 by Mark Harris Oct 3, 2022
by Mark Harris Oct 3, 2022
Networks are the lifeblood of every modern business and by far the single largest capital asset owned by every organization. Network operations costs for “on-premise” equipment, even with the race to migrate applications to the public cloud, continues to rise. The long and short of this reality is for the foreseeable future, there is a bunch of equipment that is owned and operated by your organization, complimentary to the organization’s cloud strategy, that requires a ton of overhead spending to keep it all running (sometimes referred to as Day-2).
How can this be? Largely because network operations teams are still using the same tactical “device-level” approaches they have used for decades, and their “plan de jour” is reactive in nature, still managing boxes, not services.
So, after decades of trying to refine the means to manage IT infrastructures, adding expertise for new hardware and software as each came into play, and building expansive teams of highly skilled network engineers to deliver IT, the network operations teams are losing ground. The NetOps teams barely make it through each day by the skin of their teeth, addressing only the most urgent of problems, and rarely having a moment to look forward. And with economic pressures the way they are today, it’s a good reminder today that reacting to problems incurs far more network operations cost than preventing those problems from occurring in the first place.
How to Reduce the Network Operations Cost?
What we need is a means to proactively get in front of the NetOps turmoil. What we need is a way to proactively create, test, verify and preserve all the network conditions that must exist for mission-critical business services to deliver their function. What we need is the means to PROACTIVELY look at the entire network continuously and then identify discrepancies to be addressed before those issues affect production. This would be a fundamental way to change the DNA of the NetOps model.
Enter NetBrain Release 11, the industry’s only NetOps solution specifically designed to address the ‘new’ challenge and network operations cost structure of Day-2. (And for reference, “Day-2” refers to the period that starts when equipment or services are first commissioned and continues for many years in direct support of IT production services).
NetBrain Release 11 understands any network from end to end, all the way from your multi-cloud services, across the wide area, the data centers, and the branches. Literally, everything your teams use to deliver production IT services is part of NetBrain Release 11’s purview and it does so in real time so that business services can be verified while in motion.
NetBrain Release 11 also understands the requirements of the network, or “intents”, as defined by the hundreds or thousands of applications that are deployed. Each network intent specifies a desired level of connectivity; the required performance, the required security controls, and the complete set of diagnostics and expected results needed to evaluate in real-time if the connectivity is meeting the requirements of the business and its applications. And these intents can be numerous, typically numbering 10x or 100x the number of devices involved. A fair estimate for 1000 devices and a couple of cloud providers may yield 50,000 to 100,000 network intents.
So how do I get a compilation of 100,000 intents? NetBrain Release 11 includes the means to automatically generate the thousands of required foundational intents by leveraging the concept of “similar”. As an example, a pair of traffic management devices configured a mirroring configuration must remain synchronized, and the make or model of the device has little effect on what is required to assure synchronization. And intents can be generated by your subject matter experts or via the out-of-the-box Intent Library also provided by NetBrain. Intents are everything!
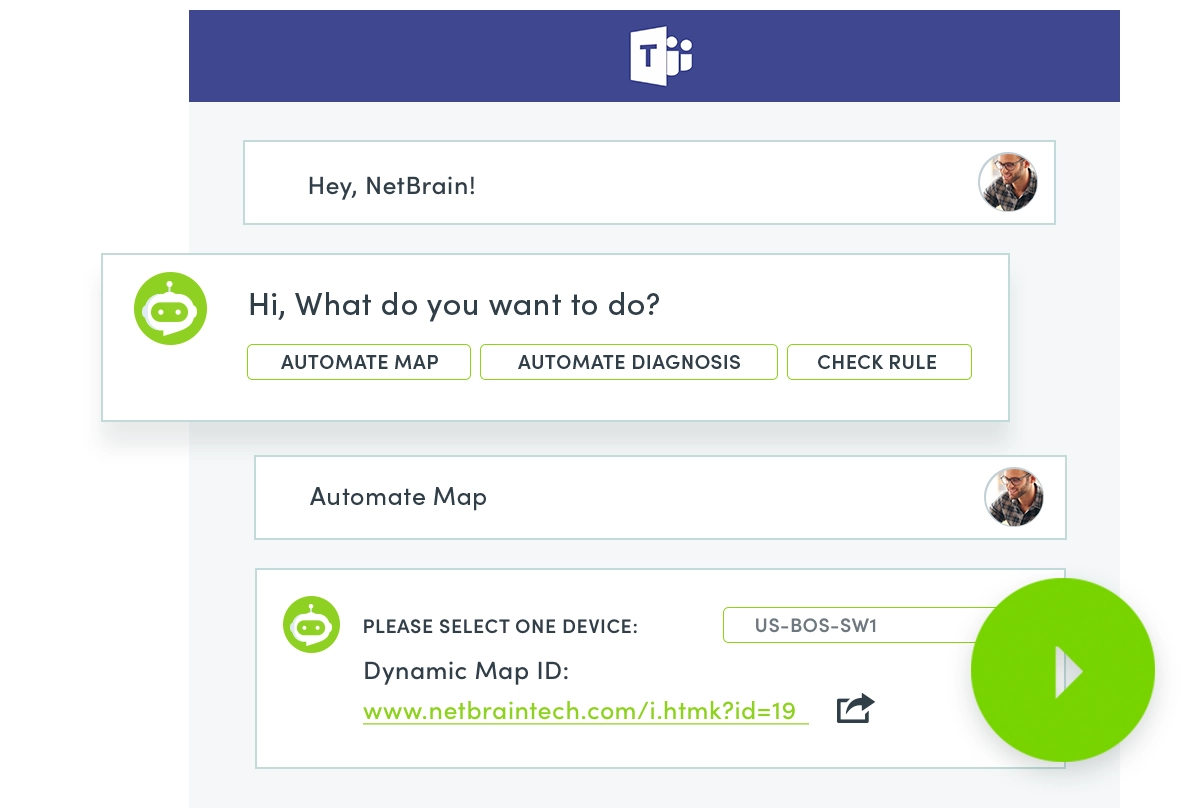
And one of my favorite new capabilities is NetBrain’s ability to offer access to its proactive troubleshooting through a number of interfaces, including direct connection to ITSM system, simple email conversations, and even using MS Teams Chat style inquiries. Imagine how fun it would be typing into Teams, “Hey NetBrain, what’s going on with my BGP tables”… and getting a response with all the details and diagnostics already executed and ready for you to review!
Yes, NetBrain is cool. But it’s also VERY cost-effective. It directly addresses the need to get in front of the NetOps curve, allowing predictable and defendable operations at scale and at a cost that is commensurate with the business itself. It makes your best engineers more effective and allows them to share their experience with their colleagues, eliminating much of the need for escalations. It proactively looks for problems before they cause dreaded outages and chaos and is one of the simplest solutions to address these challenging times when skilled resources are less available across the board.
It’s time for IT to step up, and get its network operations cost structure under control!