (MTTR). The Network Performance Monitoring and Diagnostics market aims to address these two goals, but these solutions are better at minimizing an outage than preventing one. To minimize an outage it helps to proactively monitor for performance symptoms, but to prevent one you must have the tools to monitor the network for underlying problems.
To illustrate what I mean, let’s compare your network’s health to your heart health. Since the network is the lifeblood of a business, this seems like an apt analogy. When it comes to your heart health, you have the same two objectives as your IT organization – to avoid service downtime (e.g. a crippling heart attack) and reduce mean time to repair (get medical help quickly). Let’s look at three levels of maturity for addressing a potential crisis, using this analogy:
Level 1 – Reacting to Crisis
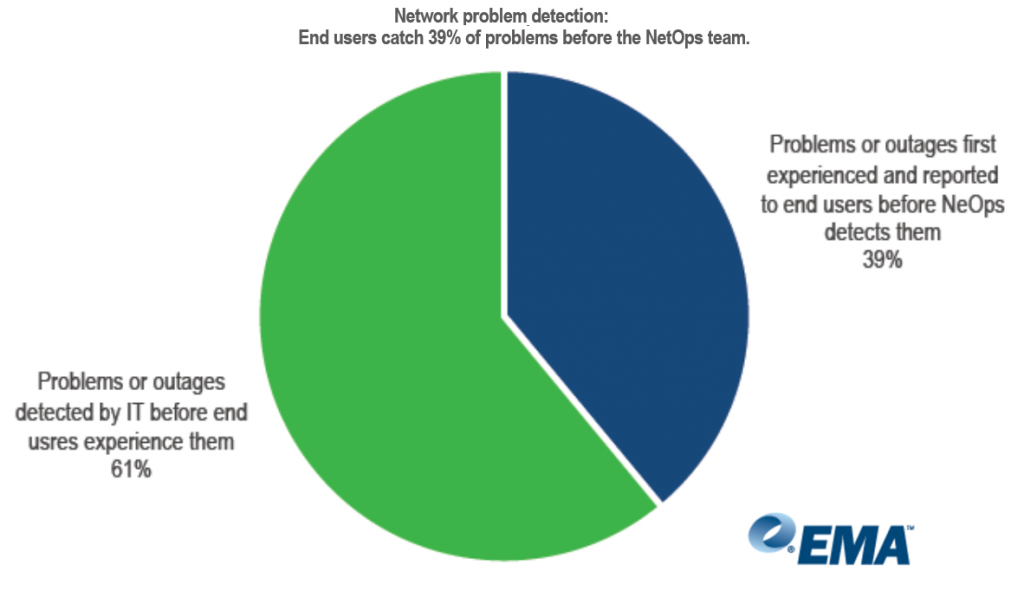
Let’s say the network is having a heart attack that went undetected. You can imagine a worst case scenario… the CEO is about to present at a board meeting but can’t connect to the network. Tempers are flaring, and the call is made to escalate the issue to Tier-3. This is like making a 911 call to request a helicopter lift. Maybe the analogy is more dramatic than any outage you’ve experienced, but its never a good thing when the end user reports an issue before the network team knows about it. According to the 2018 Network Management Megatrends report by EMA, 39% of problems or outages are experienced and reported by the end user before the NetOps team detects them.
Level 2 – Minimizing a Crisis
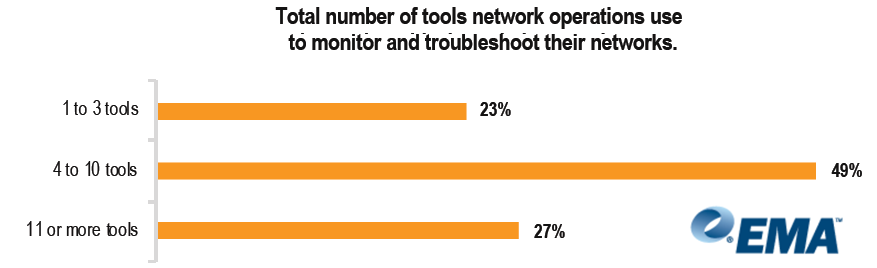
Next, let’s say the network is experiencing early signs of distress. The situation is a little less dire, but still urgent. Your NMS detected high utilization on the link between the data center and the headquarters office. Your told that your CEO’s board presentation is 1.5 hours away and he’ll need to connect to an app in that data center. The clock is ticking and it’s time to bring in the big guns to solve the problem. This is like experiencing early signs of a heart attack – chest pain, weakness, and nausea. It’s time to call 911, but your NMS has bought you valuable time. According to EMA, 76% of network operations teams require four or more tools to help them monitor their networks so they can respond more proactively.
Level 3 – Preventing a Potential Crisis
Now, imagine the network team was able to isolate the problem just in time. The underlying problem was that a firewall failed over in the data center… the backup kicked in properly, but it was not configured the same as the primary and it couldn’t handle the high bandwidth demands. This raises the question, “do we have a similar problem elsewhere in our network?” You might kick off a project to inspect all the configs on the backup firewalls. If you have dozens of these, it may take a long time to do this manually. So maybe you’ll use a NetBrain Qapp to automate this.
“Do we have a similar problem elsewhere in our network?”
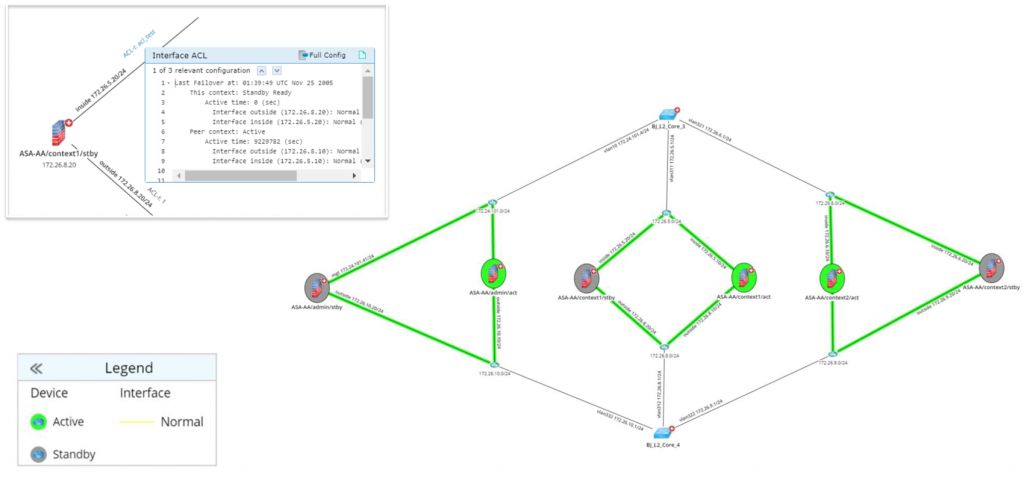
Qapp: Automatically Compare Configs Between Active & Standby Firewalls
If you want peace of mind to know that this problem will never appear again, you could continuously monitor for this underlying problem. This is now possible thanks to Qapp Scheduler, introduced in NetBrain 7.1. Now, every time you solve a problem you can begin to continuously monitor for that problem to ensure it doesn’t rear its ugly head again. Just create a Qapp, and schedule it to run on a recurring frequency – for example, every 10 minutes, from 01:00 AM to 04:00 AM, daily.
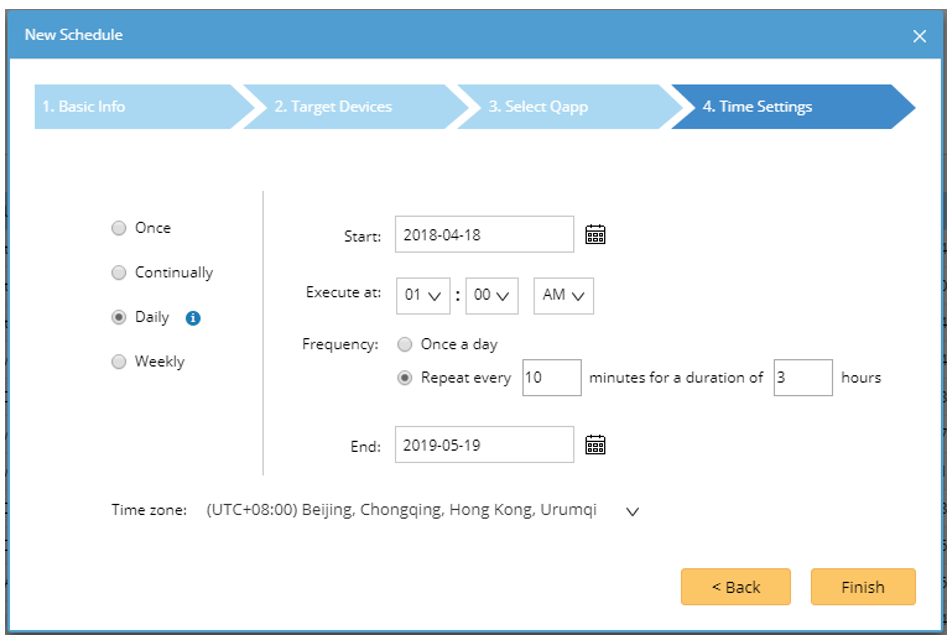
Schedule Qapp to run every 10 minutes, from 01:00 AM to 04:00 AM, daily.
It might not be practical to continuously monitor for every possible problem. But if your family has a history of heart disease, it’s a good idea to schedule frequent heart exams, maintain healthy blood pressure, and make exercise a daily habit. If we learn from the lessons of our past, we have improved odds against adversity in the future.
