 by Phillip Gervasi Sep 28, 2018
by Phillip Gervasi Sep 28, 2018
Most of the time, VoIP troubleshooting means solving some sort of network problem. This isn’t to say that all VoIP problems are network problems: there may be issues with how phones register, with firmware versions, with the call manager configuration, and so on, but when it comes to VoIP troubleshooting actual audio issues such as one-way audio, internal calls not forwarding properly, or poor audio quality, I’ve found that it’s almost always the network.
What is VoIP?
When a call is placed on a “voice over Internet protocol”, or VoIP, phone, the call first connects to the call manager. The call manager then rings the recipient’s phone, and when someone answers, the call manager releases the audio stream to the individual devices. At this point, the two phones speak directly to each other in real-time.
“As much I hate to admit it, VoIP troubleshooting usually means solving a network problem.” – A Network Engineer
That’s a very basic overview of how a typical call setup occurs, but factor in that phones may be in different geographic locations and in different subnets. No longer is it just a matter of a phone being able to reach a call manager. Bi-directional communication between endpoints must work perfectly as well, and in complex networks that means contending with firewalls, dynamic routing, access control lists, and asymmetric routing.
Most VoIP audio traffic uses the real-time transport protocol, or RTP, as its transport. RTP between two endpoints exists as a UDP stream that is completely dependent on the underlying network; therefore, any problem with the network that prevents one side of the audio stream from getting to the other results in an audio problem.
VoIP Troubleshooting
After confirming that the phones are registered and receiving correct IP addresses and VLANs, VoIP troubleshooting typically begins with tracing the flow hop by hop. However, this can be incredibly tedious and time-consuming. It involves packet captures, logging into numerous devices, finding someone to access phones in person, and crawling the network hop by hop with the goal of finding exactly where in the path communication is broken.
“Ping and traceroute have serious limitations for VoIP troubleshooting of audio issues.”
Typically, engineers use simple tools like ping and traceroute to map a path between phones. These are easy-to-use built-in tools, so they are by far the most common for an engineer to begin with. However, though they certainly have their place in networking, ping and traceroute have serious limitations for VoIP troubleshooting of audio issues.
- First, in a complex network, tracing the path between endpoints can take a very long time. I’ve spent hours VoIP troubleshooting in this manner, only to open multiple TAC cases and packet captures — and this is exacerbated when you don’t know the network very well.
- Second, traceroute only looks at layer 3 hops, and only those layer 3 devices configured to respond to ICMP will show up in the trace. This poses a huge problem for VoIP troubleshooting of audio problems. If by design some devices aren’t responding to traceroute, how can we identify where the path is failing?
- Traceroute doesn’t account for asymmetric routing, which is very common in large networks. For example, I worked on a one-way audio issue for a customer who had dozens of locations in my region, and the path from one site to another was often different than its return traffic. Especially if there’s some sort of multi-path technology being utilized, tracing bi-directional paths that may change from flow to flow can be an exercise in futility.
- Traceroute doesn’t account for layer 2 devices. Though there may be only a couple of routers between two phones, there could very well be dozens of switches operating at layer 2 in the path. In the context of an end-to-end quality of service configuration, every single device in the path must be accounted for. This includes every router, every firewall, and every switch.
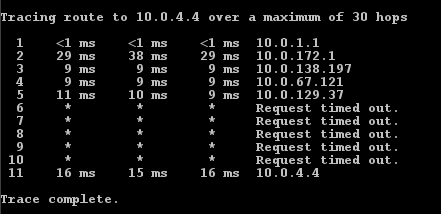 Traceroute is limited in its ability to find exactly where in the path VoIP communication is broken.
Traceroute is limited in its ability to find exactly where in the path VoIP communication is broken.
In spite of the limitations of traceroute, analyzing the complete path between endpoints is still the key to finding the cause of common VoIP issues, and this is where intelligent network mapping comes in. NetBrain’s platform is designed specifically to programmatically map a network — including paths between endpoints — and this is incredibly powerful for an engineer VoIP troubleshooting common issues.
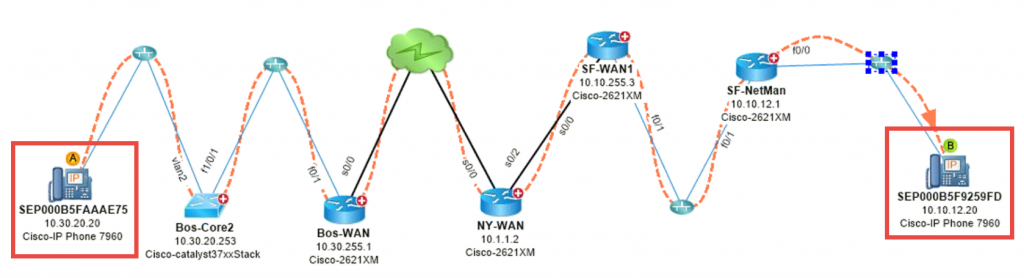 Analyzing the complete path between endpoints is the key to finding the cause of common VoIP issues.
Analyzing the complete path between endpoints is the key to finding the cause of common VoIP issues.
First, NetBrain’s Dynamic Maps create a real-time and interactive map of the network without having to crawl device to device using traceroute and show cdp neighbors. Very quickly you can discern what sorts of devices you’re contending with and where ACLs live, NAT is being performed, route redistribution is occurring, and so on.
In my experience, this may actually be enough to see where the trouble spots are. NAT, ACLs, and route redistribution have all been culprits to audio issues I’ve had to troubleshoot over the years. However, to focus on a specific audio flow, NetBrain’s A/B Path Calculator dynamically maps the actual path between endpoints. In the context of VoIP troubleshooting, this tool can save literally hours.
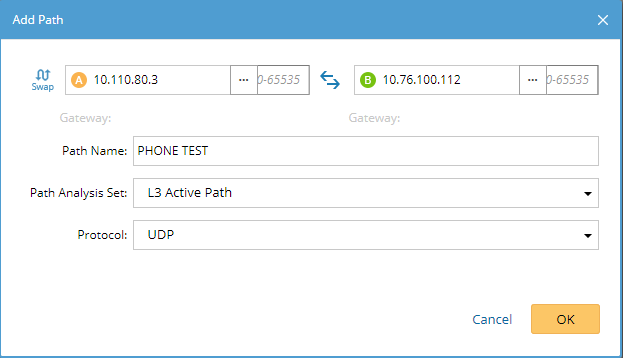 Just specify a source and destination address to dynamically map the actual path between endpoints.
Just specify a source and destination address to dynamically map the actual path between endpoints.
Using NetBrain’s A/B Path Calculator, you can specify the IP addresses of any two endpoints, whether to look at layer 2 or layer 3, and what protocol to analyze. For an audio test, enter the two phone IP addresses, select layer 3 to start, and select UDP from the protocol list. Within seconds you have the real-time path the devices are using in an interactive display. You can very quickly discern where ACLs are, what path RTP traffic is taking, and where the breakdown in the flow is occurring. This is an incredible step forward in VoIP troubleshooting compared with clumsily pinging around a network and using traceroute between devices.
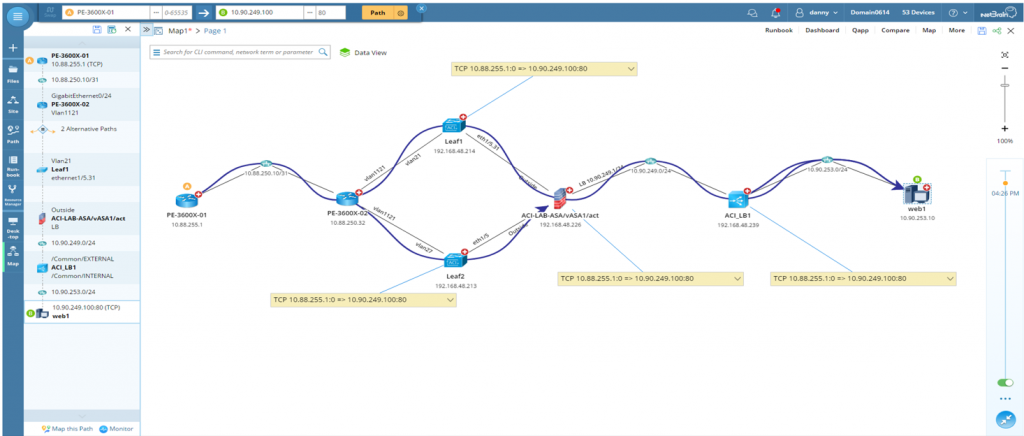 Within seconds, A Dynamic Map shows you ACLs, RTP traffic paths, and where the breakdown in the flow is occurring.
Within seconds, A Dynamic Map shows you ACLs, RTP traffic paths, and where the breakdown in the flow is occurring.
Another common cause for audio issues is poor link quality or low bandwidth links in the path between endpoints. This is why quality of service was developed — to queue, prioritize, and otherwise ensure certain traffic (typically voice) is given all the network resources it needs for a good end-user experience.
Because an audio stream uses UDP, it is inherently unreliable and has no error-checking mechanism to retransmit bad packets. Furthermore, if there is significant congestion on a link and no QoS configured to prioritize audio traffic, the end result will likely be very poor quality audio or calls dropped altogether.
The trouble with QoS is that it must be configured perfectly end-to-end in order to be effective.
But the trouble with QoS is that it must be configured perfectly end-to-end in order to be effective. Every access port used to originate voice traffic, every trunk port, and every layer 3 termination must have a consistent service policy. In a large network, this can be an enormous number of interfaces. Typically, that would mean first tracing the path between endpoints, and then logging into every single device to see if the QoS configuration is present and correct.
NetBrain also solves this problem programmatically by using built-in and customizable Qapps to pull information from all the network devices in the path and present an interactive map of relevant information such as QoS configuration on each device and actual queue drops indicating a problem with the policy.
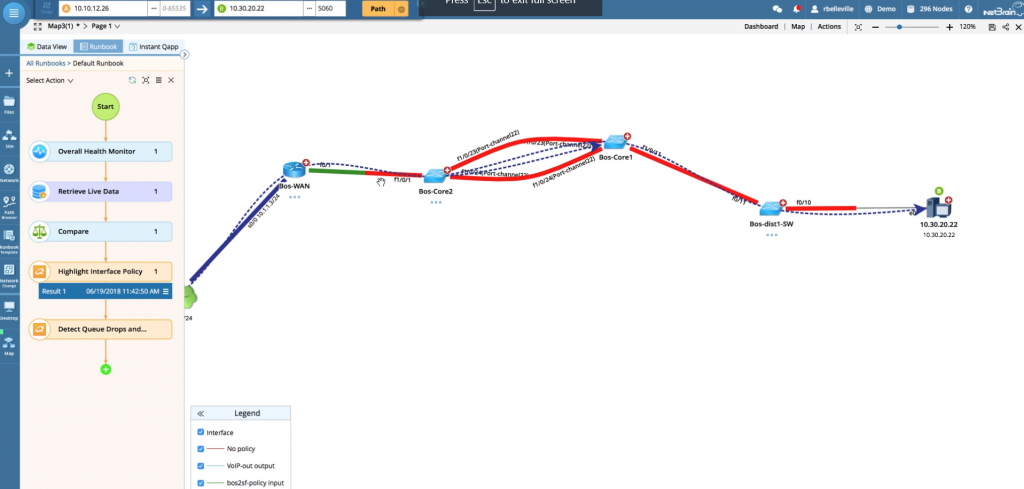 Automatically pull live data from every device along the path, highlight interface policy, and detect queue drops.
Automatically pull live data from every device along the path, highlight interface policy, and detect queue drops.
Being able to gather this information programmatically is what enables an engineer to resolve a VoIP issue quickly. Otherwise it takes an incredible amount of time to pull QoS information manually device by device.
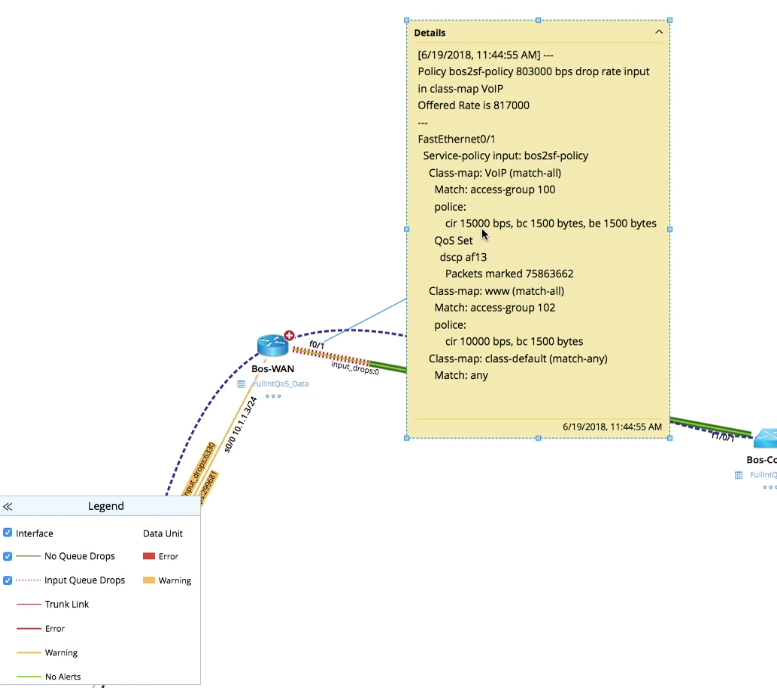 Getting this level of QoS information manually, device by device, would take an incredible amount of time.
Getting this level of QoS information manually, device by device, would take an incredible amount of time.
As much I hate to admit it, VoIP troubleshooting usually means solving a network problem. Until recently, engineers had to limp along with simple tools like traceroute to find the break in the network. However, with modern network programmability software such as NetBrain’s Dynamic Maps and A/B Path Calculator, VoIP troubleshooting one-way audio, poor call quality, call forwarding problems, and other common VoIP issues has become faster, easier, and with a much shorter time to resolution.