DORA: 金融ITが知っておくべきこと
デジタル・オペレーショナル・レジリエンス法(DORA)は、17年2025月1日に欧州連合(EU)全域で施行され、金融機関によるサイバーリスクとオペレーショナルリスクの管理方法を再構築しました[XNUMX]。米国では…

ネットワーク障害は、財務面および運用面に甚大な影響を及ぼします。サービスの中断から評判の失墜まで、コストは急速に膨らみ、1件あたり数十万、数百万ドルに達することも珍しくありません。幸いなことに、実用的なネットワーク評価ツールが存在します。これらのツールを活用することで、弱点を特定し、障害の発生を防ぎ、コストのかかる中断なく重要な業務を維持できます。
による 2023年アップタイム研究所調査直近の大規模障害で54%の組織が100,000万ドル以上の損失を被り、16%は1万ドルを超えたと回答しています。2024年には、 調査によると 障害の頻度と深刻度は変化していない。毎年、世界中で10~20件の大規模なIT障害やデータセンター障害が発生し、深刻な経済的損失、事業および顧客の混乱、評判の失墜、そして極端な場合には人命の損失につながっています。
冗長性が組み込まれているにもかかわらず、手動プロセスと事後対応型のトラブルシューティングが蔓延しているため、ネットワークは依然として脆弱です。エンジニアはサービス基盤の構築に多大な時間を費やしていますが、その徹底は最小限にとどまっています。トラブルシューティングは問題が発生してから開始されるため、対応が遅れています。根本的な問題は、プロアクティブな対応の欠如と、ネットワーク自動化の導入が限られていることです。ハイブリッド環境全体にわたって運用に関する知識を自動的に収集・適用するための効率的なツールが不足しているため、問題が繰り返し発生しています。
2021年、stcは重大なアプリケーション障害に見舞われ、解決までにチーム横断的なトラブルシューティングに約XNUMXヶ月を要しました。この多大な損失は、同社がより高い可視性と戦略的なインシデント管理アプローチを必要としていることを如実に示しました。同社のCTOは、インフラストラクチャとアプリケーション全体にわたるエンドツーエンドの可視性と自動化されたインシデント管理を提供する組織全体のソリューションを推進しました。
現在、stcのデータセンターと設計チームは NetBrainアプリケーション パフォーマンスのヘルス チェック、保護された変更管理、およびプロアクティブなインフラストラクチャ監視のために、ネットワーク評価を定期的に実行します。 ケーススタディ全文を読む.
ネットワーク自動化は、事後対応型の対策を超えて進化しています。エンジニアの専門知識を取り込み、コーディングなしでネットワーク全体にプロアクティブに適用することを想像してみてください。それがまさに NetBrain 可能になります。私たちの intent-based network automation このプラットフォームにより、手動のプロセスに代わって、ネットワークの健全性、コンプライアンス、変更をコードなしで継続的に評価できるようになります。
NetBrain 一般的なエンタープライズネットワーク評価のライブラリを基盤として提供し、ノーコードプラットフォームにより、これらのテンプレートをお客様独自の環境に合わせてカスタマイズ・拡張できます。結果はウィジェットベースのサマリーダッシュボードで簡単に視覚化・共有でき、チームはリアルタイムのネットワークインサイトを活用できます。
主要なネットワーク障害評価は次のとおりです。 NetBrain 数分で処理します。
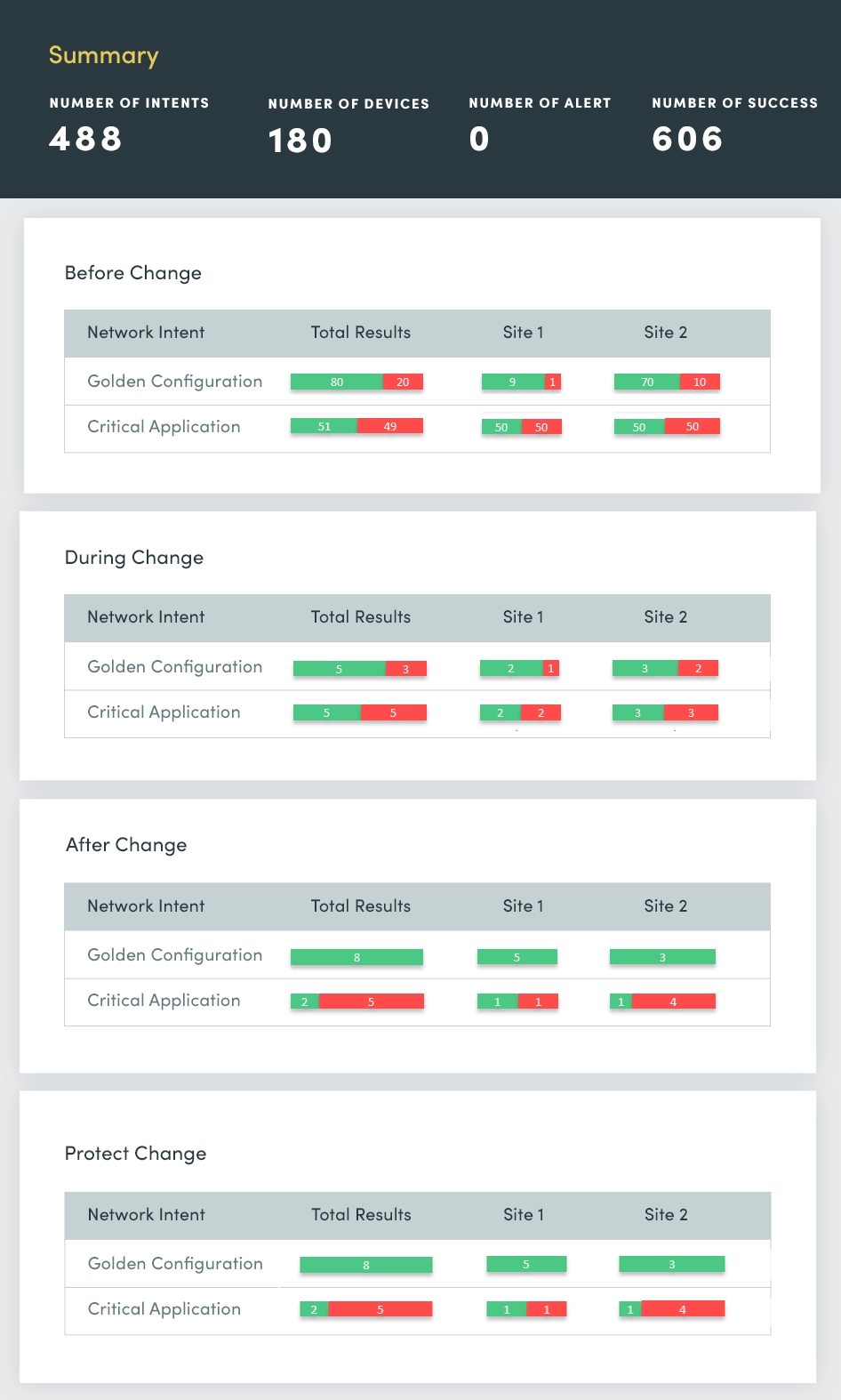
毎週初めには、ネットワーク障害の報告があり、「週末に何が変わったのか、どこで変化が起きたのか」という疑問が生じます。こうしたネットワークの変化をより迅速に特定し、共通の原因があるかどうかを判断して迅速に対処・解決することで、ネットワークの安定性を確保し、中断を最小限に抑える必要があります。
変更評価では、以下を継続的に評価し、要約します。
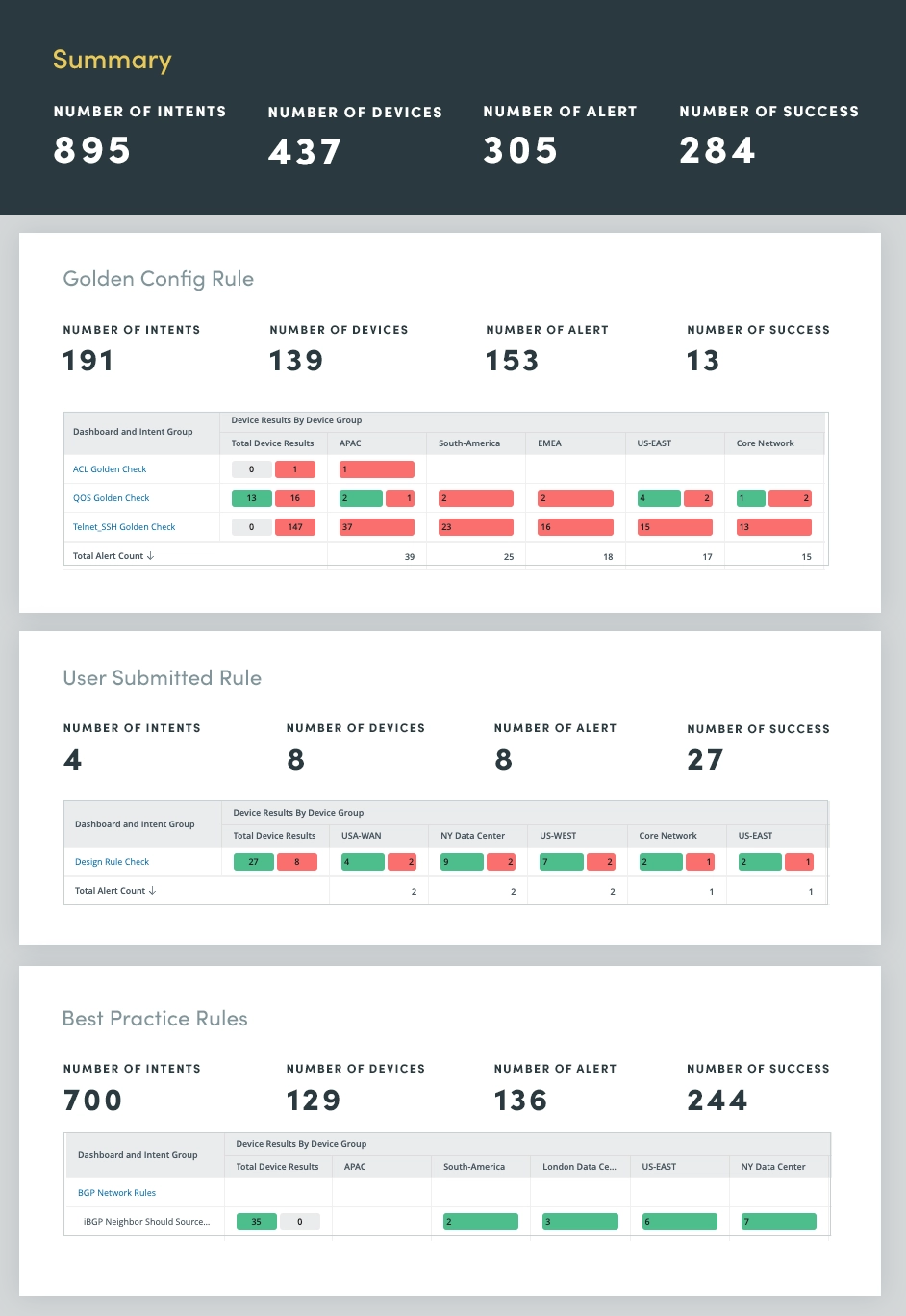
人為的ミスは、多くの場合、手動によるネットワーク変更に起因するもので、ネットワーク障害の主な原因となっています。この問題に対処するには、ネットワークのアンチドリフトアセスメントを活用して、確立された構成ルールやベストプラクティスからの逸脱を特定します。これらのルールの適用を自動化することで、人為的ミスの発生率を大幅に低減し、ネットワークの安定性を確保できます。
アンチドリフト評価には、次の 3 つのルール カテゴリが含まれます。
これらのルールの適用を自動化することで、構成のドリフトを効果的に防止し、人的エラーのリスクを最小限に抑えることができます。このプロアクティブなアプローチにより、ネットワークの安定性が向上するだけでなく、ネットワーク全体のパフォーマンスとセキュリティも向上します。
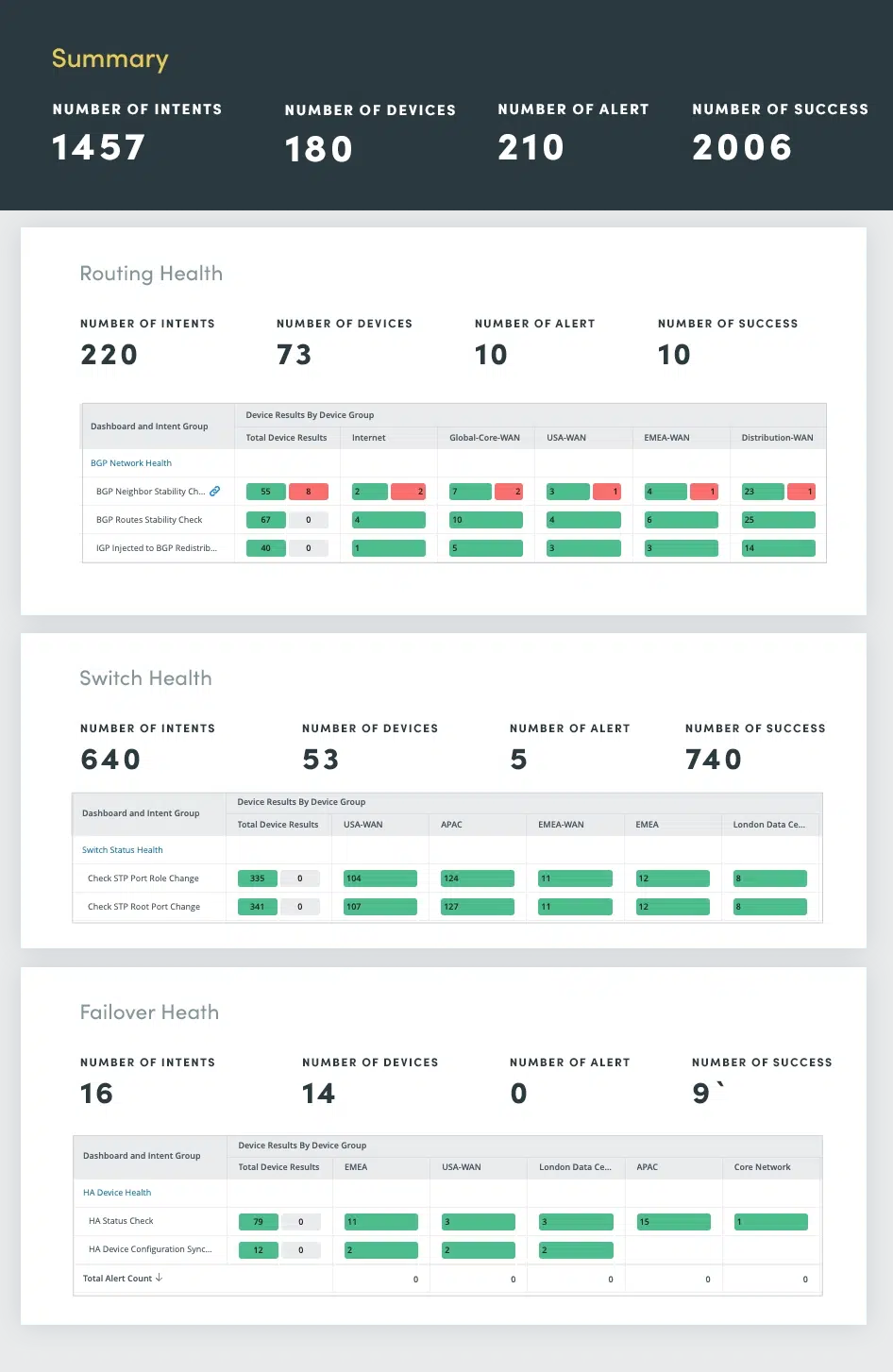
高度なネットワーク冗長性により、信頼性の高い高性能の接続が提供されます。ただし、これらの機能が適切に監視および保守されていない場合、潜在的な問題の原因となる可能性があります。継続的なネットワーク健全性評価は、大規模な障害に発展する前に潜在的な問題を特定して対処する上で重要な役割を果たします。
ネットワークの健全性評価には、ルーティング、スイッチング、フェイルオーバー、VPN、ワイヤレス、エラー ログの包括的な評価が含まれます。
これらの重要なネットワーク コンポーネントを継続的に評価することで、潜在的な問題を事前に特定して解決し、最適なネットワーク パフォーマンス、可用性、セキュリティを確保できます。
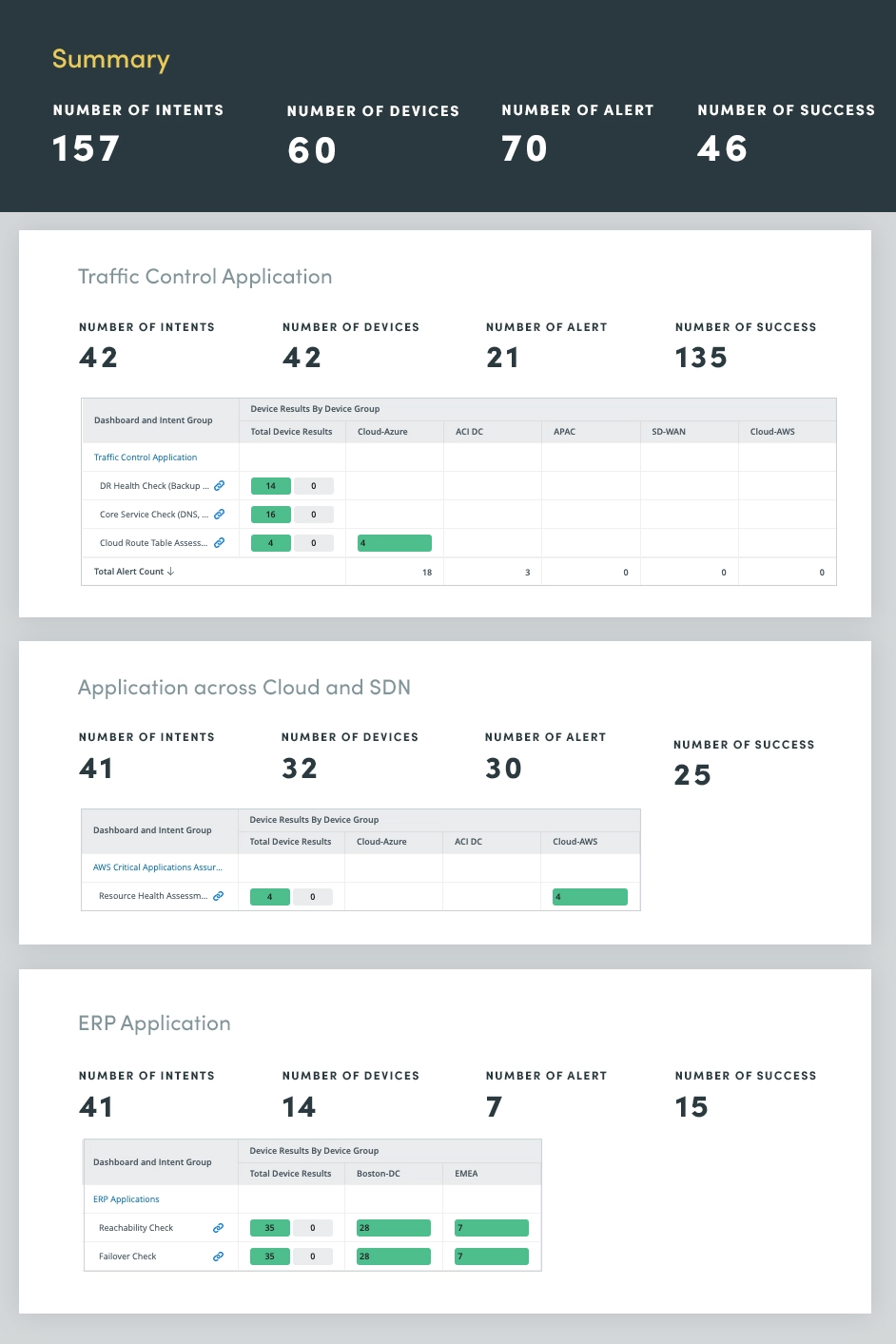
ミッションクリティカルなアプリケーションの健全性を継続的に監視および評価することで、潜在的な問題がユーザーに影響を与えたり、ビジネス プロセスを混乱させたりする前に特定して対処できます。このプロアクティブなアプローチは、コストのかかる停止を防止し、アプリケーションのパフォーマンスを最適化し、システム全体の信頼性を高めるのに役立ちます。
アプリケーションの正常性評価には、CPU とメモリの容量、QoS の低下、重要なインターフェイスの使用率、潜在的なアプリケーションの問題を事前に特定して対処するためのログ分析やイベント監視などのタスクを含む、さまざまなアプリケーションのメトリックとコンポーネントの包括的な評価が含まれます。
これらの重要なアプリケーションのメトリクスを継続的に評価することで、アプリケーションの健全性に関する貴重な洞察を得ることができ、パフォーマンスの最適化、停止の防止、良好なユーザー エクスペリエンスの維持が可能になります。
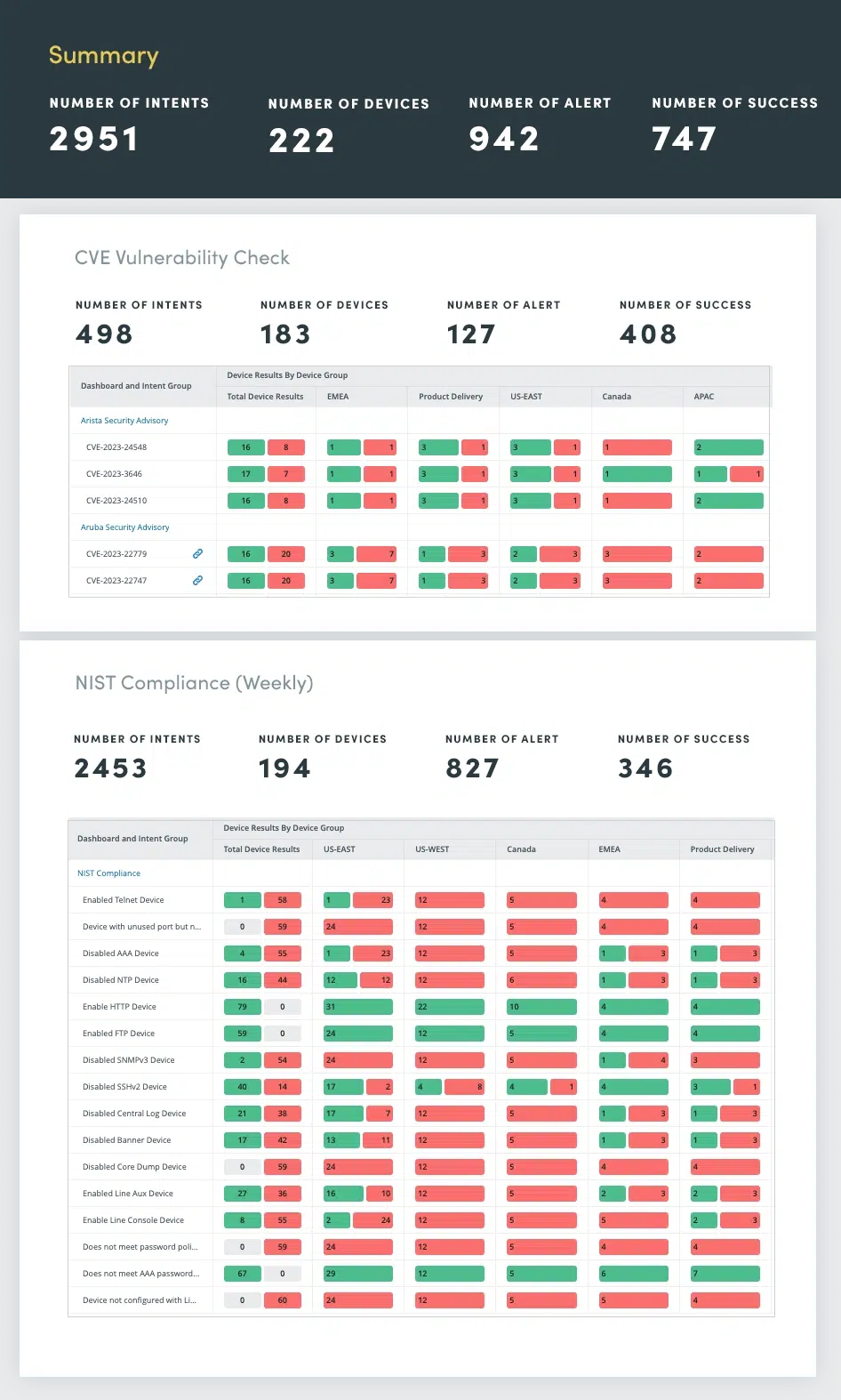
米国国立標準技術研究所(NIST)とCVE速報に基づき、ネットワークの脆弱性がないか確認してください。セキュリティコンプライアンスからベンダーの推奨事項まで、あらゆる脆弱性を評価し、問題が発生する前に修正してください。機密データの漏洩、業務の中断、組織の評判の低下につながる可能性のある脆弱性を特定し、対処するには、定期的なネットワークセキュリティ評価が不可欠です。
ネットワーク セキュリティ評価には、次のようなさまざまなセキュリティ側面の包括的な評価が含まれます。
これらのセキュリティ評価を自動化することで、ネットワークの状態を継続的に監視し、脆弱性を積極的に特定して対処し、進化するサイバー脅威に対する強力な防御を維持することができます。
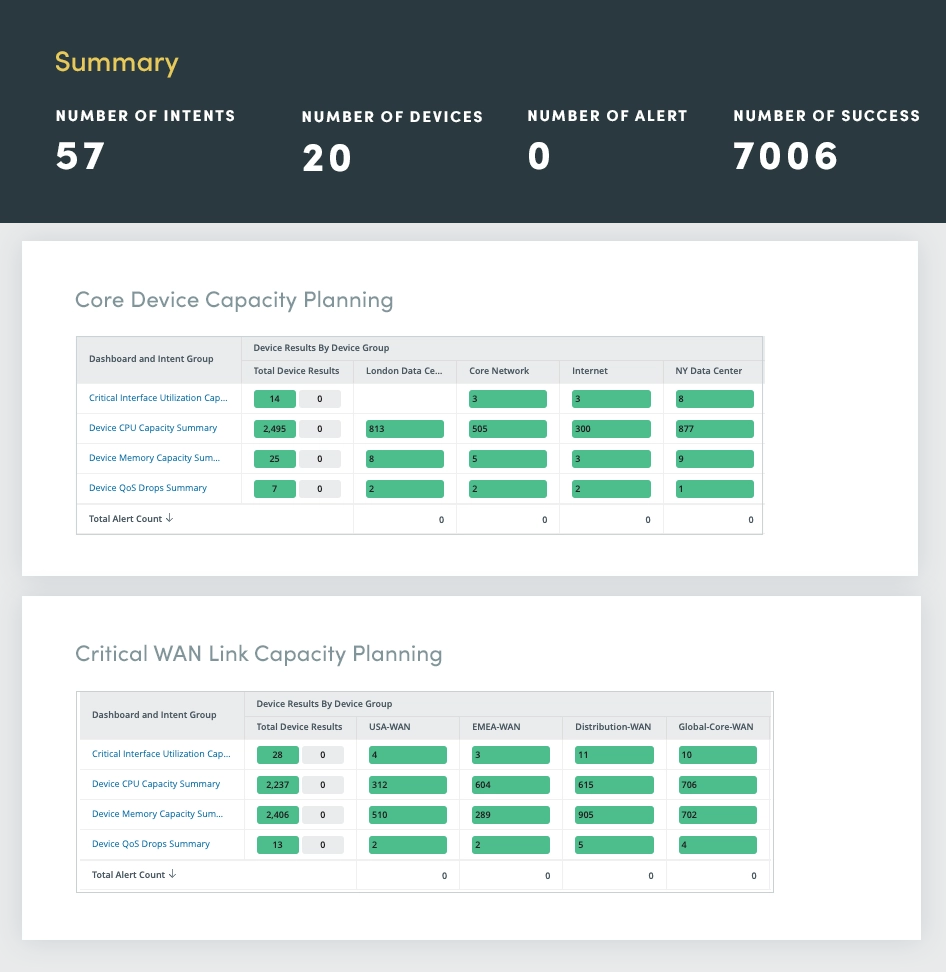
包括的なライフサイクル評価は、ネットワーク ハードウェアのライフサイクル ステータスに関する情報を常に把握し、タイムリーなアップグレードと交換の決定を確実に行うのに役立ちます。
Cisco などのハードウェア ベンダーへの自動 API 呼び出しを活用することで、次のようなリアルタイム情報を取得できます。
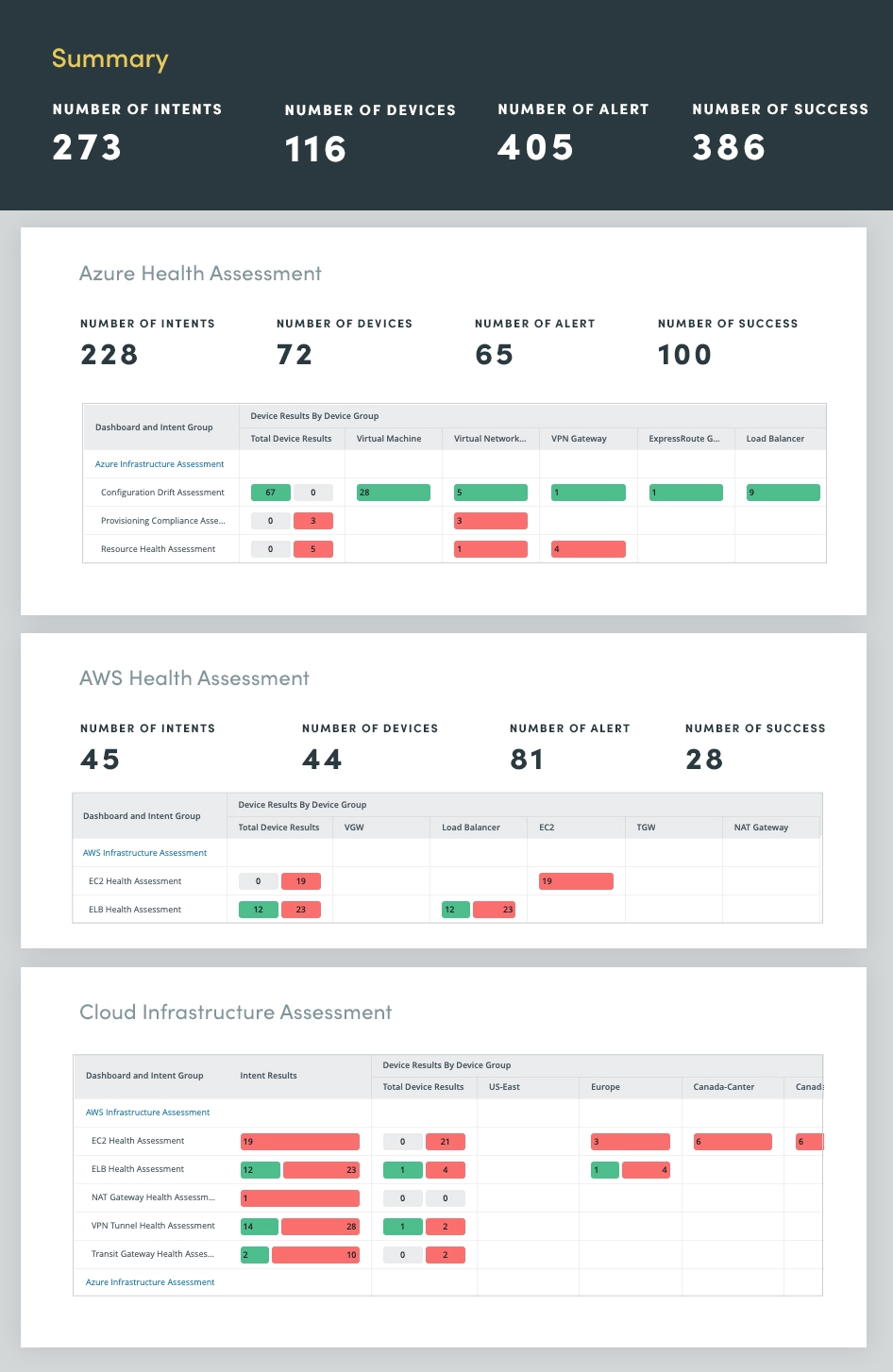
ハイブリッド クラウド ネットワーク評価に自動化を適用することで、Microsoft Azure、Amazon AWS、Google Cloud などの複数のクラウド プロバイダーにわたるクラウド ネットワークを継続的に監視および評価して、次のような洞察を得ることができます。
ハイブリッド クラウド ネットワークを継続的に評価することで、潜在的な問題を積極的に特定して対処し、パフォーマンスを最適化し、安全で復元力のあるクラウド インフラストラクチャを維持します。
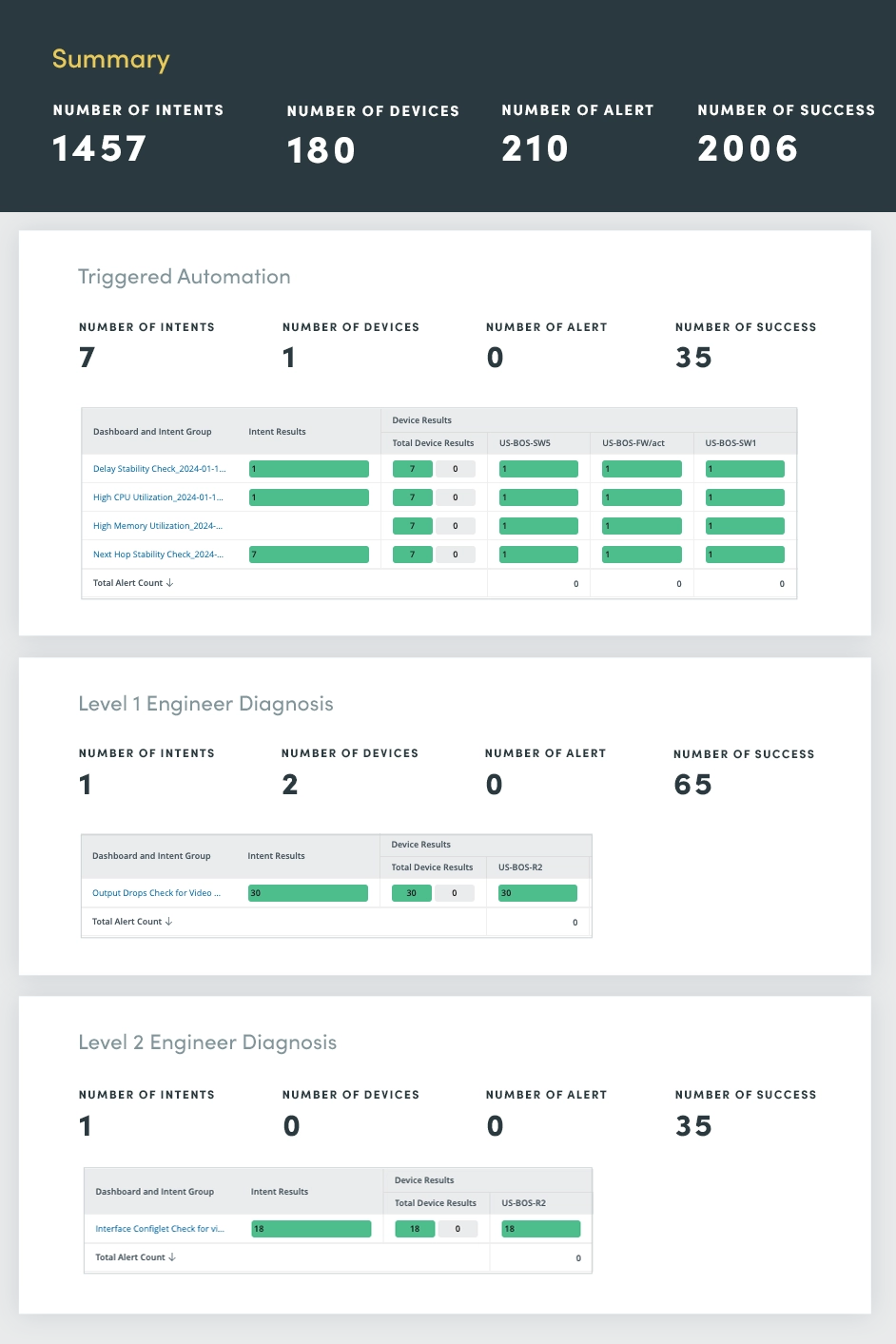
Triggered Automation Assessment は、ネットワーク インシデントをリアルタイムで監視し、対応するための集中ハブとして機能します。自動化の力を活用することで、インシデント管理プロセスを合理化し、迅速な診断、優先順位付け、解決を可能にします。
API 経由でインシデント通知を受信すると、トリガーされた自動化ダッシュボードがインテリジェントな自動診断機能を適用します。
これらの重要なインシデント管理タスクを自動化すると、応答時間が大幅に短縮され、ダウンタイムが最小限に抑えられ、ネットワーク全体の回復力が強化されます。
障害発生後、ネットワーク内の他の場所で同様の問題がないか評価することが重要です。既知の問題ごとに、別の場所やさまざまな条件下で再発する可能性を検討してください。問題ベースの評価(広範囲に適用し、継続的に監視)は、これらのリスクを明らかにするのに役立ちます。将来のダウンタイムを真に削減するには、チームは根本原因分析にとどまらず、パターンを積極的に探り、弱点を強化し、そこから得られた知見を活用して、ネットワークを再発防止に役立てる必要があります。
過去の停止を分析することで、組織は次のことが可能になります。
過去の問題に積極的に対処し、そこから学ぶことで、ネットワークの復元力を大幅に強化し、停止のリスクを最小限に抑えることができます。
継続的なキャパシティアセスメントは、リアルタイムのトラフィックパターン、リソース消費量、パフォーマンス指標を分析することで、過剰利用と過少利用を防止します。このプロアクティブなアプローチにより、需要予測、ネットワークパフォーマンスの最適化、そしてシームレスなビジネスオペレーションの維持のための可視性が得られます。
次の主要な指標を監視することで、将来の容量ニーズを予測し、コストのかかる事後対応策を回避することで、プロアクティブな計画とスケーリング戦略を実現します。
より多くの情報に基づいた意思決定を行って、パフォーマンスを最適化し、スケーラビリティを確保します。
ノーコード・ネットワーク自動化は、従来のネットワーク評価を、時代遅れの監査関連タスクから、運用チームの日々の業務を支援する戦略的かつリアルタイムな運用ツールへと変革します。自動診断とインサイトを活用してネットワークパフォーマンスをプロアクティブに評価することで、潜在的な問題が業務に影響を与える前に特定し、対処することができます。
より回復力のあるネットワークの構築を始める準備はできていますか? 今日デモをスケジュールする どのように探索するか NetBrain チームの停止を防ぐのに役立ちます。