10 Network Assessments for Outage Prevention
NetBrain offers a library of common enterprise network assessments as a foundation, while its no-code platform lets you customize and expand these templates to fit your unique environment. Results are easily visualized and shared through widget-based summary dashboards, empowering your team with real-time network insights.
Here are the leading network outage assessments that NetBrain handles in minutes.
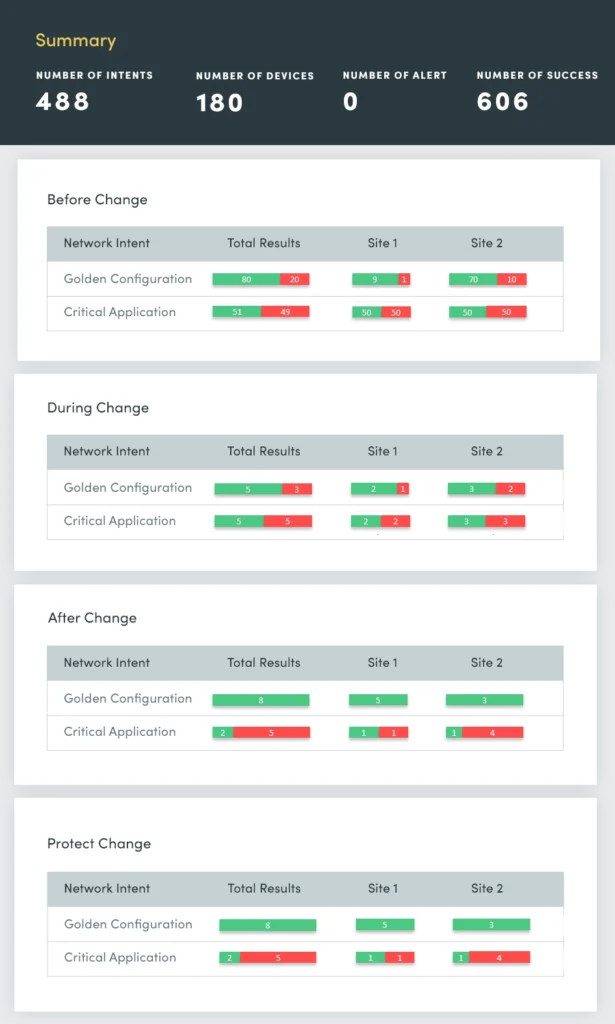
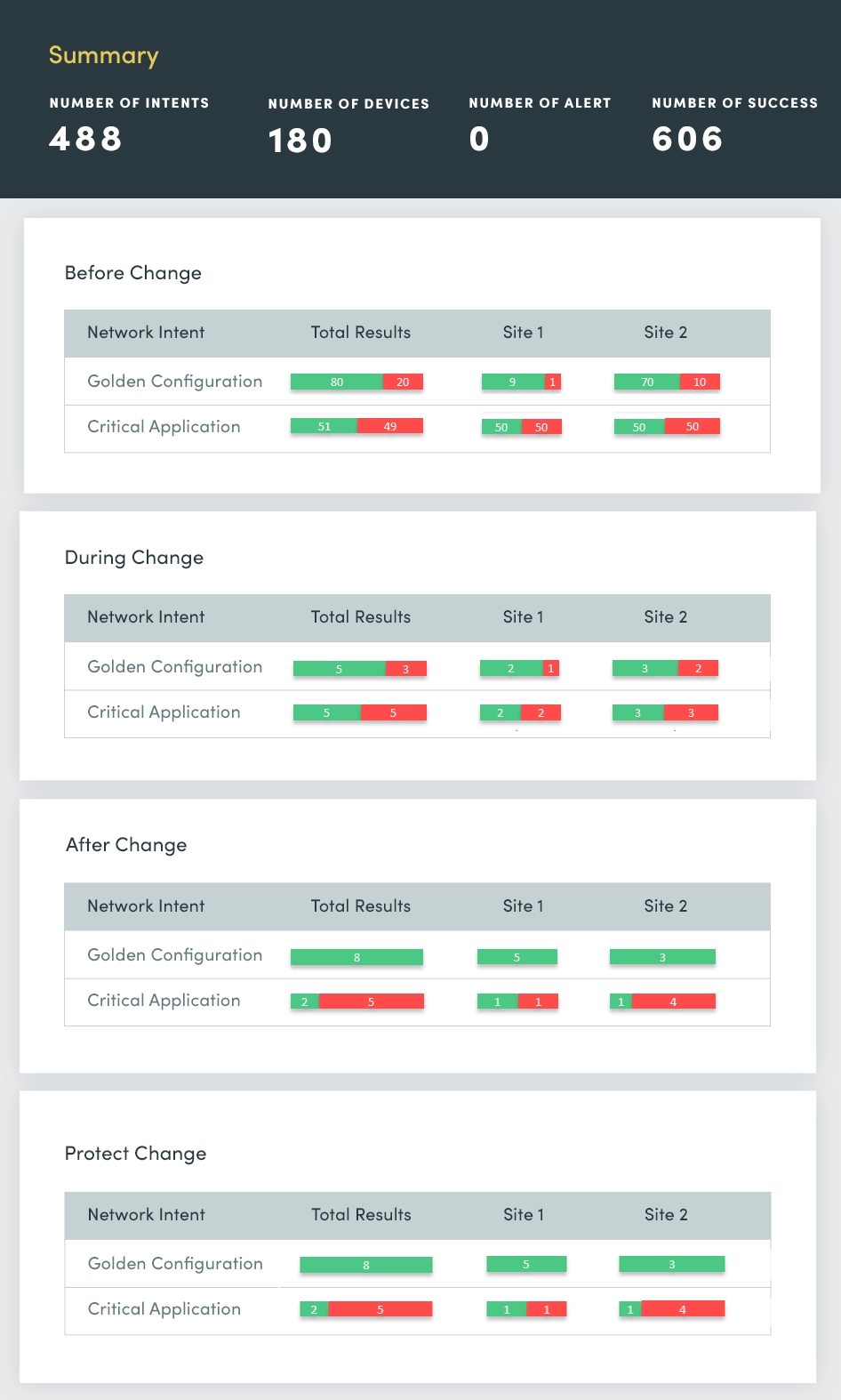
1. Change Assessment
At the start of every week, there are reports of network outages, triggering the question: What changed over the weekend, and where did these changes occur? You need to identify these network changes more rapidly and if they share a common origin so you can swiftly address and resolve them to ensure the network’s stability and minimize disruptions.
With a Change Assessment, you continuously evaluate and summarize:
- Device results by device group
- ACL configuration changes
- Routing configuration changes
- Switching configuration changes
- Failover configuration changes
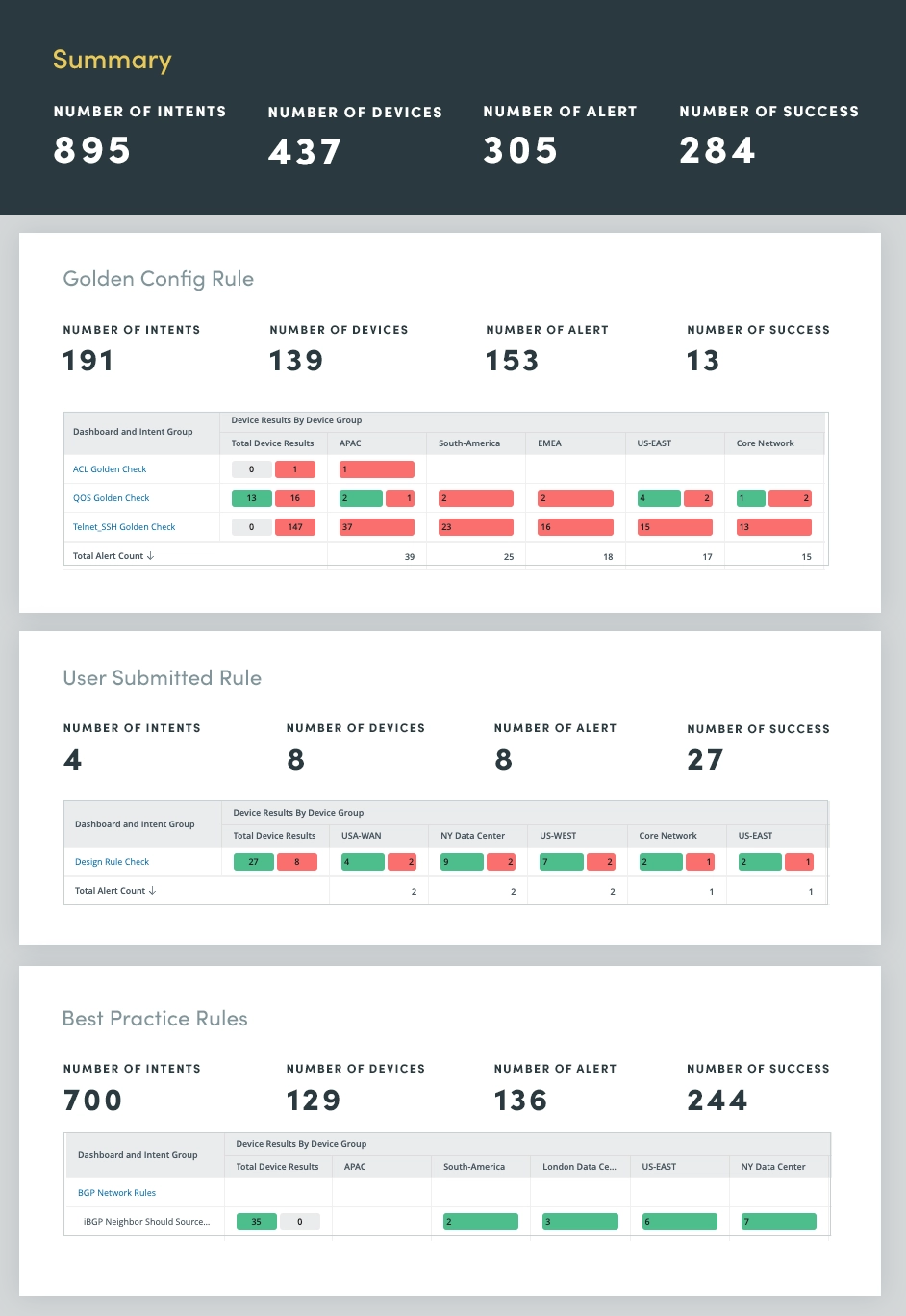
2. Anti-Drift Assessment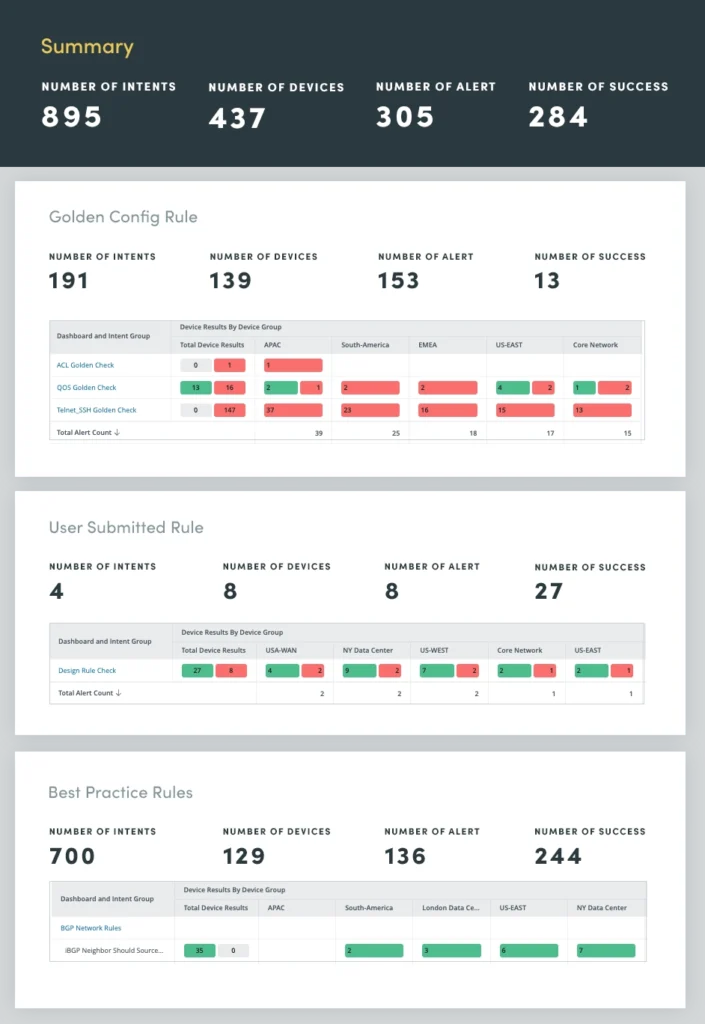
Human error, often stemming from manual network changes, is a leading cause of network outages. To address this, use a network Anti-Drift Assessment to identify deviations from established configuration rules and best practices. By automating the enforcement of these rules, you can significantly reduce the prevalence of human error and safeguard network stability.
The Anti-Drift Assessment encompasses three rule categories:
- Design and best practice rules: These rules outline industry-wide best practices for network configurations, ensuring that the network aligns with recognized standards and guidelines.
- Golden config rules: These rules represent the organization’s specific configuration standards, mandating adherence to internal policies and procedures.
- User-submitted design rules: These rules capture network architects’ and engineers’ expertise, encapsulating design principles and guidelines tailored to the organization’s unique network topology and requirements.
By automating the enforcement of these rules, you can effectively prevent configuration drift and minimize the risk of human error. This proactive approach not only enhances network stability but also improves overall network performance and security.
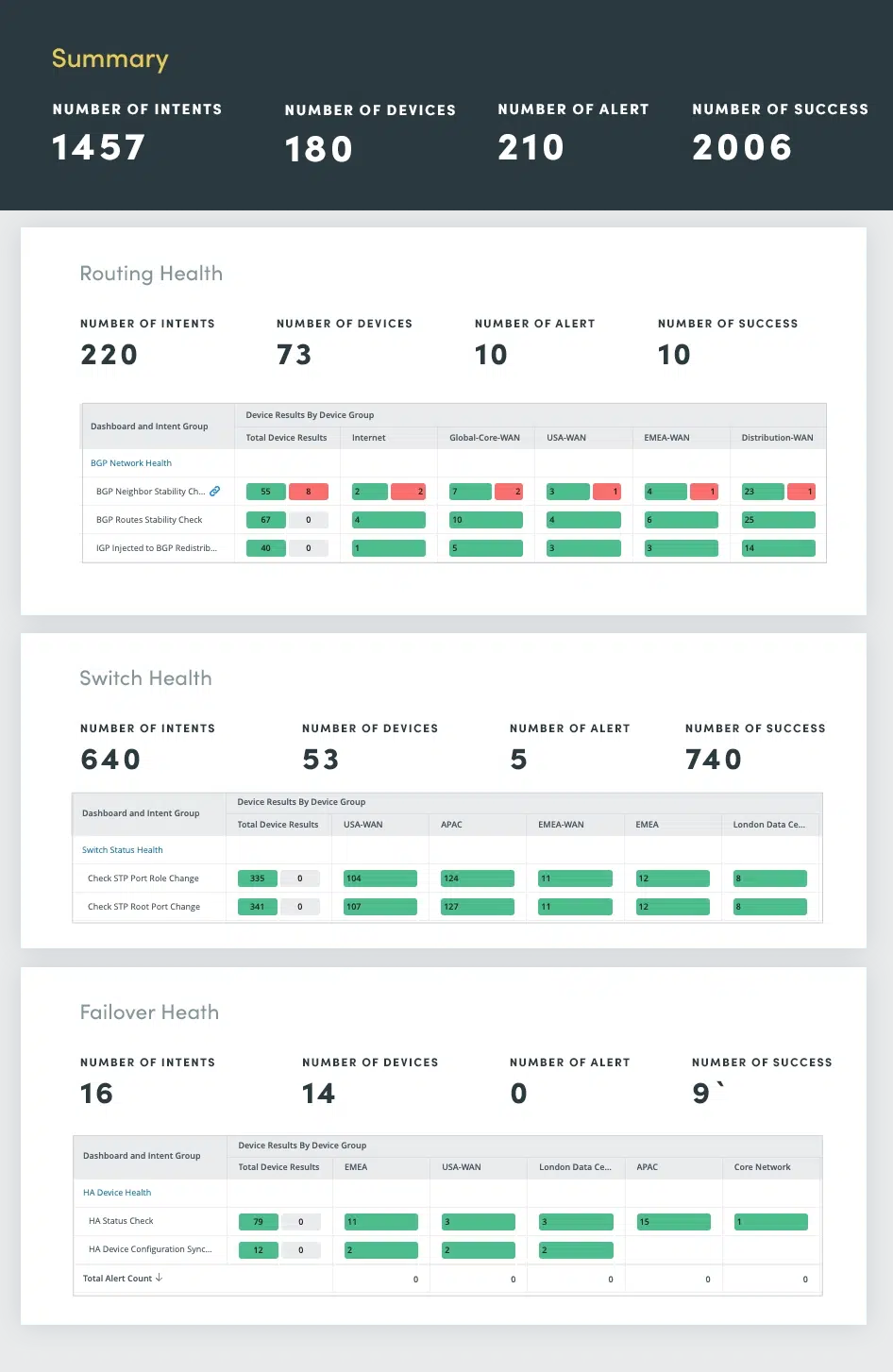
3. Network Health Assessment
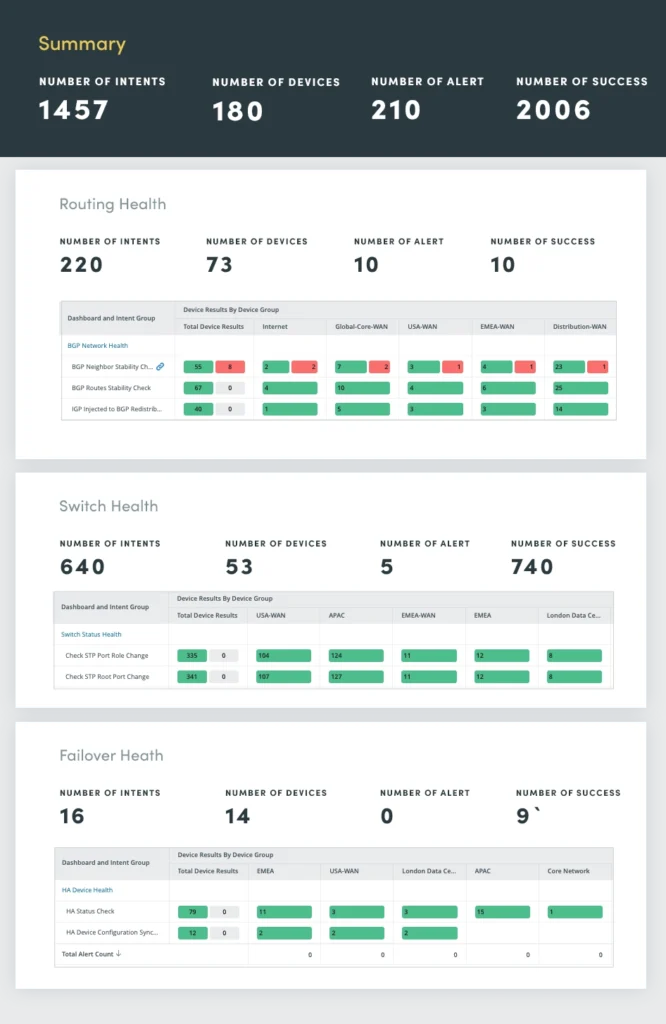
Sophisticated network redundancy provides reliable and high-performance connectivity. However, these features, if not properly monitored and maintained, can become sources of potential issues. Continuous network health assessment plays a critical role in identifying and addressing potential problems before they escalate into major outages.
Network health assessment encompasses a comprehensive evaluation of routing, switching, failover, VPN, wireless and error logs.
By continuously assessing these critical network components, you can proactively identify and resolve potential problems, ensuring optimal network performance, availability, and security.
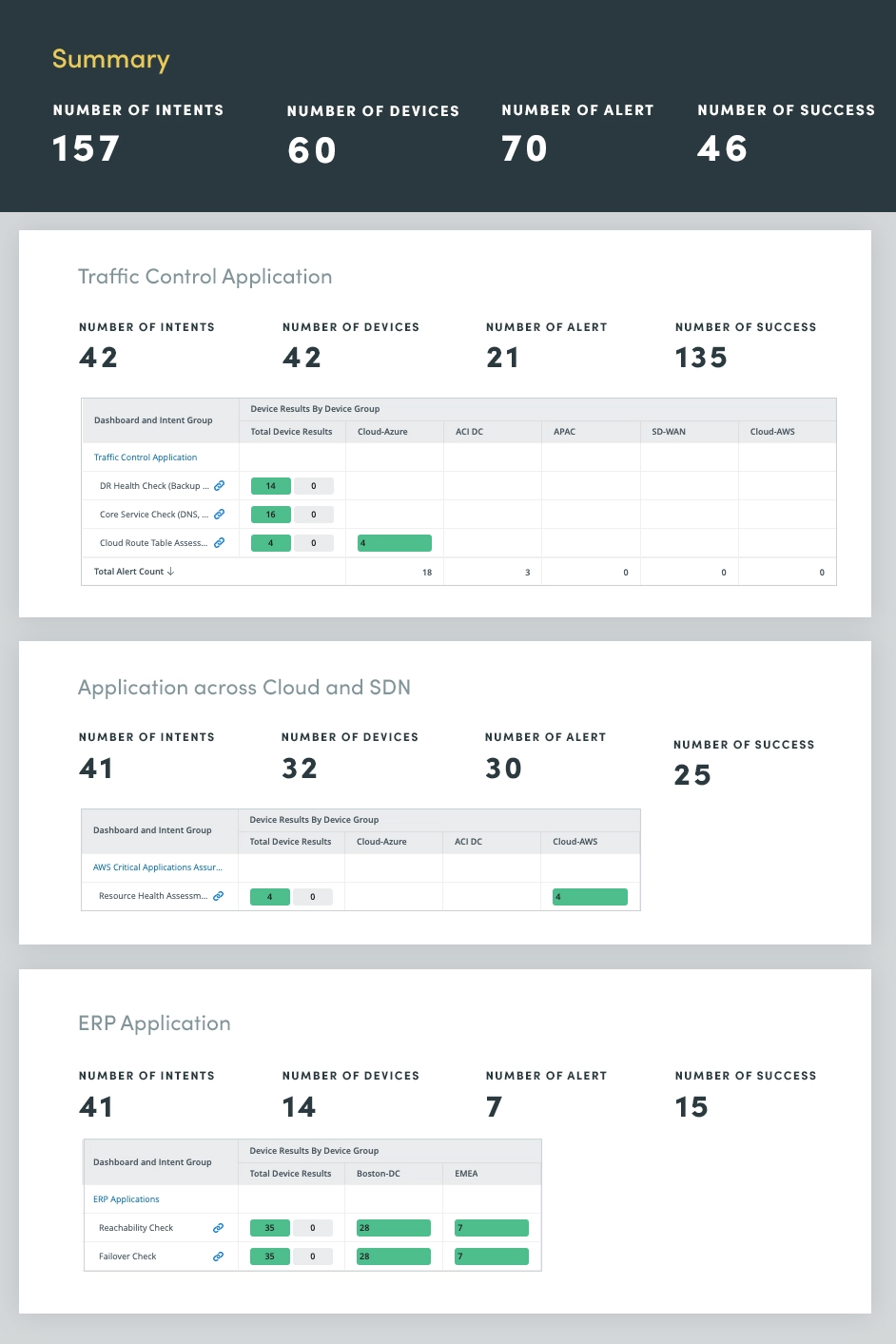
4. Critical Application Assessment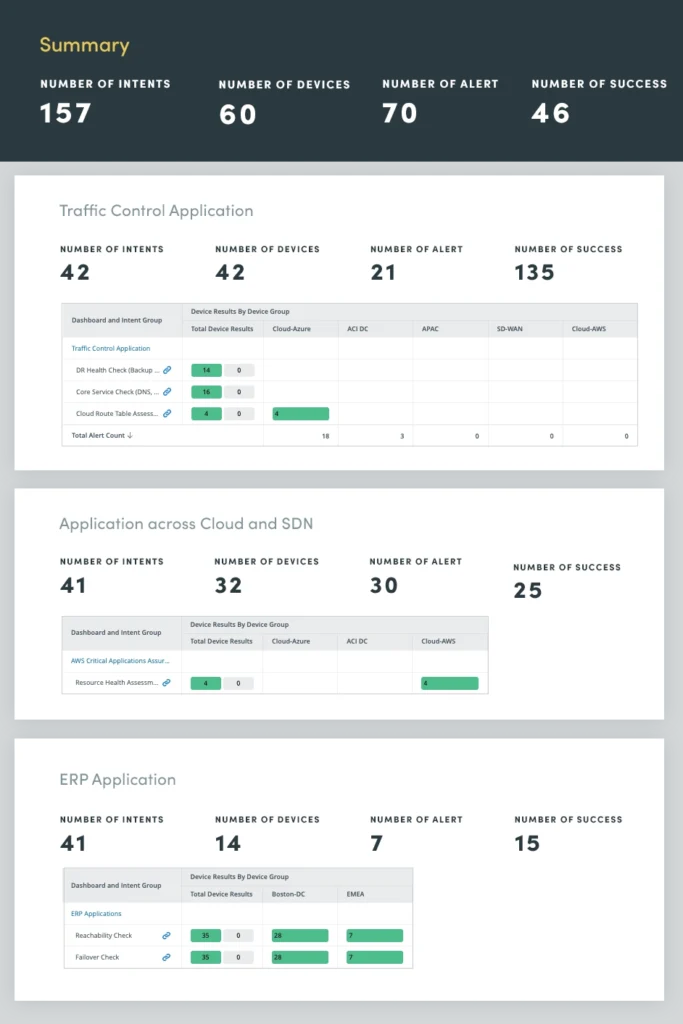
By continuously monitoring and evaluating the health of mission-critical applications, you can identify and address potential issues before they impact users or disrupt business processes. This proactive approach helps prevent costly outages, optimize application performance, and enhance overall system reliability.
Application health assessment encompasses a comprehensive evaluation of various application metrics and components, including CPU and memory capacity, QoS drops, critical interface utilization and tasks such as log analysis and event monitoring to proactively identify and address potential application issues.
By continuously assessing these critical application metrics, you can gain valuable insights into application health, enabling you to optimize performance, prevent outages, and maintain a positive user experience.
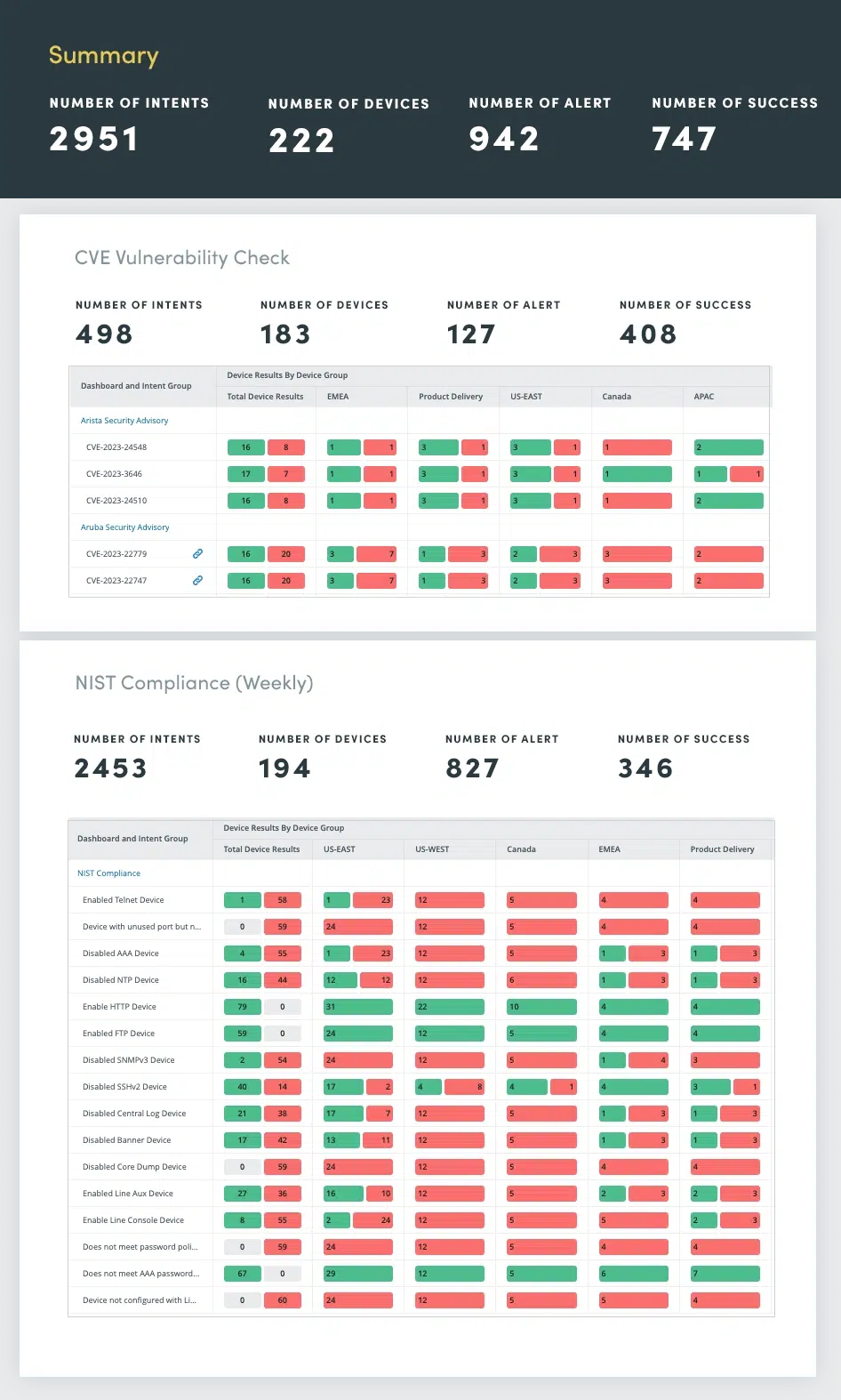
5. Security Assessment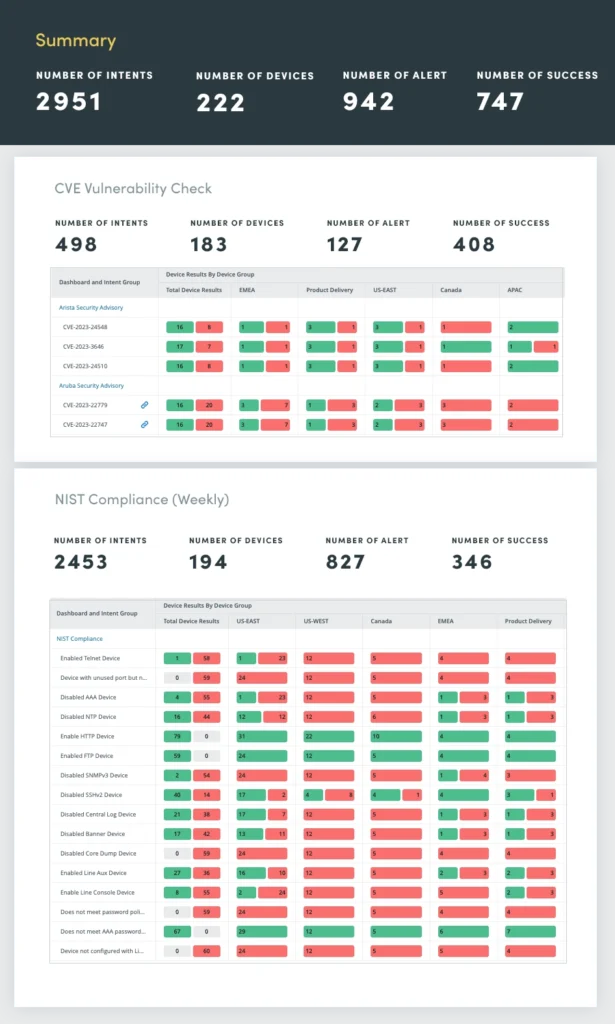
Ensure your network isn’t vulnerable according to the National Institute of Standards and Technology (NIST) and CVE Bulletins. From security compliance to vendor recommendations, assess any vulnerabilities and fix them before problems occur. Regular network security assessments are essential to identify and address vulnerabilities that could compromise sensitive data, disrupt operations, or damage an organization’s reputation.
Network security assessments encompass a comprehensive evaluation of various security aspects, including:
- Compliance with NIST and The North American Electric Reliability Corporation (NERC) Standards
- Vulnerability Detection using the Common Vulnerabilities and Exposures (CVE) catalog
- Misconfigurations that could create security gaps, such as weak passwords, insecure protocols, and unauthorized access permissions
- Intrusion Detection/Prevention (IDS/IPS): Analyze IDS/IPS logs
- Network traffic analysis: Monitor network traffic to detect anomalies that could indicate suspicious activity or network attacks
By automating these security assessments, you can continuously monitor network posture, proactively identify and address vulnerabilities, and maintain a robust defense against evolving cyber threats.
6. Lifecycle Assessment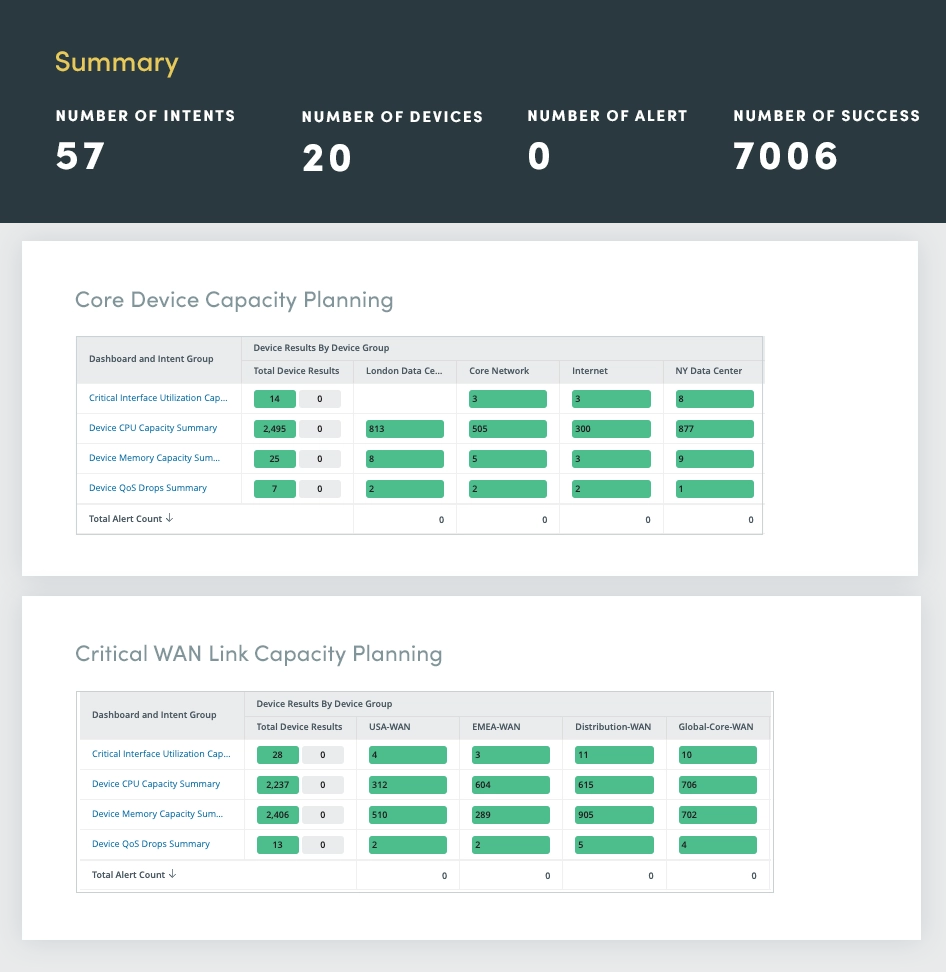
A comprehensive lifecycle assessment can help you stay informed about the lifecycle status of your network hardware, ensuring timely upgrades and replacement decisions.
By leveraging automated API calls to hardware vendors, such as Cisco, you can get real-time information on:
- End-of-Life (EOL) Status
- Maintenance Status:
- Service Contract Status
- Warranty Information
- Make informed decisions about hardware lifecycle management, optimizing their network for performance, security, and cost-effectiveness.
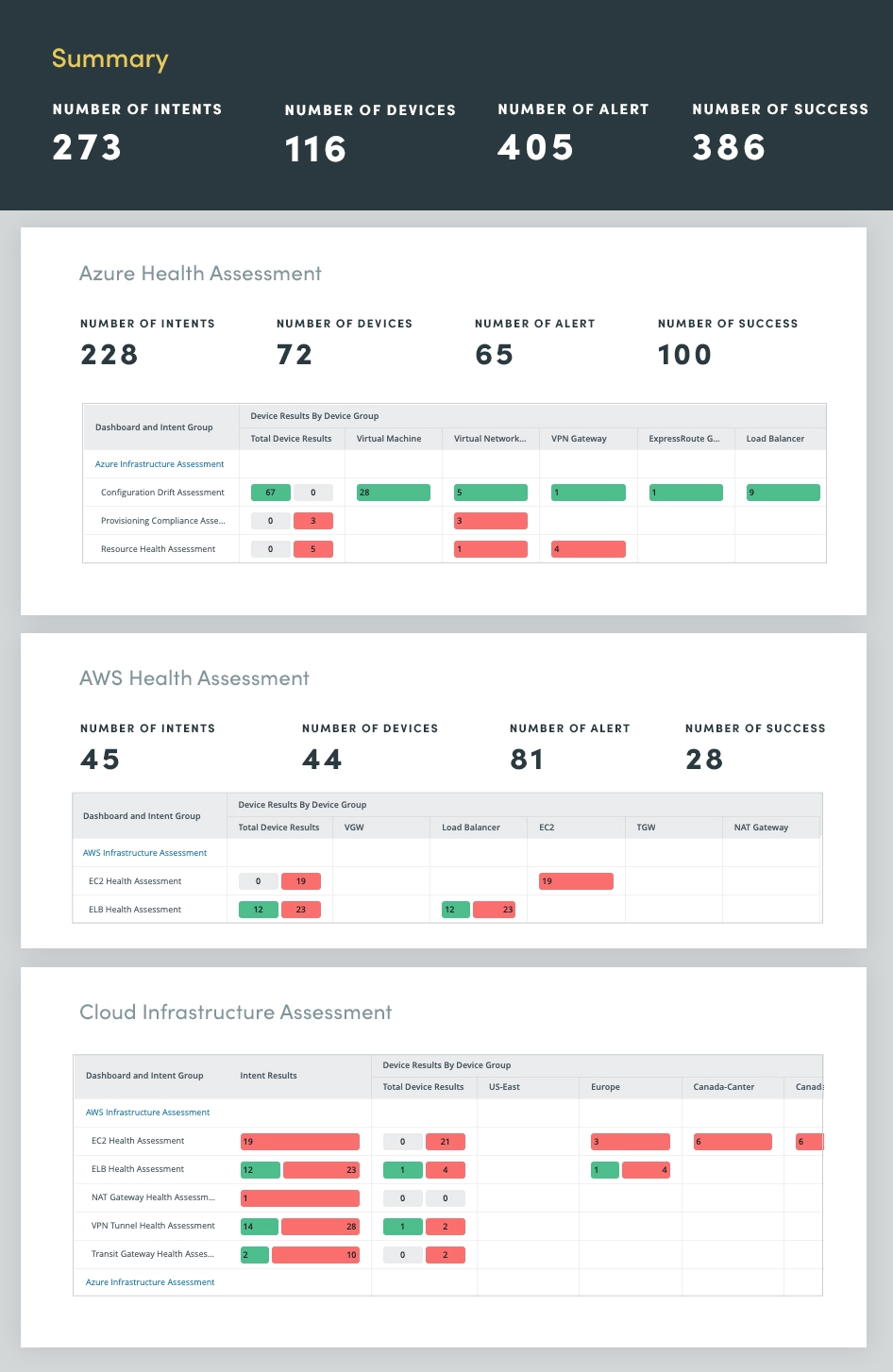
7. Hybrid-Cloud Network Assessment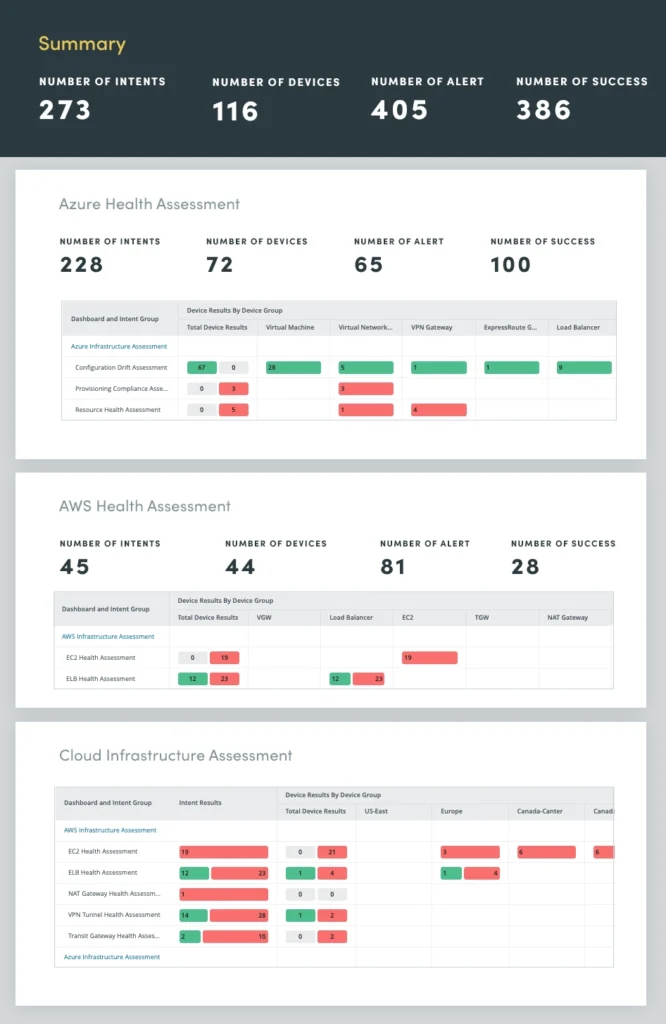
By applying automation to hybrid-cloud network assessment, you can continuously monitor and assess your cloud networks across multiple cloud providers, including Microsoft Azure, Amazon AWS, and Google Cloud for insights into:
- Network Resource Utilization
- Network Connectivity
- Virtual Appliance Health
- Cloud-Specific Metrics
By continuously assessing the hybrid-cloud network, proactively identify and address potential issues, optimize performance, and maintain a secure and resilient cloud infrastructure.
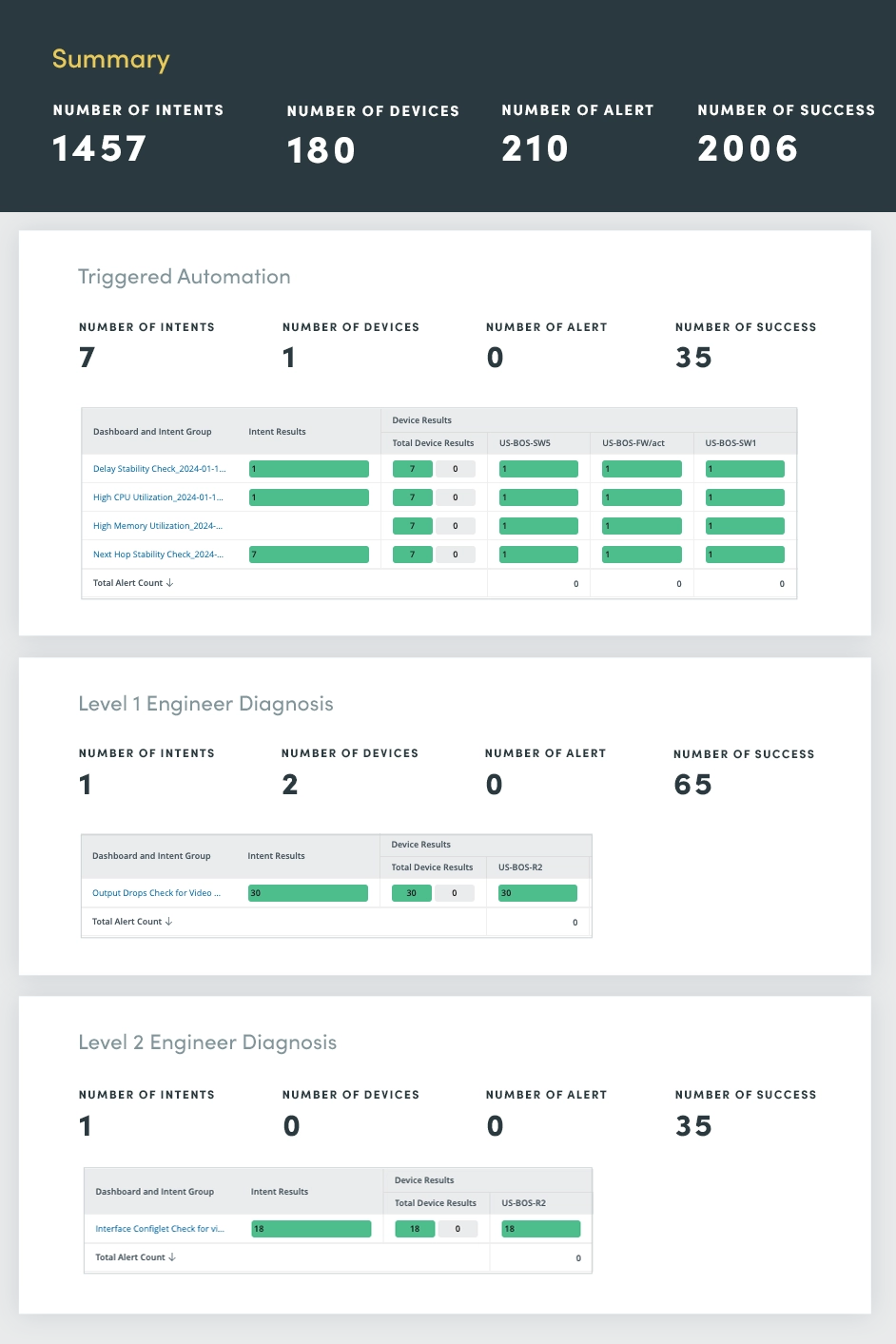
8. Triggered Automation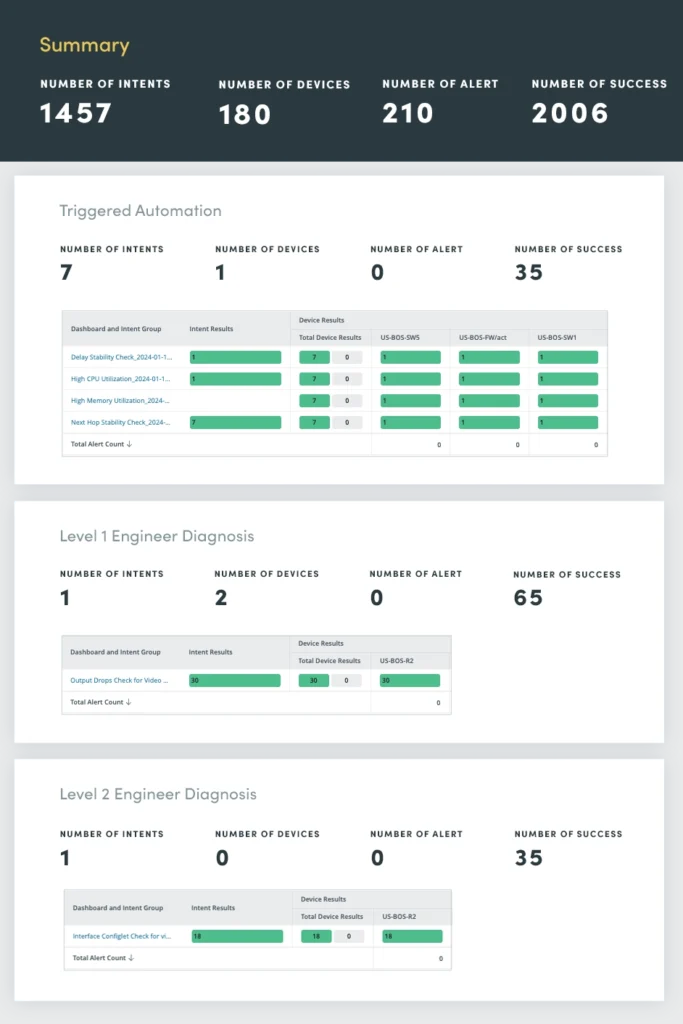
The Triggered Automation Assessment serves as a centralized hub for monitoring and responding to network incidents in real time. By harnessing the power of automation, streamline incident management processes, enabling rapid diagnosis, prioritization, and resolution.
Upon receiving an incoming incident notification via API, the triggered automation dashboard applies intelligent auto-diagnosis capabilities:
- Auto-closing ticket: If the incident is identified as noise, the ticket is automatically closed, reducing the workload for network engineers and eliminating unnecessary escalations.
- Auto-opening ticket: In cases where a network issue is found, automatically open a ticket, ensuring that the incident is promptly addressed and documented.
- Auto-prioritizing ticket: If a high-impact issue is found, automatically assign the ticket to a high priority, alerting network engineers to the urgency of the situation and enabling rapid intervention.
Automating these critical incident management tasks significantly reduces response times, minimizes downtime, and enhances overall network resilience.
9. Past Outages Assessment
After an outage, evaluating whether similar problems exist elsewhere in your network is critical. Consider if it could happen again in a different location or under varying conditions for every known issue. A problem-based assessment — applied broadly and monitored continuously — helps surface these risks. To truly reduce future downtime, teams must go beyond root cause analysis. They must proactively search for patterns, reinforce weak points, and use those insights to strengthen the network against repeat failures.
By analyzing past outages, organizations can:
- Identify recurring patterns and underlying factors that contribute to network outages, allowing for targeted mitigation strategies.
- Uncover hidden vulnerabilities or misconfigurations that may have been overlooked during initial assessments, preventing future outages.
- Implement preventive measures and strengthen network infrastructure resiliency to reduce reoccurrence.
By proactively addressing past issues and learning from them, you can significantly enhance network resilience and minimize your outage risk.
10. Capacity Assessment
Continuous capacity assessment helps prevent overutilization and underutilization by analyzing real-time traffic patterns, resource consumption, and performance metrics. This proactive approach provides visibility to anticipate demand, optimize network performance, and maintain seamless business operations.
Enable proactive planning and scaling strategies by anticipating future capacity needs to avoid costly reactive measures by monitoring these key metrics:
- Bandwidth utilization: Monitors the percentage of available bandwidth being consumed, indicating potential congestion points.
- Device resource utilization: Tracks the utilization of CPU, memory, and other resources on network devices, identifying potential bottlenecks.
- Application performance metrics: Evaluate the performance of critical applications under varying network conditions, highlighting potential capacity constraints.
Make more informed decisions to optimize performance and ensure scalability.
Prevent Network Outages with NetBrain
No-code network automation is transforming the traditional network assessment from an outdated audit-related task to a strategic, real-time operational tool that empowers operations teams every day. Proactively assess network performance with automated diagnostics and insights, enabling you to identify and address potential issues before they impact business operations.
Ready to start building a more resilient network? Schedule a demo today to explore how NetBrain can help your team prevent outages.
 by
by