 by Mark Harris Mar 23, 2018
by Mark Harris Mar 23, 2018
The network is an essential part of retail success. Obviously, fast and reliable connectivity is life-or-death in the e-tail world. But it is equally critical for physical retail.
Network outages cause massive disruption and lost revenue for retailers — issues like losing access to credit card processing systems and a downed e-commerce site are just some of the results of a network outages — and consumers will not patiently wait for the problem to be fixed. They won’t necessarily complain; they’ll just move on to one of your competitors. Never to return.
“96% of dissatisfied customer don’t complain. But 91% of them simply leave and never come back.”
–1st Financial Training Services
While online and mobile commerce have forever changed our shopping experience, the U.S. Census Bureau finds that 91% of all retail sales still happen in brick-and-mortar stores. And according to the 2018 Retail Transformation Study, retail sales are expected to rise 6.2% across North America in 2018.
Yet today’s consumers have grown to expect an Amazon-like experience no matter where or how they’re shopping. Call it the digital transformation, omnichannel customer experience or getting “phygital” (the confluence of physical and digital), these increasingly demanding expectations have put enormous pressure on retail networking teams to keep systems up and running — and solve any network outages in record time.
Notable Retail Network Outages in 2017
We saw several retail network outages in 2017, some of the worst in Q4, when Black Friday, Cyber Monday and Christmas shoppers were ready, willing and able to make purchases but couldn’t. That’s a lot of revenue (not to mention reputation) going down the drain.
- Macy’s payment processing system crashed on Black Friday, one of the most (if not the most) important shopping days of the year. It was cash-only for in-store customers, who couldn’t pay using their credit or debit cards. Online customers were totally out of luck.
- The sheer volume of people activating their brand-new devices and opening accounts brought the entire Nintendo network down on Christmas Day. Most services were restored shortly, but the eShop remained offline for up to three days. Customers weren’t able to take advantage of post-Christmas eShop sales, and the launch of two Pokémon apps were tabled and missed their December 27 activation date.
- In May, a “technology update” brought down Starbucks’ cash register system for a couple of hours, affecting stores from Texas to Florida to California.
The Cost of Downtime
According to ITIC’s 2017 Reliability and Hourly Cost of Downtime Trends Survey, over 98% of large enterprises with more than 1,000 employees say that, on average, a single hour of downtime per year costs their company over $100,000, while 81% say it’s more than $300,000. Even more notable, 33% of enterprises indicate that hourly downtime costs their firms $1 million or more.
Of course, the cost of downtime can vary based on circumstances like company size and industry, but one thing we know for certain: unplanned downtime can cripple any business. This is especially true for retail companies that rely heavily on high-level data transactions to operate their businesses. For retailers, network outages during peak store hours or traffic time could mean millions lost and even cause business failure.
No organization is safe. Manual network design and configuration lends itself to basic human error that, unfortunately, can bring any system down. Layered onto that is the sensitivity of today’s networks. Modern networks are handling traffic levels unimaginable a decade ago, but they can also be undone by the slightest of missteps. In fact, we’ve seen the largest of networks such as AWS be taken down by a simple coding error. In AWS’s case, that outage reportedly cost companies $150 million.
How long does it typically take to restore service to users after network outages?
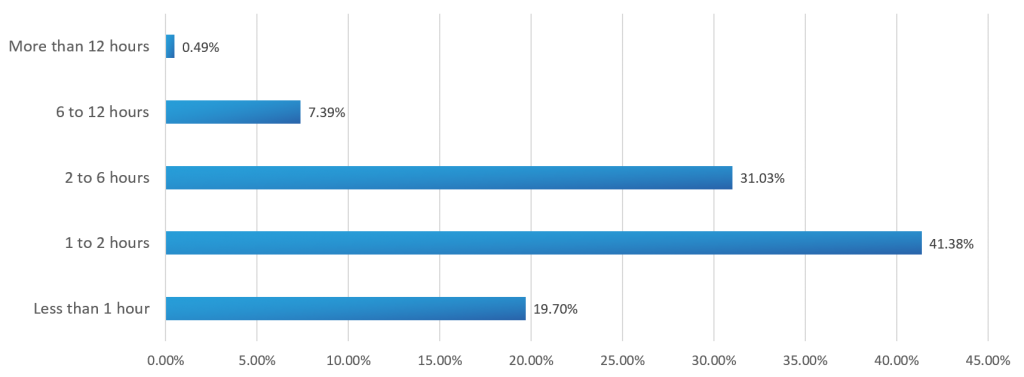
Source: 2017 State of the Network Engineer Report
Network downtime happens. Making changes to the network always introduces an element of risk. The volume, velocity and variety of changes to the network today only increases that risk. Most companies experience 4-5 network outages per year, with about 80% reporting that it usually takes longer than an hour to get back up and running.
Automation Is Key to Reducing MTTR
So, with the stakes so high, how can network engineers reduce network outages from hours (or days) to minutes?
By automating troubleshooting processes. Network troubleshooting remains a largely manual process. Whether it’s collecting and analyzing CLI data one command at a time, device by device, looking for the needle in a haystack; trying to pin down exactly how traffic is flowing through dynamic routing paths; or “reinventing the wheel” during escalation (each successive level of support repeating the same diagnoses), it takes engineers too much time to get the kind of end-to-end visibility they need to resolve issues before customers are affected.
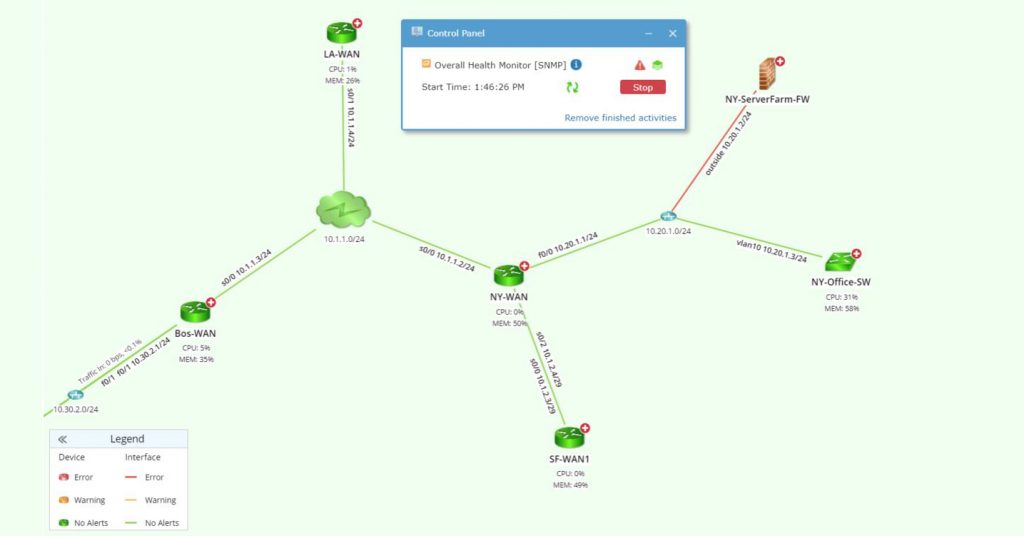
Automatically collect, analyze, and visualize CLI and SNMP data with automated diagnostics. Quickly identify a speed/duplex mismatch, increasing interface errors, duplicate OSPF IDs, or misconfigured AS numbers for a BGP neighbor connection.
Automation can reduce mean time to repair (MTTR) by expediting the collection, analysis and visualization of the problem at hand. For enterprise networks, Reducing Mean Time to Repair by even small increments can make a massive difference to an organization’s bottom line.
After all, every minute the network is down means revenue flying out the window.