Los 5 mejores tickets de soporte de red para automatizar
¿Qué es lo que más te frustra del soporte de red? Nada se siente mejor que jugar al detective en un problema de red oscuro y ser el héroe de TI que lo resuelve. Pero demasiado...

El tiempo de inactividad es caro. Más de la mitad (54%) de los encuestados sobre centros de datos de Uptime Institute de 2023 dicen que su interrupción significativa, grave o grave más reciente costó más de $100,000 16, y el 1% dijo que su interrupción más reciente costó más de $XNUMX millón.
La frase de la película Apolo 13, “El fracaso no es una opción”, es uno de los eslóganes cinematográficos más reconocibles de todos los tiempos.

En las operaciones de red, se aplica la misma mentalidad. El dinero y la reputación están en juego. El fracaso no es una opción.
Los datos del Uptime Institute sugieren que cada año hay, en promedio, de 10 a 20 interrupciones de TI o eventos de centros de datos de alto perfil en todo el mundo que causan pérdidas financieras graves o graves, interrupciones en los negocios y los clientes, pérdida de reputación y, en casos extremos, pérdida de vida.
Entonces, ¿por qué seguimos siendo tan vulnerables dadas todas las redes de redundancia que tienen incorporadas? ¿Por qué seguimos dependiendo tanto de los procesos manuales y la resolución de problemas reactiva? Los ingenieros de redes dedican incontables horas a establecer las bases para la prestación de servicios, pero la aplicación regular es escasa o nula. Sólo cuando se informa de un problema, se ponen en marcha (lentamente) los mecanismos de resolución de problemas.
La respuesta es: que no estamos siendo proactivo suficiente. Esto se debe a una falta de atención a la industria de la automatización de redes. Dejamos que los mismos problemas sigan sucediendo una y otra vez cuando sabemos cómo resolverlos porque simplemente carecemos de los mecanismos para aprovechar y aplicar este conocimiento automáticamente a través de redes híbridas.
Una importante interrupción impulsa el cambio en Saudi Telecom (stc)
En 2021, una aplicación crítica en stc sufrió una importante interrupción del servicio. Fue necesario casi un mes de resolución de problemas en operaciones de red, servidores, aplicaciones y equipos de seguridad para identificar la causa y restaurar el servicio. Esta costosa interrupción puso de relieve la necesidad de una mejor visibilidad y un enfoque más estratégico para la gestión de incidentes. Como resultado, el CTO del grupo stc presionó por una solución para toda la organización que proporcione visibilidad de extremo a extremo y automatice la gestión de incidentes en toda la infraestructura y aplicaciones.
Imagine capturar la experiencia de sus ingenieros y aplicarla de forma proactiva en toda su red sin codificación. La automatización de la red está ayudando a que las operaciones de la red reaccionen más rápido, pero no ha avanzado lo suficiente (alerta de spoiler: hasta hoy) para aplicar ese conocimiento en toda la red de manera proactiva y sencilla. ¿Qué pasaría si pudiéramos aprovechar el vasto conocimiento de nuestros ingenieros de redes y almacenarlo para utilizarlo en una plataforma de automatización?
Cada día, los equipos de operaciones de red evaluar la red para detectar desviaciones, cumplimiento, estado y cambios manualmente. ¿Qué pasaría si los ingenieros pudieran realizar estas evaluaciones periódicamente con la ayuda de la automatización?
La automatización de redes ahora ha avanzado rápidamente para poder evaluar continuamente las condiciones operativas de una red sin ningún ciclo de desarrollo. NetBrain ha creado un conjunto de las evaluaciones más comunes que requieren las operaciones de redes empresariales para garantizar operaciones resistentes a interrupciones. Sin embargo, la plataforma de automatización sin código garantiza que las operaciones de la red no se limiten a un conjunto finito de evaluaciones. Sin agregar recursos, puede desarrollar fácilmente estas plantillas y crear su sistema de evaluaciones continuas para sus necesidades específicas de red. Y tu puedes visualizar y compartir resultados de evaluación en toda la red a través de paneles de resumen basados en widgets.
Exploremos las 10 principales evaluaciones de red para prevenir interrupciones y veamos cómo NetBrain Puede elaborarlos en minutos.
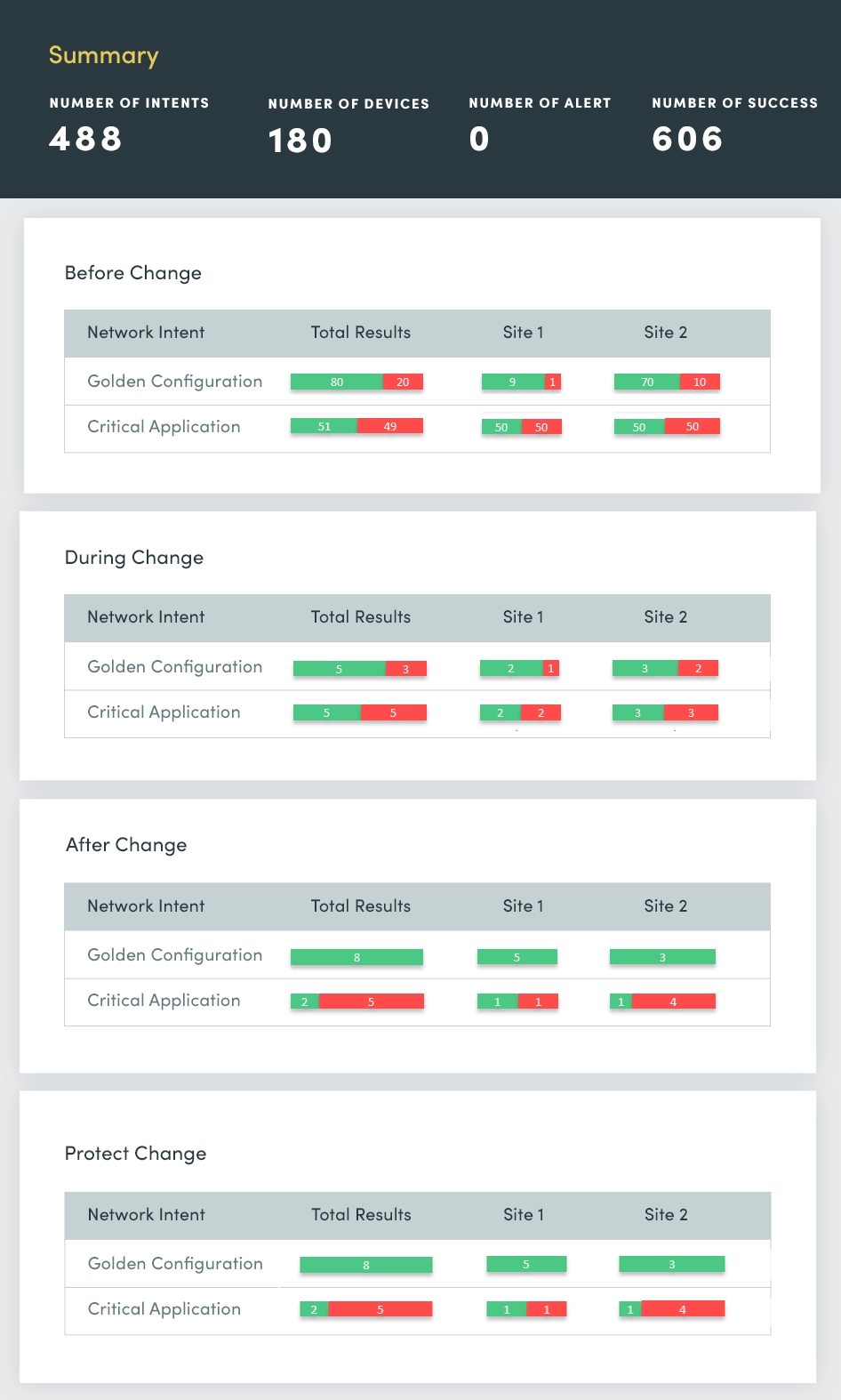
Al comienzo de cada semana, hay informes de cortes de red que generan la pregunta: ¿Qué cambió durante el fin de semana y dónde ocurrieron estos cambios? Debe identificar estos cambios de red más rápidamente y si comparten un origen común para poder abordarlos y resolverlos rápidamente para garantizar la estabilidad de la red y minimizar las interrupciones.
Con una Evaluación de Cambios, usted evalúa y resume continuamente:
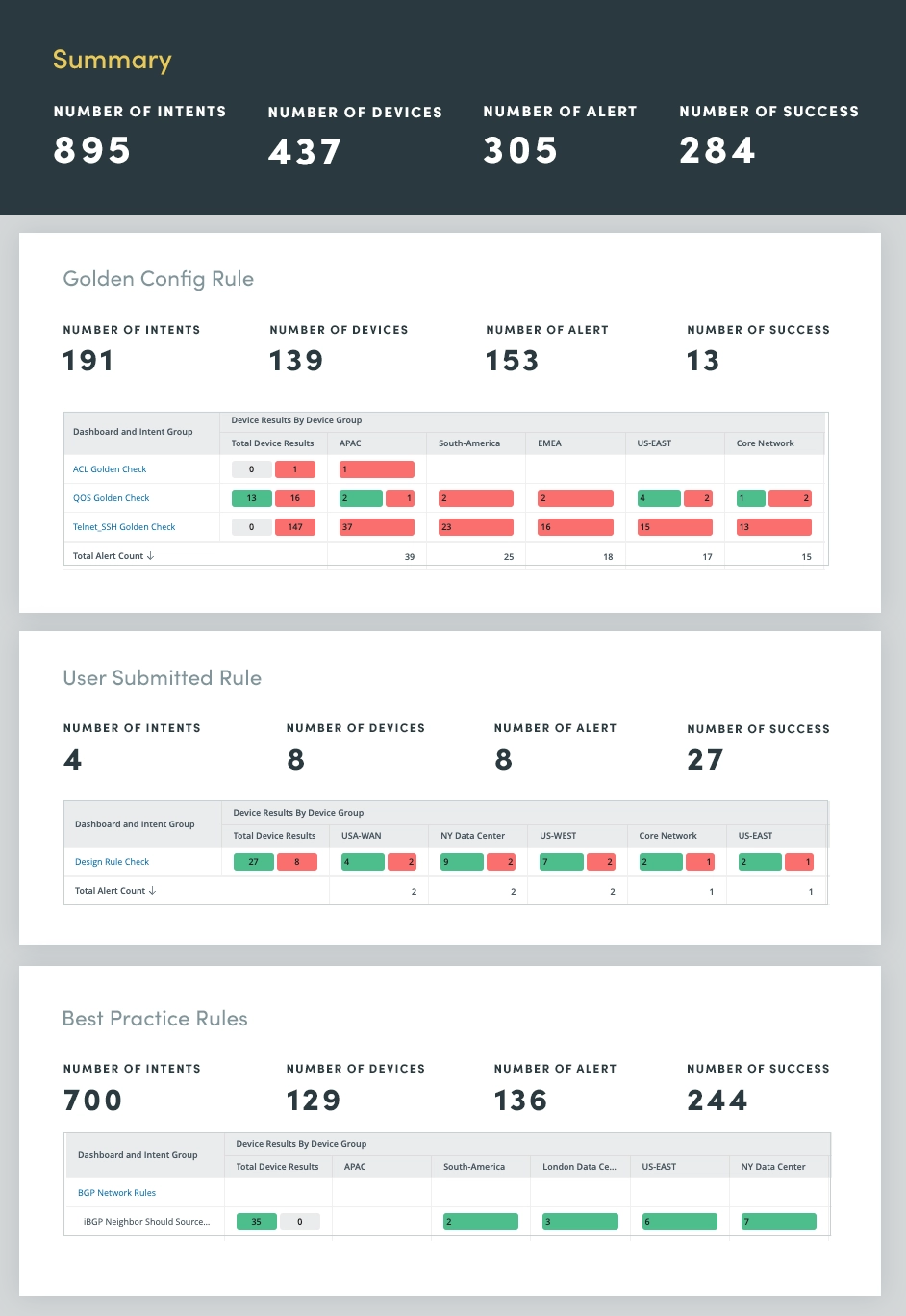
El error humano, que a menudo surge de cambios manuales en la red, es una de las principales causas de interrupciones de la red. Para solucionar este problema, utilice una evaluación antideriva de la red para identificar desviaciones de las reglas de configuración y mejores prácticas establecidas. Al automatizar la aplicación de estas reglas, puede reducir significativamente la prevalencia de errores humanos y salvaguardar la estabilidad de la red.
La Evaluación Anti-deriva abarca tres categorías de reglas:
Al automatizar la aplicación de estas reglas, puede prevenir eficazmente la desviación de la configuración y minimizar el riesgo de error humano. Este enfoque proactivo no sólo mejora la estabilidad de la red sino que también mejora el rendimiento y la seguridad general de la red.
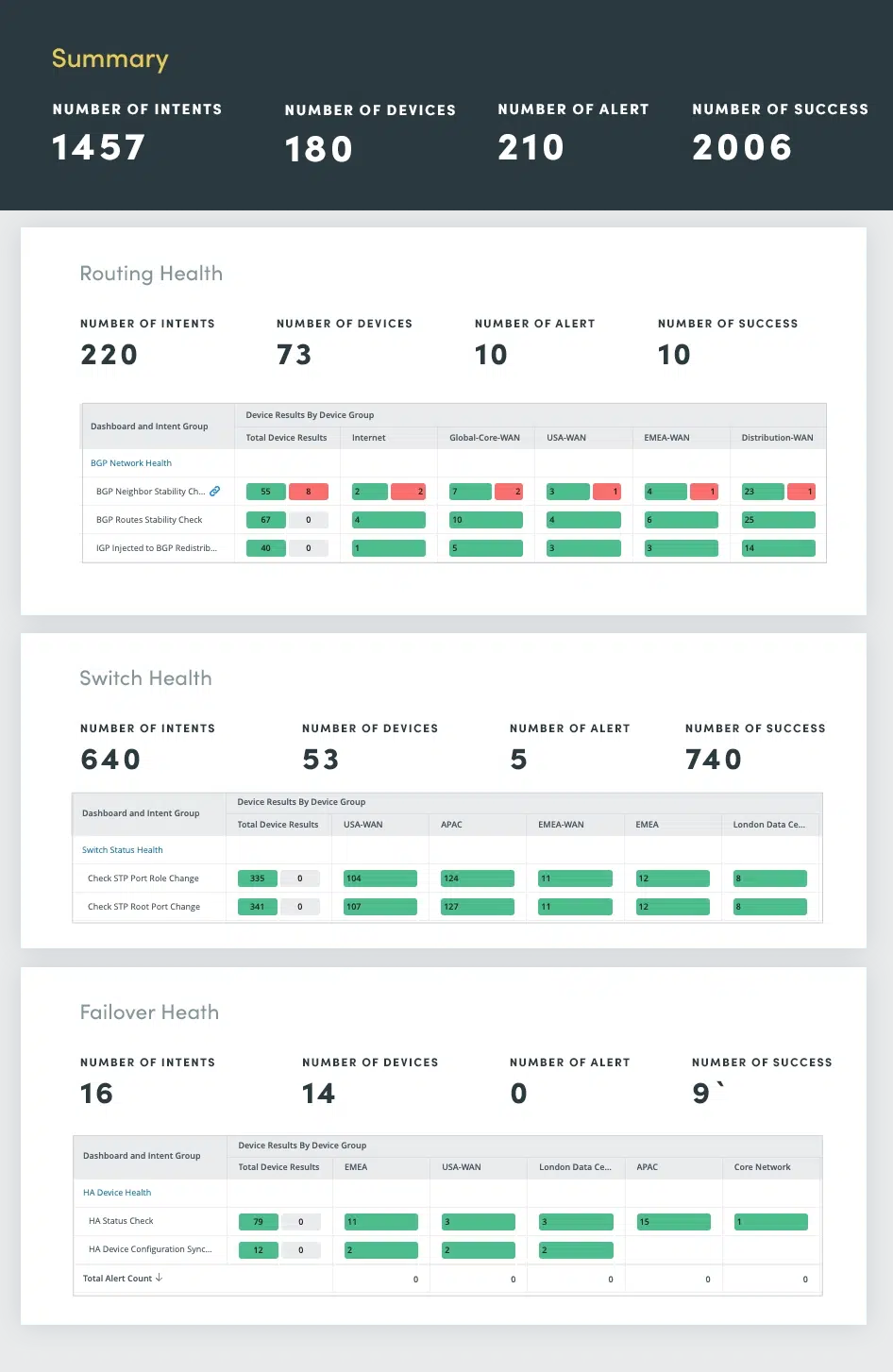
La sofisticada redundancia de red proporciona una conectividad confiable y de alto rendimiento. Sin embargo, estas características, si no se monitorean y mantienen adecuadamente, pueden convertirse en fuentes de problemas potenciales. La evaluación continua del estado de la red desempeña un papel fundamental a la hora de identificar y abordar problemas potenciales antes de que se conviertan en interrupciones importantes.
La evaluación del estado de la red abarca una evaluación integral de enrutamiento, conmutación, conmutación por error, VPN, conexión inalámbrica y registros de errores.
Al evaluar continuamente estos componentes críticos de la red, puede identificar y resolver problemas potenciales de manera proactiva, garantizando un rendimiento, disponibilidad y seguridad óptimos de la red.
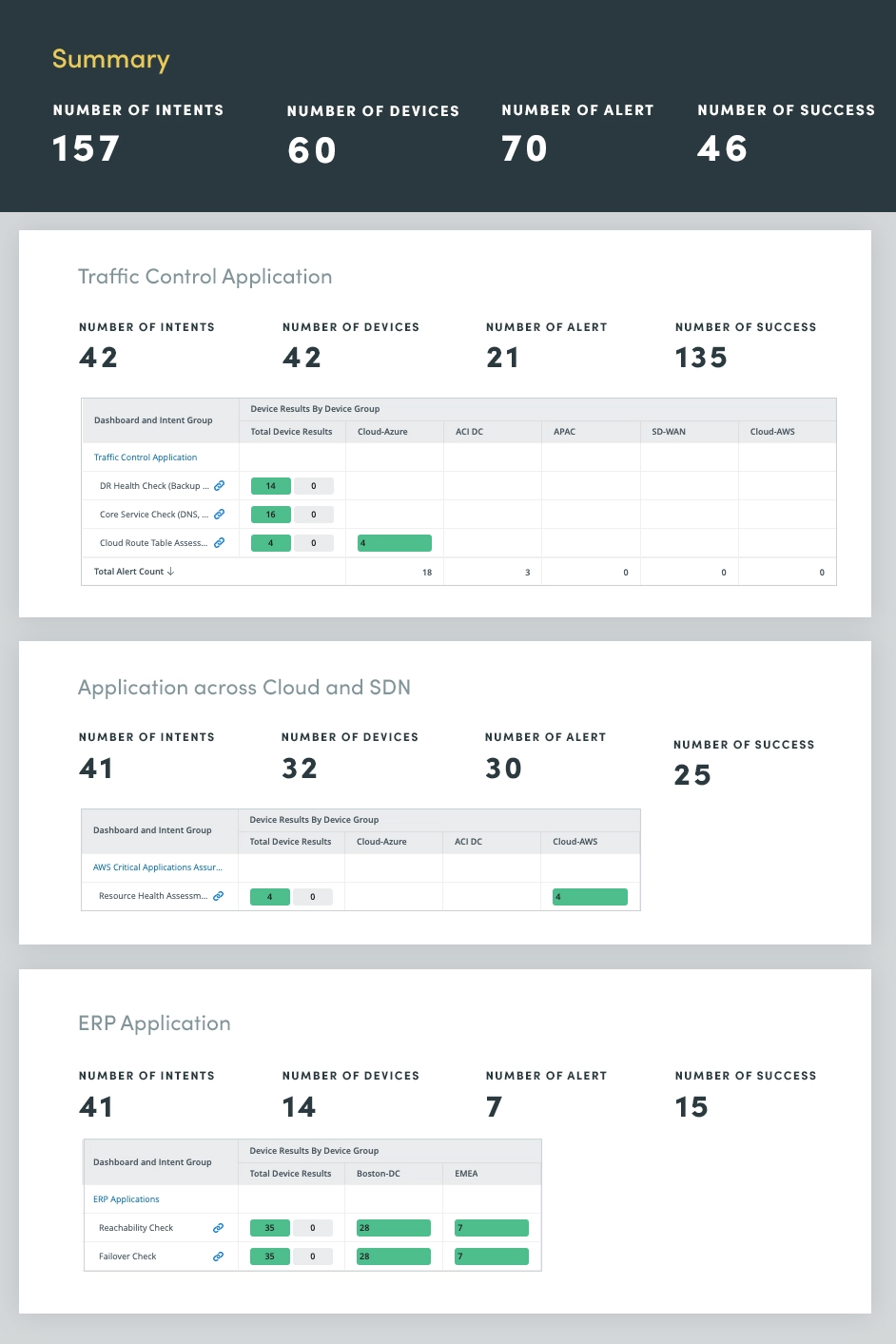
Al monitorear y evaluar continuamente el estado de las aplicaciones de misión crítica, puede identificar y abordar problemas potenciales antes de que afecten a los usuarios o interrumpan los procesos comerciales. Este enfoque proactivo ayuda a evitar costosas interrupciones, optimizar el rendimiento de las aplicaciones y mejorar la confiabilidad general del sistema.
La evaluación del estado de la aplicación abarca una evaluación integral de varias métricas y componentes de la aplicación, incluida la capacidad de la CPU y la memoria, las caídas de QoS, la utilización de la interfaz crítica y tareas como el análisis de registros y el monitoreo de eventos para identificar y abordar de manera proactiva posibles problemas de la aplicación.
Al evaluar continuamente estas métricas críticas de las aplicaciones, puede obtener información valiosa sobre el estado de las aplicaciones, lo que le permitirá optimizar el rendimiento, evitar interrupciones y mantener una experiencia de usuario positiva.
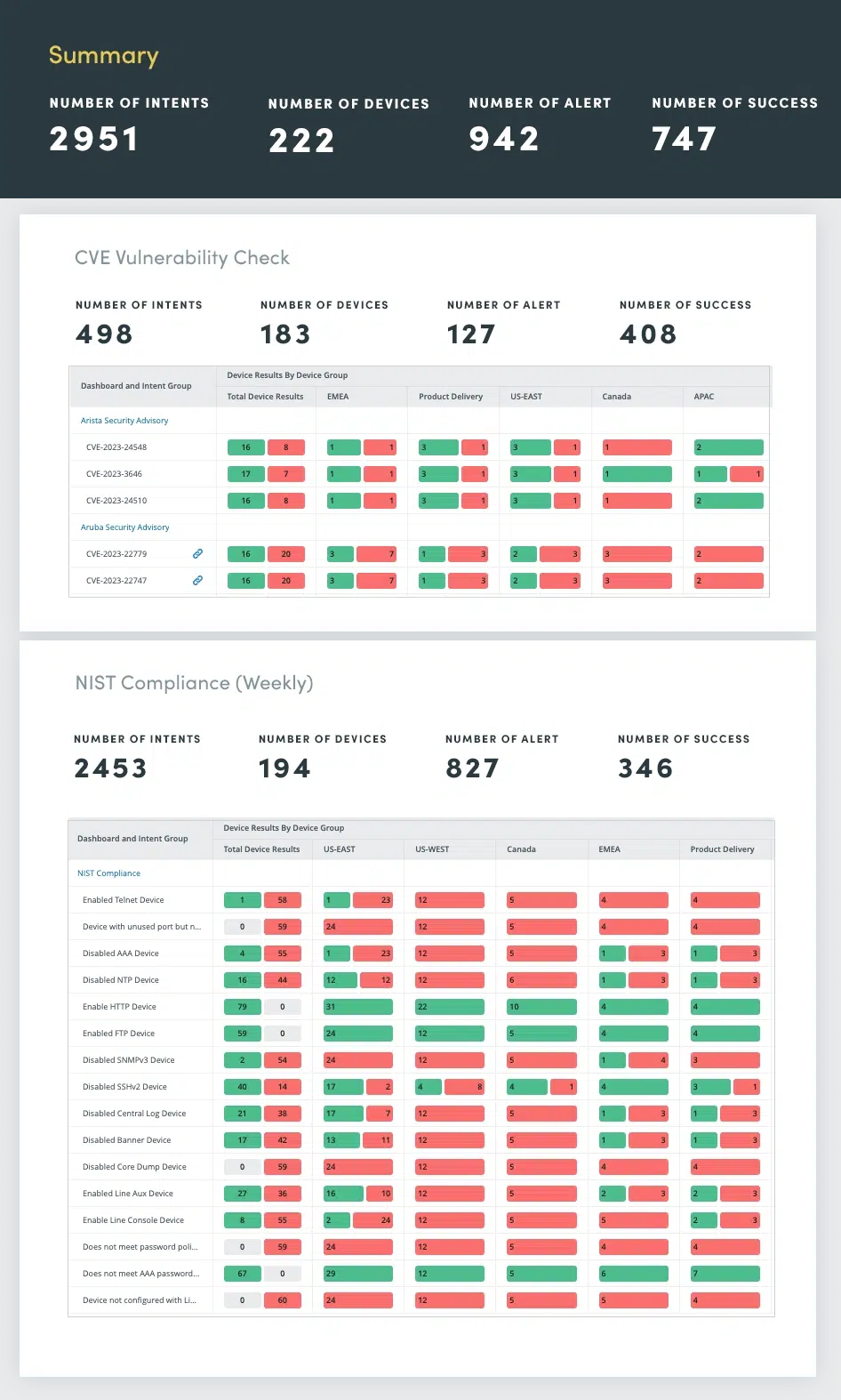
Asegúrese de que su red no sea vulnerable según el estándar NIST y los boletines CVE. Desde el cumplimiento de la seguridad hasta las recomendaciones de los proveedores, evalúe cualquier vulnerabilidad y corríjala antes de que surjan problemas. Las evaluaciones periódicas de seguridad de la red son esenciales para identificar y abordar vulnerabilidades que podrían comprometer datos confidenciales, interrumpir operaciones o dañar la reputación de una organización.
Las evaluaciones de seguridad de la red abarcan una evaluación integral de varios aspectos de seguridad, que incluyen:
Al automatizar estas evaluaciones de seguridad, puede monitorear continuamente la postura de la red, identificar y abordar de manera proactiva las vulnerabilidades y mantener una defensa sólida contra las ciberamenazas en evolución.
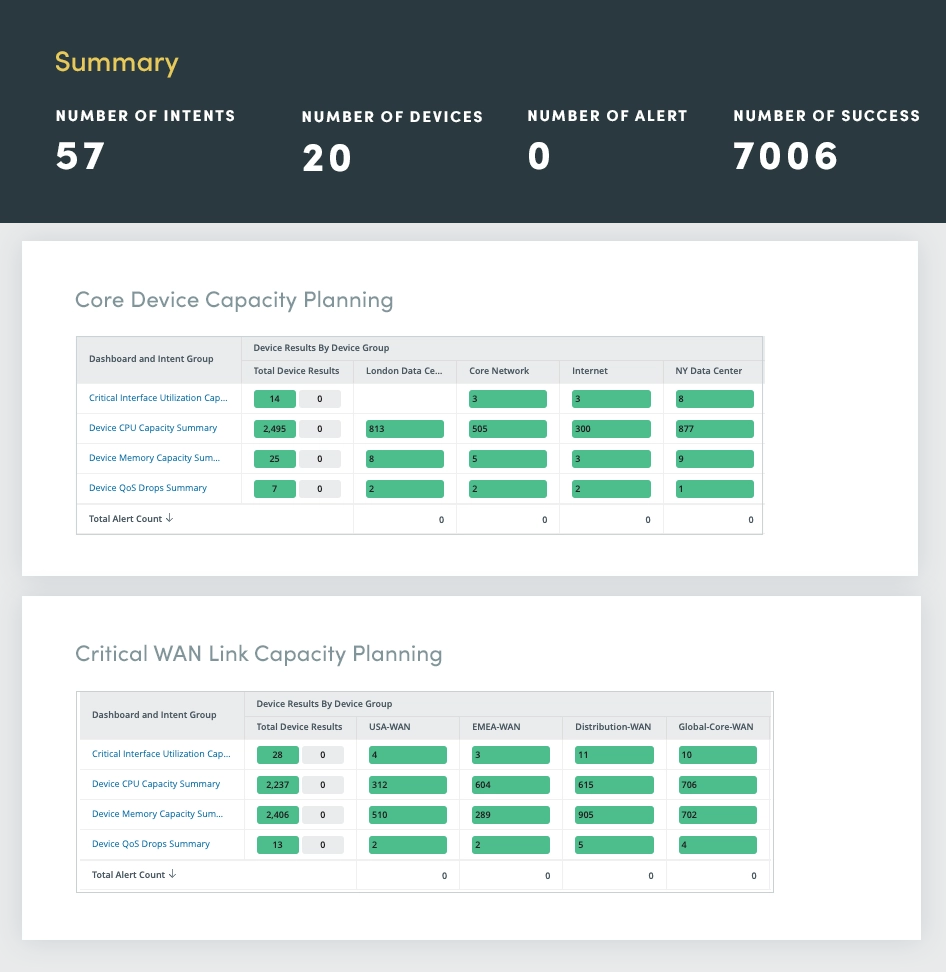
Una evaluación integral del ciclo de vida puede ayudarlo a mantenerse informado sobre el estado del ciclo de vida de su hardware de red, lo que garantiza actualizaciones oportunas y decisiones de reemplazo.
Al aprovechar las llamadas API automatizadas a proveedores de hardware, como Cisco, obtenga información en tiempo real sobre:
Tome decisiones informadas sobre la gestión del ciclo de vida del hardware, optimizando su red en términos de rendimiento, seguridad y rentabilidad.
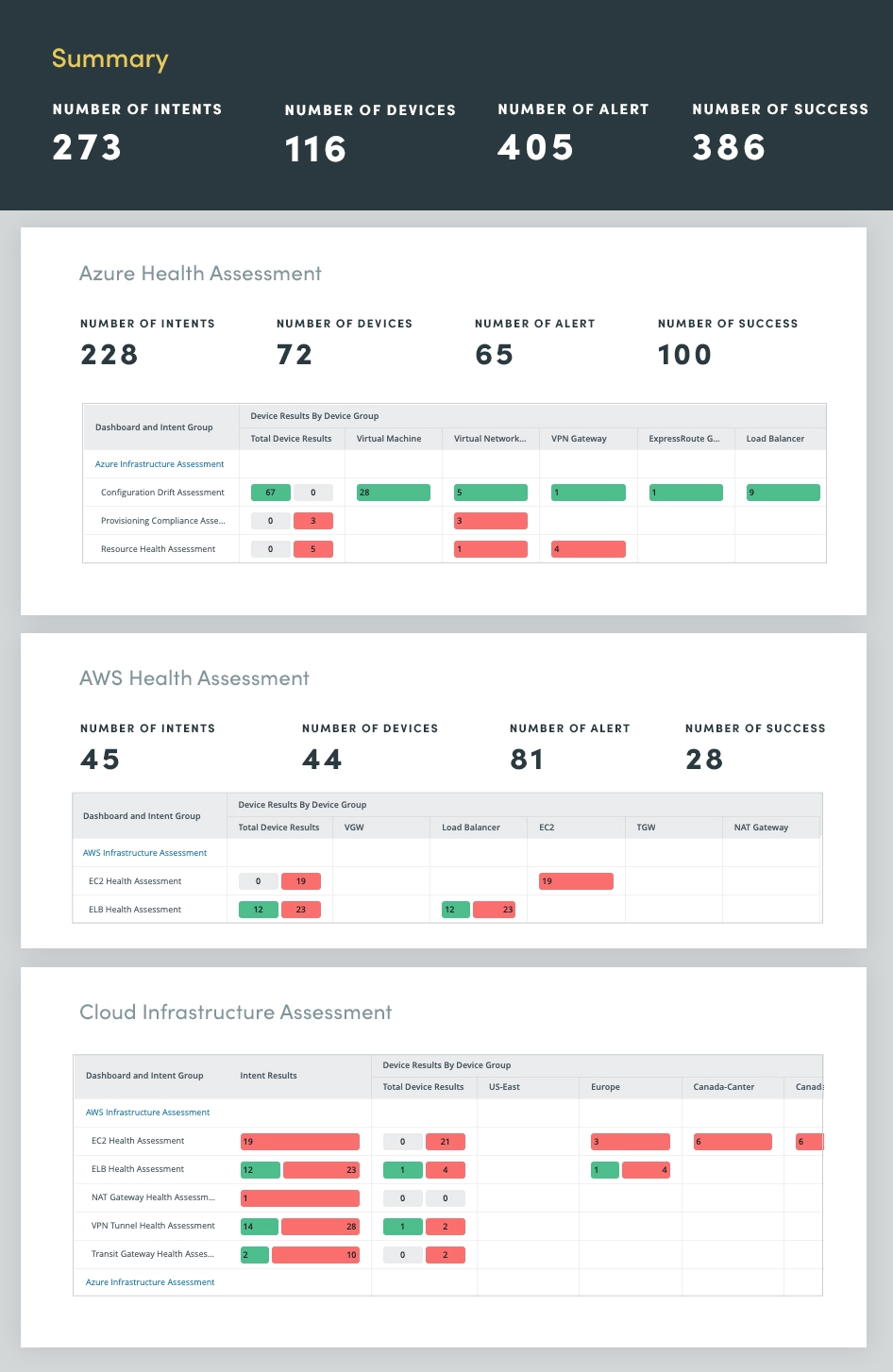
Al aplicar la automatización a la evaluación de redes de nube híbrida, puede monitorear y evaluar continuamente sus redes de nube a través de múltiples proveedores de nube, incluidos Microsoft Azure, Amazon AWS y Google Cloud para obtener información sobre:
Al evaluar continuamente la red de nube híbrida, identificar y abordar de manera proactiva problemas potenciales, optimizar el rendimiento y mantener una infraestructura de nube segura y resistente.
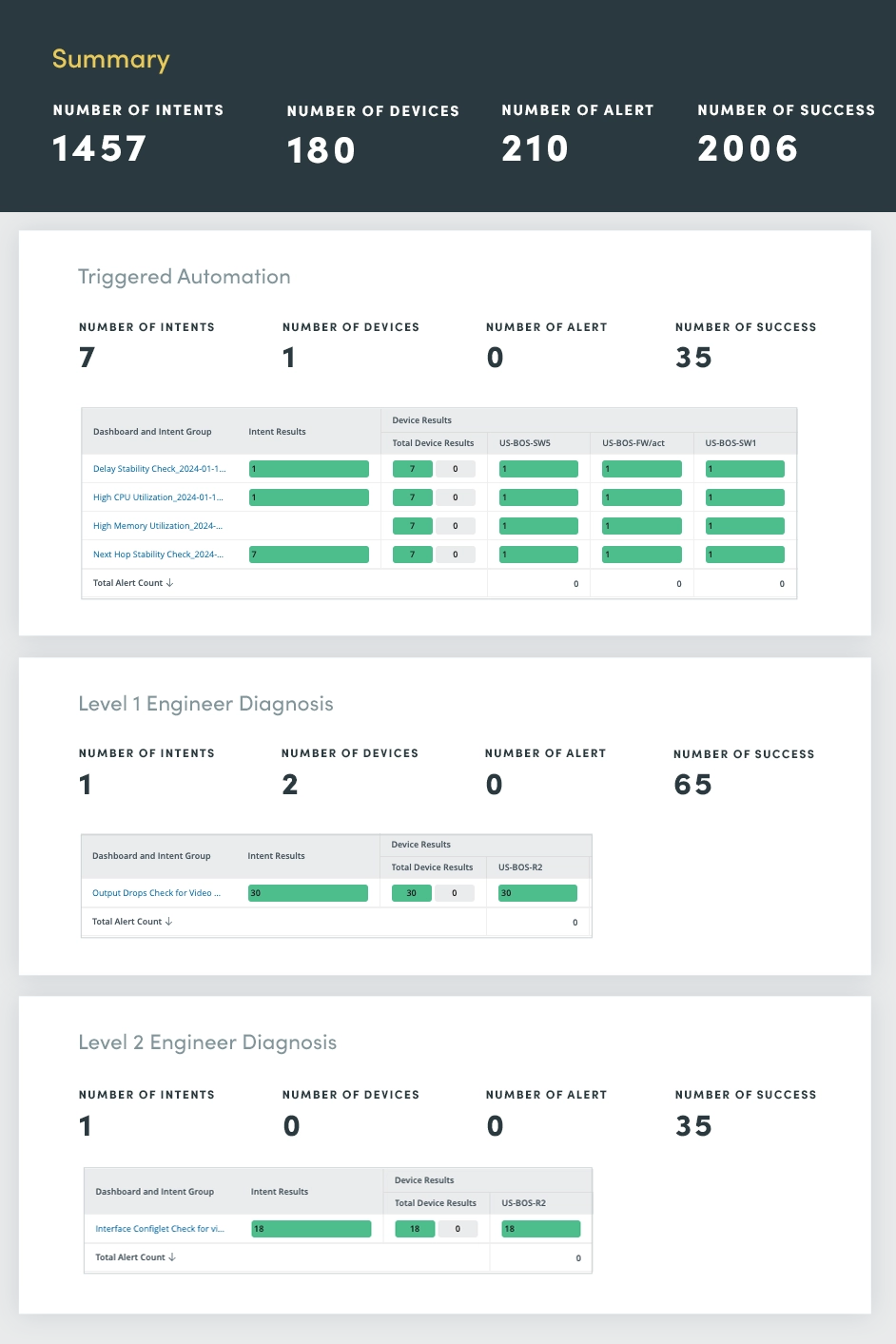
La Evaluación de automatización activada sirve como un centro centralizado para monitorear y responder a incidentes de red en tiempo real. Aprovechando el poder de la automatización, agilice los procesos de gestión de incidentes, permitiendo un diagnóstico, priorización y resolución rápidos.
Al recibir una notificación de incidente entrante a través de API, el panel de automatización activado aplica capacidades de autodiagnóstico inteligente:
La automatización de estas tareas críticas de gestión de incidentes reduce significativamente los tiempos de respuesta, minimiza el tiempo de inactividad y mejora la resiliencia general de la red.
¿Están ocurriendo problemas conocidos nuevamente? Después de una interrupción de la red, evalúe cualquier problema similar en su red. Por cada problema que ocurrió antes en su red, ¿podría volver a ocurrir en otra parte de su red?
Podria. Aplique una evaluación basada en problemas en toda su red y supervise los resultados continuamente. Para prevenir eficazmente futuras interrupciones, las organizaciones deben realizar evaluaciones exhaustivas posteriores a las interrupciones, analizando las causas fundamentales de incidentes pasados e identificando vulnerabilidades potenciales que podrían conducir a problemas similares.
Al analizar interrupciones pasadas, las organizaciones pueden:
Al abordar proactivamente problemas pasados y aprender de ellos, puede mejorar significativamente la resiliencia de la red y minimizar el riesgo de interrupción.
¿Sabe si su red se está quedando sin ancho de banda? La evaluación continua de la capacidad puede reducir el riesgo de sobreutilización y subutilización en las redes.
Al recopilar monitoreo y análisis continuos de los patrones de tráfico de la red, la utilización de recursos y las métricas de rendimiento, puede obtener información valiosa sobre las demandas de capacidad de la red y abordar de manera proactiva los problemas potenciales antes de que afecten a los usuarios o interrumpan los procesos comerciales.
Habilite una planificación proactiva y estrategias de escalamiento anticipando las necesidades futuras de capacidad para evitar medidas reactivas costosas mediante el monitoreo de estas métricas clave:
Tome decisiones más informadas para optimizar el rendimiento y garantizar la escalabilidad.
La automatización contiene las respuestas para stc
El centro de datos y los equipos de diseño de stc utilizan NetBrainEvaluaciones de red periódicas para verificaciones de estado del rendimiento de las aplicaciones, protegidas change managementy monitoreo proactivo de la infraestructura. Lea el estudio de caso completo.
La automatización de redes sin código está transformando la evaluación de redes tradicional de una tarea obsoleta relacionada con la auditoría a una herramienta operativa estratégica en tiempo real que empodera a los equipos de operaciones todos los días. Evalúe de forma proactiva el rendimiento de la red con diagnósticos e información automatizados, lo que le permitirá identificar y abordar problemas potenciales antes de que afecten las operaciones comerciales. Las evaluaciones continuas de la red ofrecen una visión integral de las condiciones operativas de su red en tiempo real.