What are our biggest network automation challenges to network automation? I’m talking about today’s real-world networking — not challenges down the road. I’m talking about our current day-to-day operational workflows and tasks: troubleshooting, change management, security, and documentation in SDN, multi-cloud and hybrid networks.
There are two fundamental things that make network automation challenging. The first is the network itself. Networks today are really complex. We just got over virtualization, and then comes software-defined networks like Cisco ACI and now we have SD-WAN. The second thing is our tools and data. We use a lot of tools — ticketing systems like ServiceNow, 24×7 monitoring solutions, Splunk, SEIM and IDS, and even APM. Each tool does its own job but functions on an “island.” We wind up with a lot of data silos. So many tools with an abundance of data mean that automating troubleshooting or change management is not that straightforward.
That said, there are 5 “hidden” network automation challenges to everyday practical network automation that I’ve learned over the years.
The Human Dimension
When people hear “network automation,” they often have one of two reactions. Either they say, “It’s not worth it,” or they think “You’re trying to take away my job.” In the first case, network managers think they’ll spend a lot of money without getting much return on their investment. They don’t want to think about buying yet another solution, expend time finding a new way to do things or write another script. At the other end, some network engineers — usually the first-level NOC guys — hear “job elimination” when you say the word “automation.”
But automation is worth it and isn’t going to take away your job. It flips the equation on its head: automation takes away the jobs that aren’t worth it. Automation cannot — and will not — eliminate people’s work. But it does eliminate all the dead-end work that nobody wants to do. It frees up everyone’s time to take on more challenging work.
Scripts
In today’s networks, scripting isn’t enough. Anyone who’s written a Python or Java script knows that the biggest network automation challenge with scripts isn’t writing them. It’s maintaining them. You wrote a script once but then as the network changes, you’re stuck doing a lot of debugging. And sharing that script with other people isn’t so easy.
Even today you still hear a lot about how network guys need to become programmers. I don’t really see that it’s a natural move for us to go from network engineer to developer — or a solution for network automation.
When to push the button?
What do we mean, “When to push the button”? People think that with automation, we should write it once, push it out, and everything will take care of itself. But in the real world, it doesn’t work that way. Somebody somewhere has to trigger that piece of automation – for troubleshooting, change management, security, whatever. If there’s an outage in the middle of the night, who’s going to launch the automation that diagnoses the issue? And when? Today this is a big network automation challenge we need to solve.
Adapt to Hybrid Networks
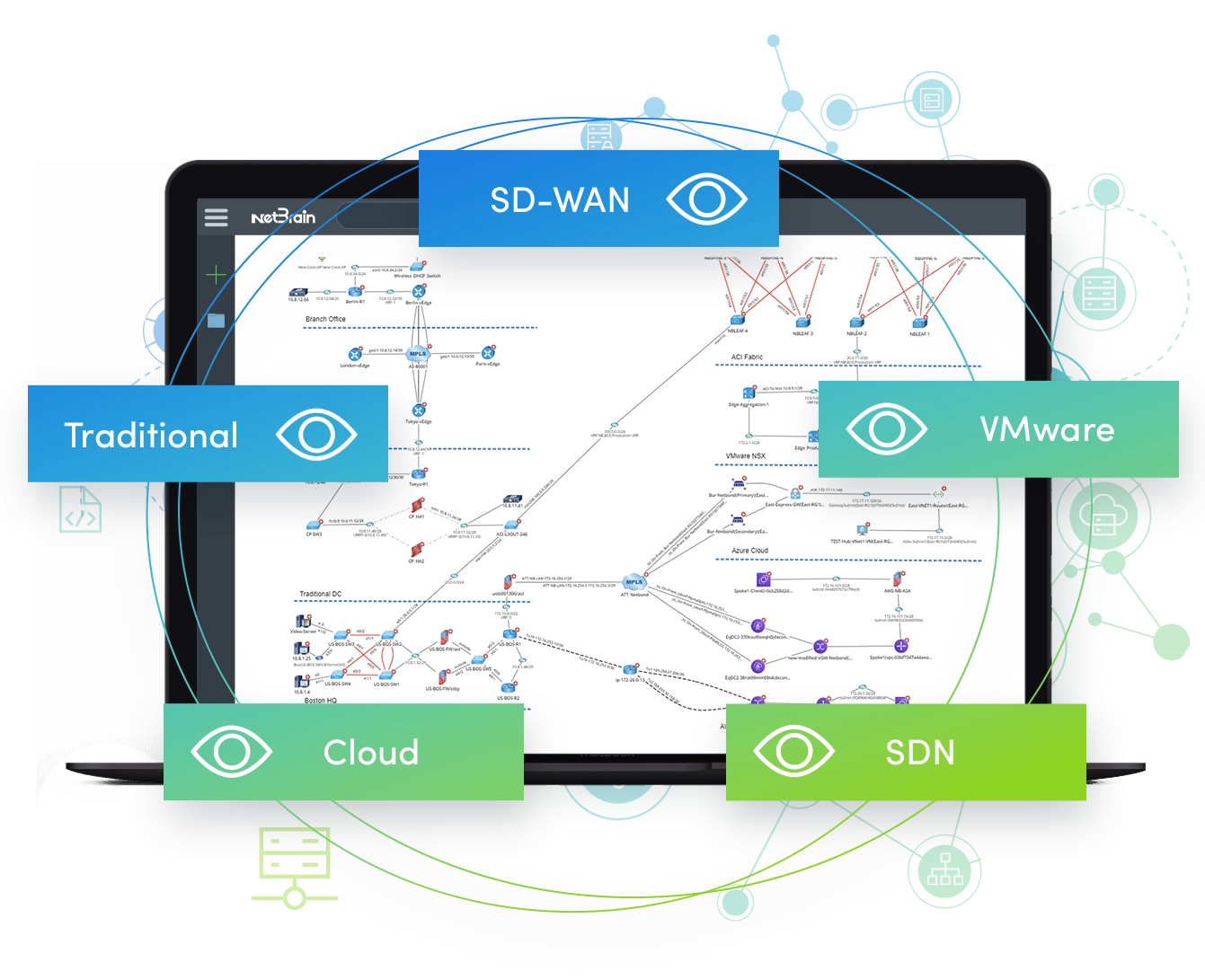
We are going to hybrid. Like it or not, there are more ACI, NSX and other SDN data centers coming. There’s more SD-WAN coming. The traditional network we’re familiar with, which we’ve just gotten our heads wrapped around, is not enough anymore. For most of the automation in a traditional network, do you “write it once, use it once”? That’s something we face all the time today. You might say, “Okay, we’ll separate the automation for the traditional network from the new network.” But what about traffic flow? If you have slowness going from your traditional network to your SDN, how do you deal with it? So we have to figure out how to automate within the hybrid network – same thing with a multi-vendor network.
We have a lot of tools – or solutions – already. But each tool is speaking its own language; they’re their own “data island.” You have a performance monitoring tool that doesn’t talk to the event management tool that doesn’t talk to the intrusion detection system, and so forth. All the important information you need – collectively — is isolated from each other in data silos.
So how do we overcome these challenges? We’ve tried upgrading the hardware, changing the software, replacing the people – those are not the solution. We need automation that thinks differently. We need Adaptive Automation.
Adaptive Automation
The concept of Adaptive Automation isn’t anything new. In the mechanical engineering field, there’s a computer-aided design (CAD) solution; the electronics industry has EDA (electronic design automation); in networking, there’s something similar: we call it Adaptive Automation. The idea behind it is that when you have a bunch of tasks that you have to perform in a complex network and that need to integrate different data islands, you need two things to solve the problem.
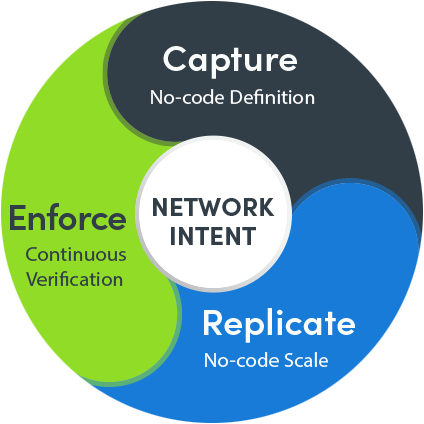
One is a map. In CAD or EDA, the diagram (or map) is really a data model that abstracts things in a visual format. So you need a map to be able to abstract your task. A map allows you to define the scope of your task.
The other piece of the puzzle is a runbook – not a script – that allows you to organize what you need to do. The runbook allows you to define the steps of your task.
Together, the map achieves the idea of documenting your network, creating a single pane of glass view of your network, and the runbook realizes “just in time” automation and “write once, execute everywhere” capability.
This Adaptive Automation addresses network automation one task at a time, one step at a time, for the 5 challenges above. Let’s look at an example of how this would look.
Troubleshooting Workflow under Adaptive Automation
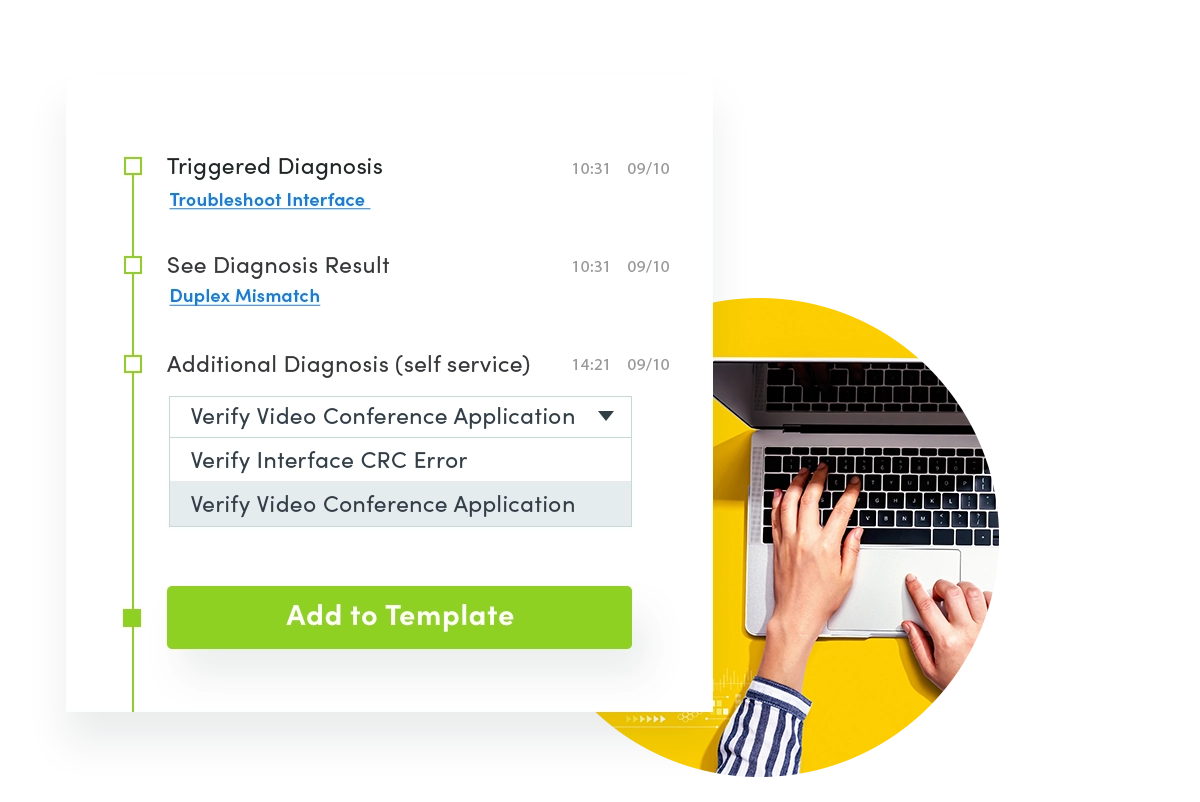
Say you receive a notification in your event console — a ticket in ServiceNow that an app is slow, for instance. In the Adaptive Automation framework, the first thing that happens is that “just in time” automation is triggered via API to create a Dynamic Map of that slowness. Then a “level-0 diagnosis” runbook automatically kicks into action to collect performance data, CLI command data, or data from your performance management tool and attach the information to the ServiceNow ticket. This all happens automatically the instant the event is created when the slowness is detected — in the middle of the night, say — without any human interaction required. (Which is why it’s referred to as “level-0 diagnosis.”) That’s step 1.
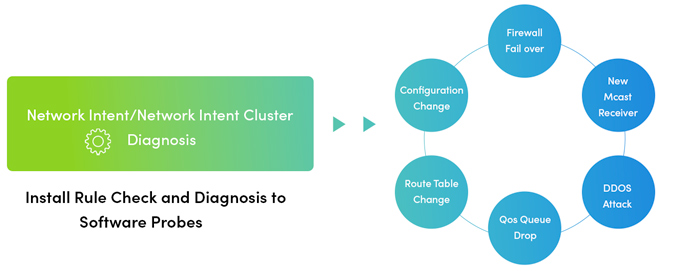
Step 2: In the morning when you arrive at work, there’s the ServiceNow that was created in the middle of the night. Now you run different slowness performance or QoS troubleshooting runbooks. These Runbooks were created by your senior network engineers based on their know-how, both their domain knowledge and subject matter expertise. If necessary, the Level 1 engineer can then escalate the issue to a Level 2 or 3 engineers. When the ticket gets escalated, everything the Level 1 engineer did is captured in the runbook so the next-level engineer doesn’t have to reinvent the wheel, re-running the same basic diagnoses. To dig deeper into the problem, you can leverage a single pane of glass to look at information from all the other tools (Splunk, log files, 24×7 performance monitoring solutions).
Once you’ve identified the problem — and this is what takes up about 80% of our troubleshooting time — you can fix the issue. Fixing things is pretty simple: maybe change QoS configuration, maybe reroute traffic. And you have an automation tool that can not only push out the changes but verify the impact of those changes automatically. This is actually more important that pushing the changes automatically.
Adaptive Automation then lets you proactively monitor for this problem moving forward so when it crops up again (and it probably will), you’ll capture it immediately without waiting for somebody to make a decision about how to address it. The steps your Level 2 engineer tool can be codified into a runbook that can be triggered to run automatically in 24×7 execution.
 by Jan 9, 2023
by Jan 9, 2023 