Ausfallzeiten sind teuer. Mehr als die Hälfte (54 %) der Befragten der Rechenzentrumsumfrage 2023 des Uptime Institute geben an, dass ihr jüngster erheblicher, schwerwiegender oder schwerwiegender Ausfall mehr als 100,000 US-Dollar gekostet hat, und 16 % gaben an, dass ihr jüngster Ausfall mehr als 1 Million US-Dollar gekostet hat.
Der Satz aus dem Film „Apollo 13“ „Misserfolg ist keine Option“ ist einer der bekanntesten Filmslogans aller Zeiten.
Im Netzwerkbetrieb ist es die gleiche Denkweise. Geld und Ruf stehen auf dem Spiel. Scheitern ist keine Option.
Warum sind wir angesichts der vielen integrierten Redundanznetzwerke immer noch so anfällig? Warum verlassen wir uns weiterhin so stark auf manuelle Prozesse und reaktive Fehlerbehebung? Netzwerktechniker verbringen unzählige Stunden damit, die Grundlage für die Bereitstellung von Diensten zu schaffen, doch es gibt kaum oder gar keine regelmäßige Durchsetzung. Erst wenn ein Problem gemeldet wird, werden die Räder der Fehlerbehebung in Gang gesetzt.
Im Jahr 2021 kam es bei einer kritischen Anwendung bei stc zu einer erheblichen Dienstunterbrechung. Die Fehlerbehebung bei Netzwerkbetrieb, Servern, Anwendungen und Sicherheitsteams dauerte fast einen Monat, um die Ursache zu ermitteln und den Dienst wiederherzustellen. Dieser kostspielige Ausfall verdeutlichte die Notwendigkeit einer besseren Transparenz und eines strategischeren Ansatzes für das Vorfallmanagement. Daher drängte der Group CTO von stc auf eine unternehmensweite Lösung, die durchgängige Transparenz bietet und das Vorfallmanagement über Infrastruktur und Anwendungen hinweg automatisiert.
Die Netzwerkautomatisierung ist inzwischen rasant vorangekommen und ermöglicht nun die kontinuierliche Bewertung der Betriebsbedingungen eines Netzwerks ohne Entwicklungszyklen. NetBrain hat eine Reihe der häufigsten Bewertungen erstellt, die Unternehmensnetzwerke benötigen, um einen ausfallsicheren Betrieb sicherzustellen. Die No-Code-Automatisierungsplattform stellt jedoch sicher, dass der Netzwerkbetrieb nicht auf eine begrenzte Anzahl von Bewertungen beschränkt ist. Ohne zusätzliche Ressourcen können Sie problemlos auf diesen Vorlagen aufbauen und Ihr System kontinuierlicher Bewertungen für Ihre individuellen Netzwerkanforderungen erstellen. Und du kannst Visualisieren und teilen Sie netzwerkweite Bewertungsergebnisse über Widget-basierte Zusammenfassungs-Dashboards.
Sehen wir uns die 10 besten Netzwerkbewertungen zur Ausfallvermeidung an und sehen wir, wie das geht NetBrain kann diese in wenigen Minuten herstellen.
Die 10 besten Netzwerkbewertungen zur Ausfallprävention
1. Änderungsbewertung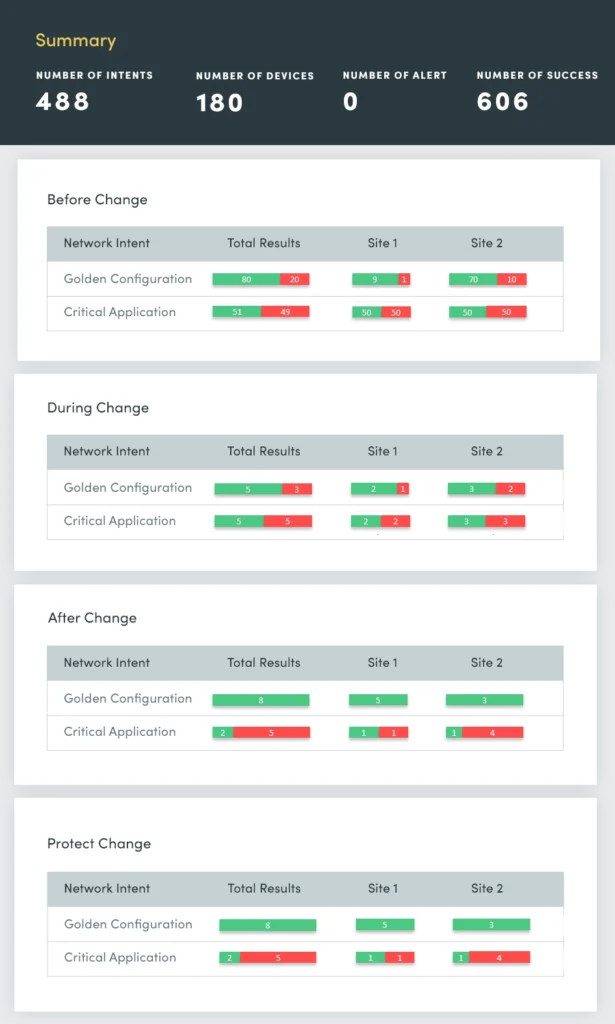
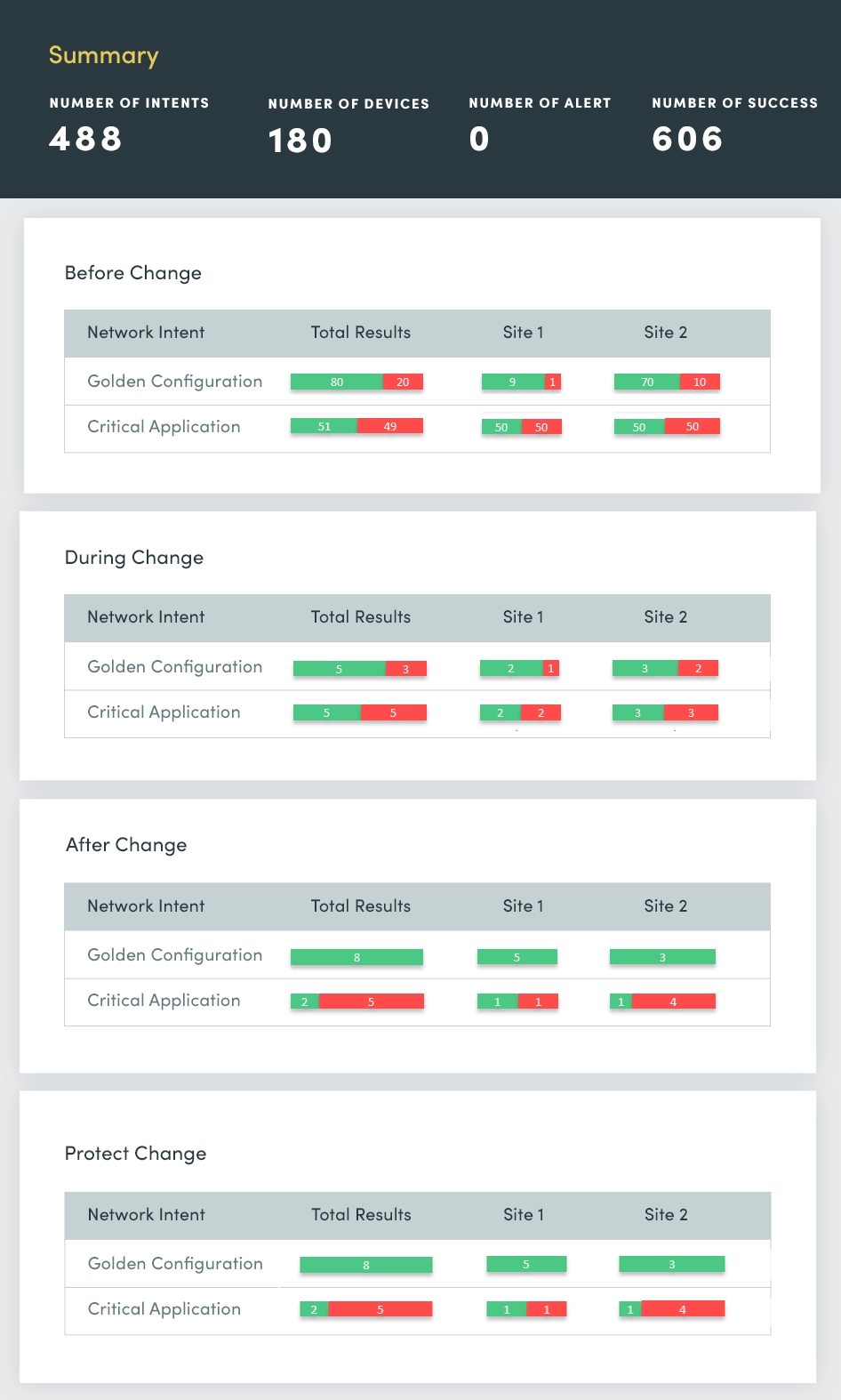
Zu Beginn jeder Woche gibt es Berichte über Netzwerkausfälle, die die Frage aufwerfen: Was hat sich am Wochenende geändert und wo sind diese Änderungen aufgetreten? Sie müssen diese Netzwerkänderungen schneller erkennen und feststellen, ob sie einen gemeinsamen Ursprung haben, damit Sie sie schnell beheben und beheben können, um die Stabilität des Netzwerks sicherzustellen und Störungen zu minimieren.
Mit einem Change Assessment bewerten und fassen Sie kontinuierlich Folgendes zusammen:
- Geräteergebnisse von device group
- ACL-Konfigurationsänderungen
- Routing-Konfigurationsänderungen
- Konfigurationsänderungen wechseln
- Änderungen der Failover-Konfiguration
2. Anti-Drift-Bewertung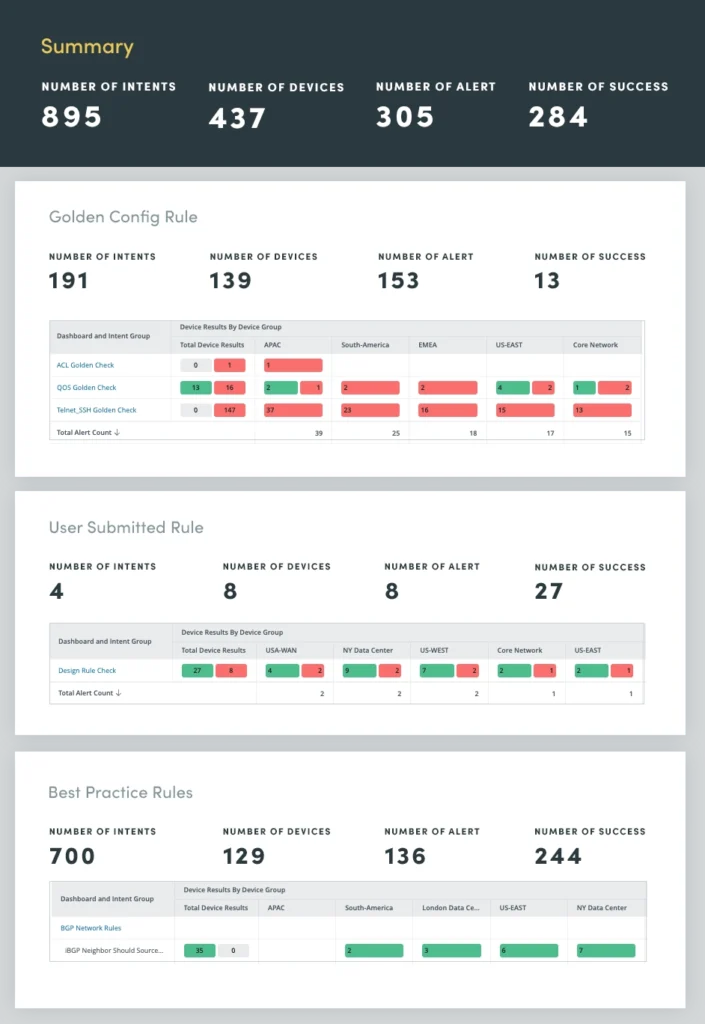
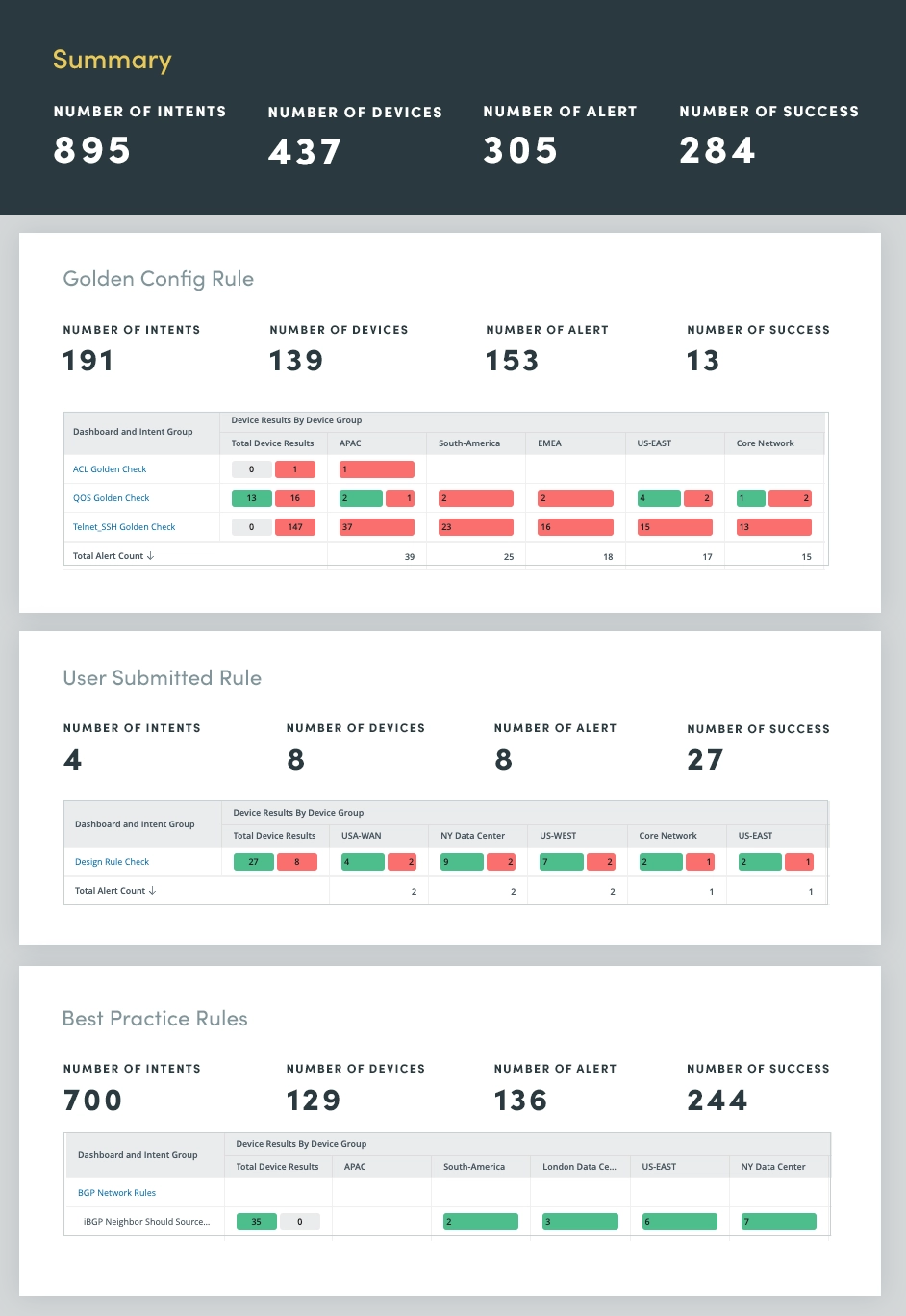
Menschliches Versagen, das häufig auf manuelle Netzwerkänderungen zurückzuführen ist, ist eine der Hauptursachen für Netzwerkausfälle. Um dieses Problem zu beheben, verwenden Sie eine Netzwerk-Anti-Drift-Bewertung, um Abweichungen von etablierten Konfigurationsregeln und Best Practices zu identifizieren. Durch die Automatisierung der Durchsetzung dieser Regeln können Sie die Häufigkeit menschlicher Fehler erheblich reduzieren und die Netzwerkstabilität gewährleisten.
Das Anti-Drift-Assessment umfasst drei Regelkategorien:
- Design- und Best-Practice-Regeln: Diese Regeln beschreiben branchenweite Best Practices für Netzwerkkonfigurationen und stellen sicher, dass das Netzwerk anerkannten Standards und Richtlinien entspricht.
- Goldene Konfigurationsregeln: Diese Regeln stellen die spezifischen Konfigurationsstandards der Organisation dar und fordern die Einhaltung interner Richtlinien und Verfahren.
- Vom Benutzer übermittelte Designregeln: Diese Regeln erfassen das Fachwissen von Netzwerkarchitekten und -ingenieuren und fassen Designprinzipien und -richtlinien zusammen, die auf die einzigartige Netzwerktopologie und -anforderungen der Organisation zugeschnitten sind.
Durch die Automatisierung der Durchsetzung dieser Regeln können Sie Konfigurationsdrift wirksam verhindern und das Risiko menschlicher Fehler minimieren. Dieser proaktive Ansatz erhöht nicht nur die Netzwerkstabilität, sondern verbessert auch die allgemeine Netzwerkleistung und -sicherheit.
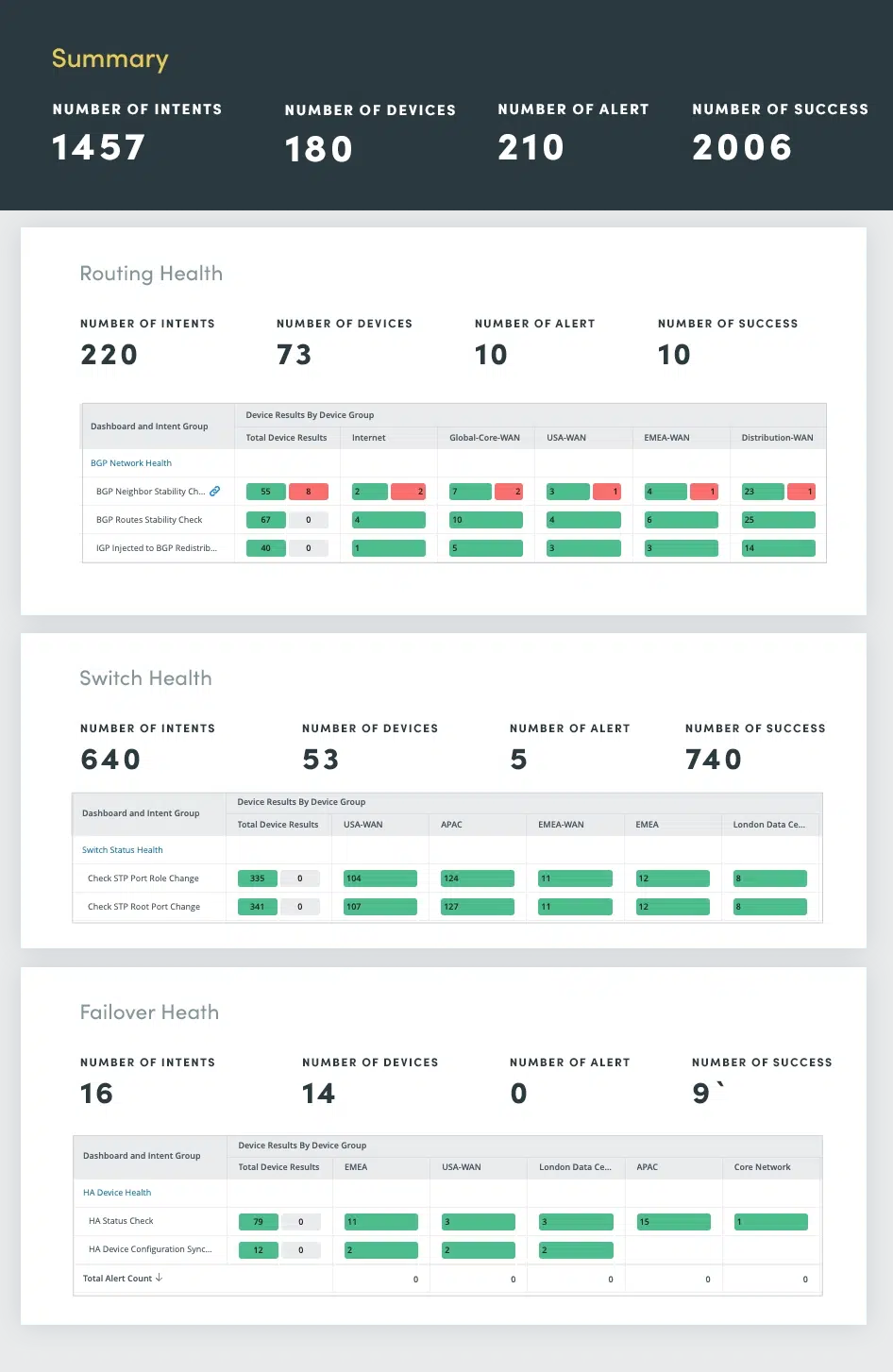
3. Bewertung der Netzwerkgesundheit
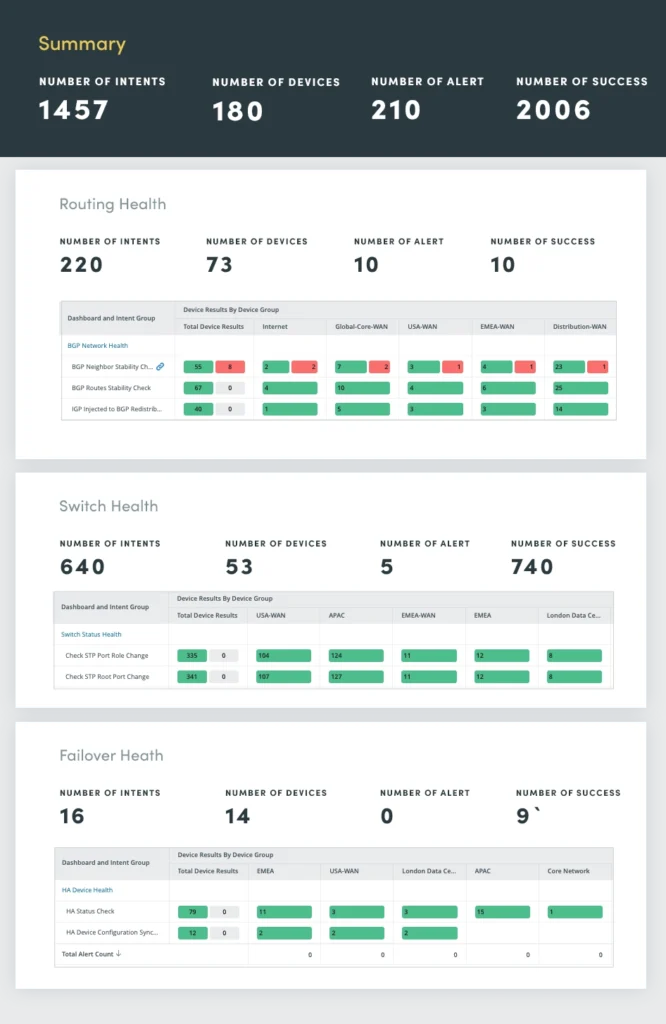
Eine ausgefeilte Netzwerkredundanz sorgt für zuverlässige und leistungsstarke Konnektivität. Wenn diese Funktionen jedoch nicht ordnungsgemäß überwacht und gewartet werden, können sie zu potenziellen Problemen führen. Die kontinuierliche Bewertung des Netzwerkzustands spielt eine entscheidende Rolle bei der Identifizierung und Behebung potenzieller Probleme, bevor sie zu größeren Ausfällen führen.
Die Bewertung des Netzwerkzustands umfasst eine umfassende Auswertung von Routing-, Switching-, Failover-, VPN-, WLAN- und Fehlerprotokollen.
Durch die kontinuierliche Bewertung dieser kritischen Netzwerkkomponenten können Sie potenzielle Probleme proaktiv identifizieren und lösen und so eine optimale Netzwerkleistung, Verfügbarkeit und Sicherheit gewährleisten.
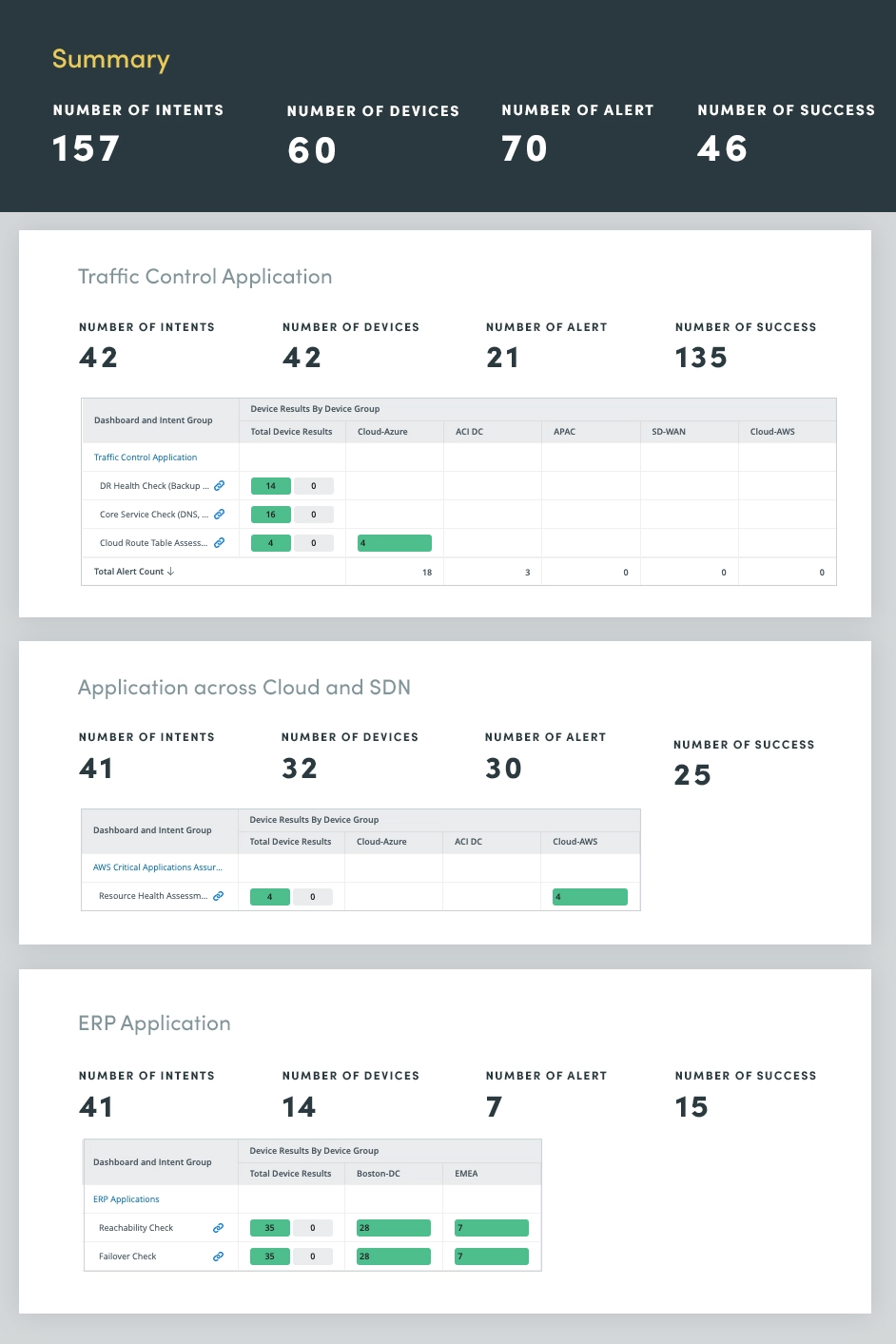
4. Kritische Anwendungsbewertung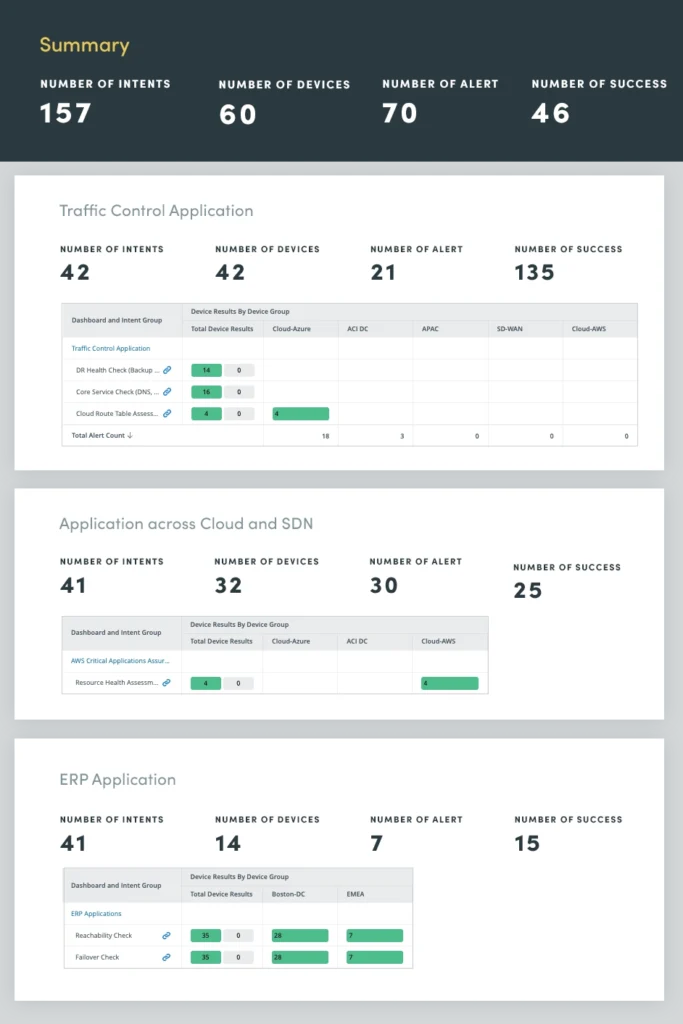
Durch die kontinuierliche Überwachung und Bewertung des Zustands geschäftskritischer Anwendungen können Sie potenzielle Probleme erkennen und beheben, bevor sie sich auf Benutzer auswirken oder Geschäftsprozesse stören. Dieser proaktive Ansatz trägt dazu bei, kostspielige Ausfälle zu verhindern, die Anwendungsleistung zu optimieren und die Gesamtsystemzuverlässigkeit zu verbessern.
Die Bewertung des Anwendungszustands umfasst eine umfassende Bewertung verschiedener Anwendungsmetriken und -komponenten, einschließlich CPU- und Speicherkapazität, QoS-Einbrüche, kritische Schnittstellennutzung und Aufgaben wie Protokollanalyse und Ereignisüberwachung, um potenzielle Anwendungsprobleme proaktiv zu identifizieren und zu beheben.
Durch die kontinuierliche Bewertung dieser kritischen Anwendungsmetriken können Sie wertvolle Einblicke in den Anwendungszustand gewinnen und so die Leistung optimieren, Ausfälle verhindern und ein positives Benutzererlebnis aufrechterhalten.
5. Sicherheitsbewertung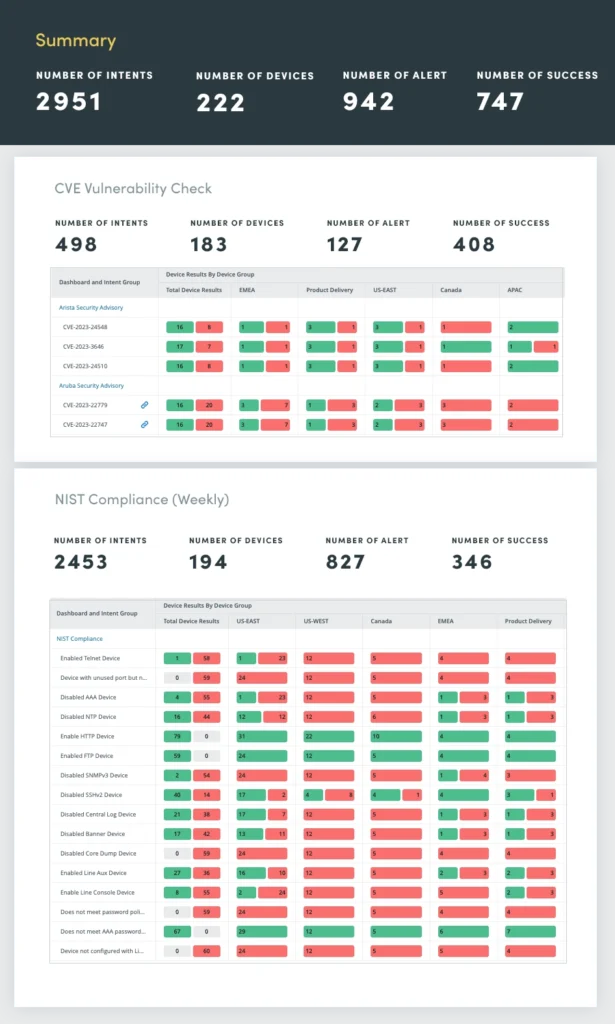
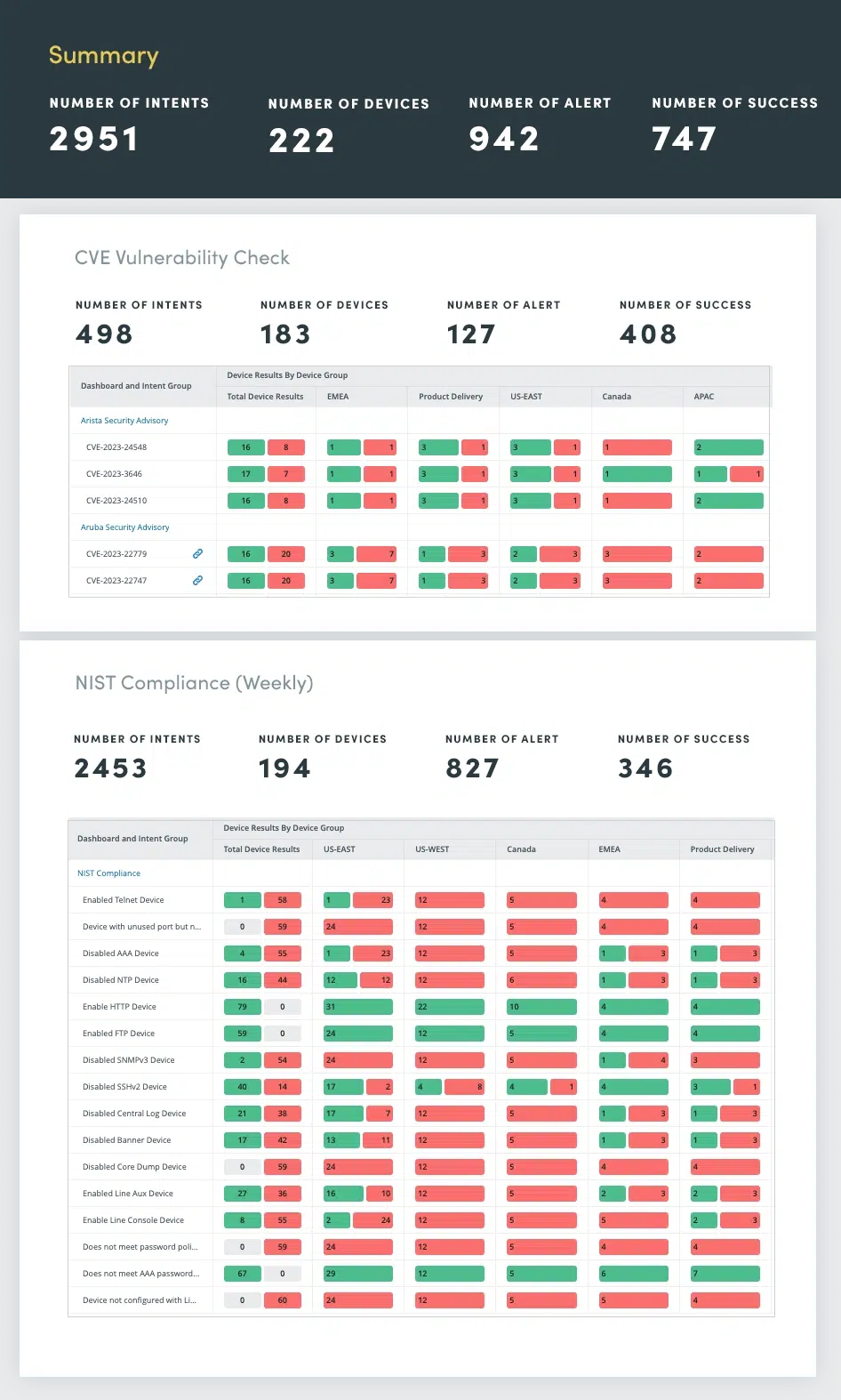
Stellen Sie sicher, dass Ihr Netzwerk gemäß NIST-Standard und CVE-Bulletins nicht anfällig ist. Von der Einhaltung von Sicherheitsbestimmungen bis hin zu Herstellerempfehlungen: Bewerten Sie alle Schwachstellen und beheben Sie sie, bevor Probleme auftreten. Regelmäßige Netzwerksicherheitsbewertungen sind unerlässlich, um Schwachstellen zu identifizieren und zu beheben, die sensible Daten gefährden, den Betrieb stören oder den Ruf eines Unternehmens schädigen könnten.
Netzwerksicherheitsbewertungen umfassen eine umfassende Bewertung verschiedener Sicherheitsaspekte, darunter:
- Einhaltung der NIST- und NERC-Standards
- Schwachstellenerkennung mithilfe des CVE-Katalogs (Common Vulnerabilities and Exposures).
- Fehlkonfigurationen, die zu Sicherheitslücken führen können, wie z. B. schwache Passwörter, unsichere Protokolle und unbefugte Zugriffsberechtigungen
- Intrusion Detection/Prevention (IDS/IPS): Analysieren Sie IDS/IPS-Protokolle
- Analyse des Netzwerkverkehrs: Überwachen Sie den Netzwerkverkehr, um Anomalien zu erkennen, die auf verdächtige Aktivitäten oder Netzwerkangriffe hinweisen könnten
Durch die Automatisierung dieser Sicherheitsbewertungen können Sie den Netzwerkstatus kontinuierlich überwachen, Schwachstellen proaktiv identifizieren und beheben und eine robuste Verteidigung gegen sich entwickelnde Cyber-Bedrohungen aufrechterhalten.
6. Ökobilanz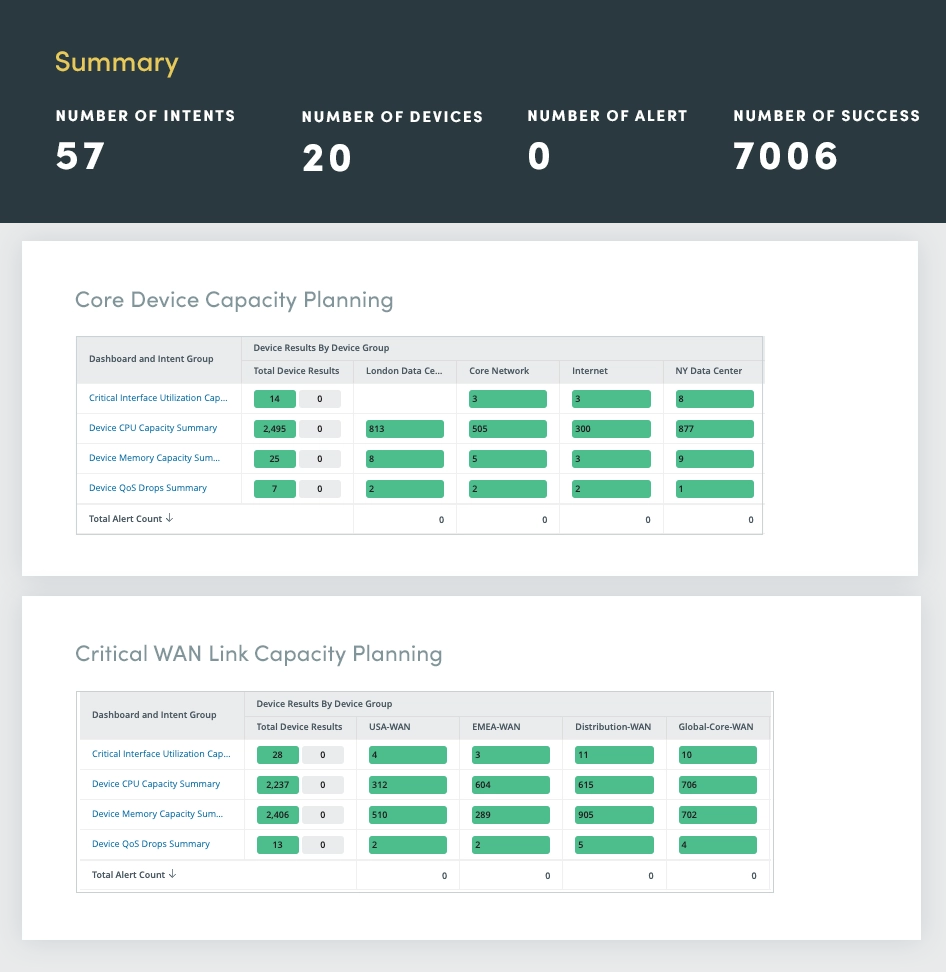
Eine umfassende Lebenszyklusanalyse kann Ihnen helfen, über den Lebenszyklusstatus Ihrer Netzwerkhardware informiert zu bleiben und zeitnahe Upgrades und Ersatzentscheidungen sicherzustellen.
Durch die Nutzung automatisierter API-Aufrufe an Hardwareanbieter wie Cisco erhalten Sie Echtzeitinformationen über:
- End-of-Life-Status (EOL).
- Wartungsstatus:
- Servicevertragsstatus
- Garantiehinweise
Treffen Sie fundierte Entscheidungen zum Hardware-Lebenszyklusmanagement und optimieren Sie Ihr Netzwerk im Hinblick auf Leistung, Sicherheit und Kosteneffizienz.
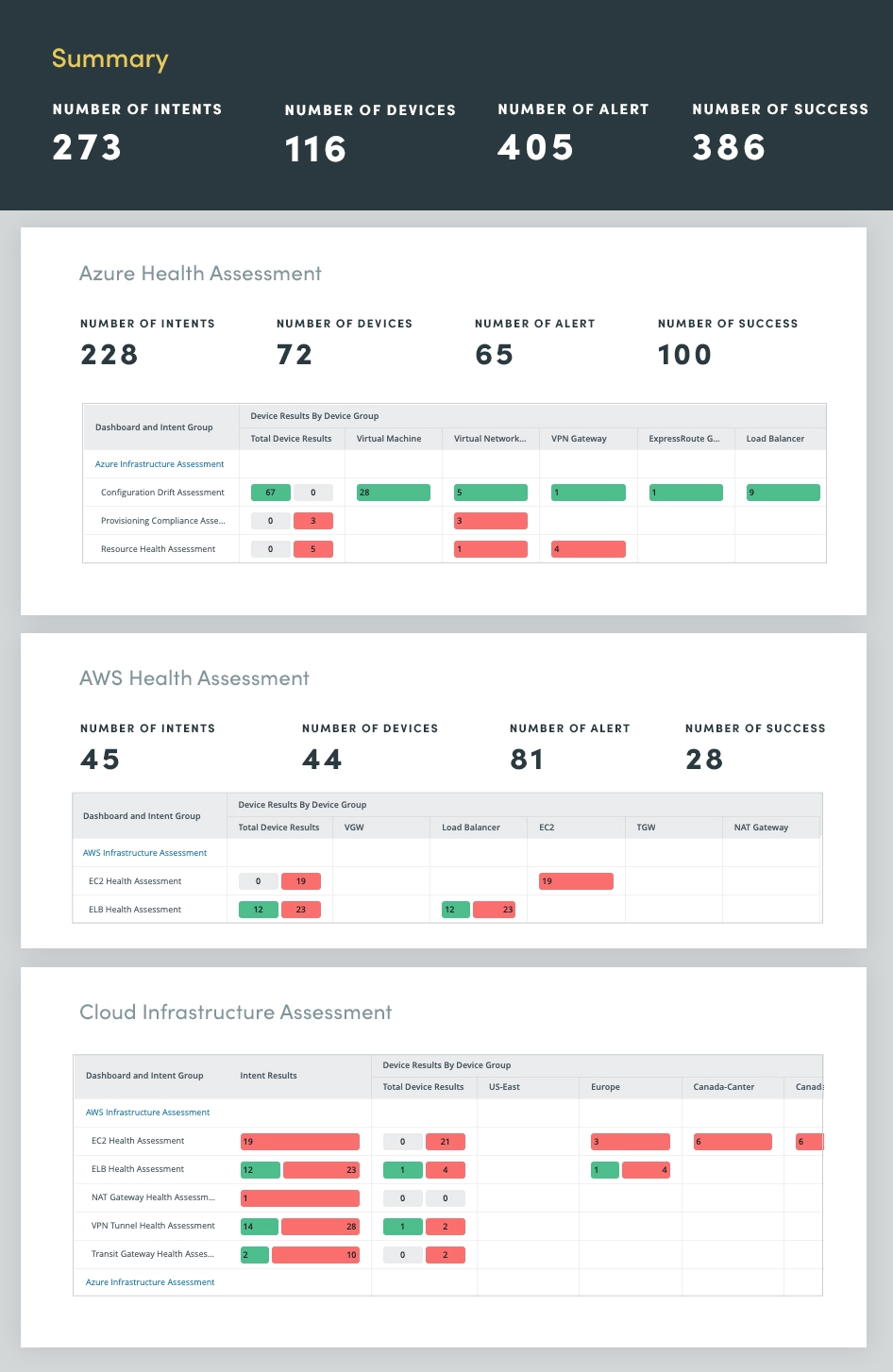
7. Bewertung des Hybrid-Cloud-Netzwerks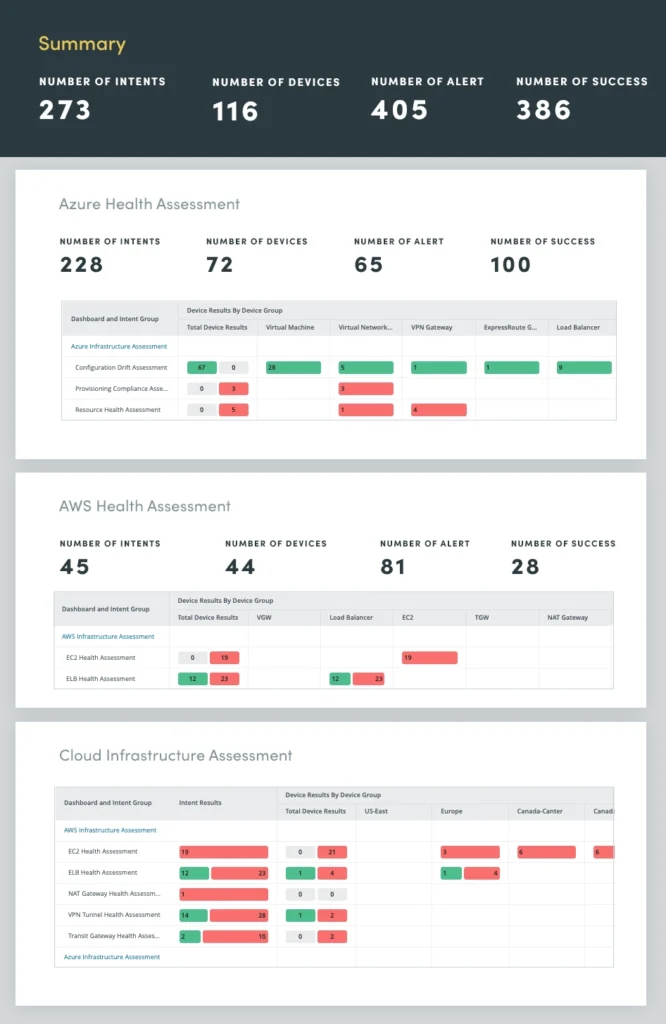
Durch die Automatisierung der Hybrid-Cloud-Netzwerkbewertung können Sie Ihre Cloud-Netzwerke bei mehreren Cloud-Anbietern, einschließlich Microsoft Azure, Amazon AWS und Google Cloud, kontinuierlich überwachen und bewerten, um Einblicke in Folgendes zu erhalten:
- Auslastung der Netzwerkressourcen
- Network Connectivity
- Zustand der virtuellen Appliance
- Cloudspezifische Metriken
Durch die kontinuierliche Bewertung des Hybrid-Cloud-Netzwerks können Sie potenzielle Probleme proaktiv identifizieren und beheben, die Leistung optimieren und eine sichere und belastbare Cloud-Infrastruktur aufrechterhalten.
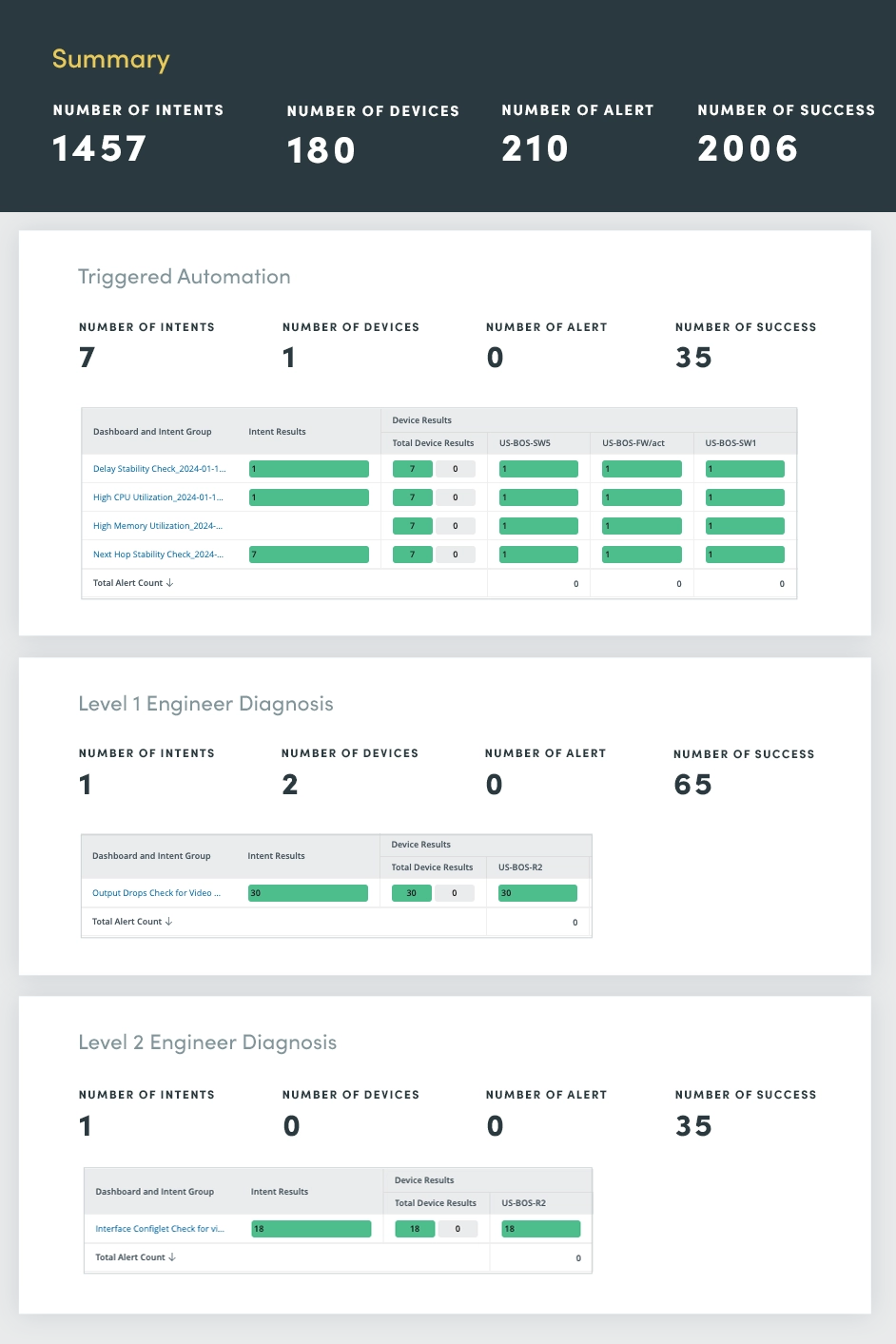
8. Ausgelöste Automatisierung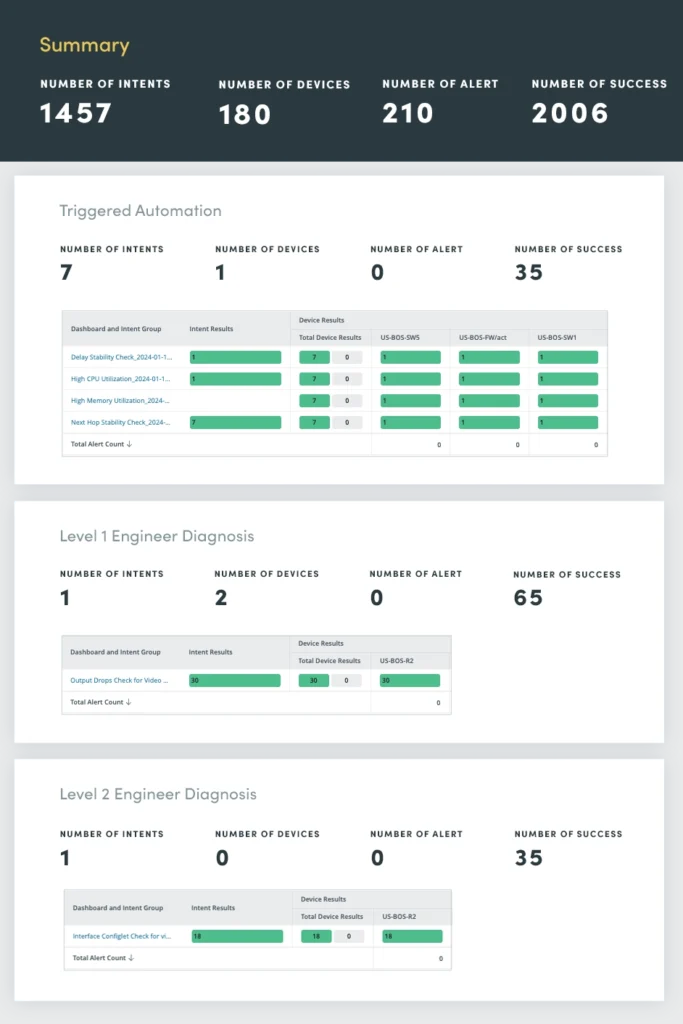
Das Triggered Automation Assessment dient als zentrale Drehscheibe für die Überwachung und Reaktion auf Netzwerkvorfälle in Echtzeit. Durch die Nutzung der Automatisierung können Sie Vorfallmanagementprozesse optimieren und so eine schnelle Diagnose, Priorisierung und Lösung ermöglichen.
Beim Empfang einer eingehenden Vorfallbenachrichtigung über die API wendet das ausgelöste Automatisierungs-Dashboard intelligente Autodiagnosefunktionen an:
- Automatisch schließendes Ticket: Wenn der Vorfall als Lärm identifiziert wird, wird das Ticket automatisch geschlossen, was die Arbeitsbelastung für Netzwerktechniker reduziert und unnötige Eskalationen verhindert.
- Automatisch öffnendes Ticket: Wenn ein Netzwerkproblem festgestellt wird, öffnen Sie automatisch ein Ticket und stellen Sie so sicher, dass der Vorfall umgehend behoben und dokumentiert wird.
- Automatische Priorisierung von Tickets: Wenn ein schwerwiegendes Problem gefunden wird, weisen Sie dem Ticket automatisch eine hohe Priorität zu, um Netzwerktechniker auf die Dringlichkeit der Situation aufmerksam zu machen und ein schnelles Eingreifen zu ermöglichen.
Durch die Automatisierung dieser Aufgaben zur Verwaltung kritischer Vorfälle werden die Reaktionszeiten erheblich verkürzt, Ausfallzeiten minimiert und die allgemeine Ausfallsicherheit des Netzwerks verbessert.
9. Bewertung vergangener Ausfälle
Treten bekannte Probleme erneut auf? Bewerten Sie nach einem Netzwerkausfall alle ähnlichen Probleme in Ihrem Netzwerk. Könnte jedes Problem, das zuvor in Ihrem Netzwerk aufgetreten ist, in einem anderen Teil Ihres Netzwerks erneut auftreten?
Es könnte. Wenden Sie problembasierte Bewertungen in Ihrem gesamten Netzwerk an und überwachen Sie die Ergebnisse kontinuierlich. Um künftige Ausfälle wirksam zu verhindern, müssen Unternehmen nach dem Ausfall gründliche Bewertungen durchführen, die Grundursachen früherer Vorfälle analysieren und potenzielle Schwachstellen identifizieren, die zu ähnlichen Problemen führen könnten.
Durch die Analyse vergangener Ausfälle können Unternehmen:
- Identifizieren Sie wiederkehrende Muster und zugrunde liegende Faktoren, die zu Netzwerkausfällen beitragen, und ermöglichen Sie so gezielte Abhilfestrategien.
- Entdecken Sie versteckte Schwachstellen oder Fehlkonfigurationen, die bei ersten Bewertungen möglicherweise übersehen wurden, und verhindern Sie so zukünftige Ausfälle.
- Implementieren Sie vorbeugende Maßnahmen und stärken Sie die Ausfallsicherheit der Netzwerkinfrastruktur, um ein erneutes Auftreten zu reduzieren.
Indem Sie frühere Probleme proaktiv angehen und daraus lernen, können Sie die Widerstandsfähigkeit Ihres Netzwerks erheblich verbessern und Ihr Ausfallrisiko minimieren.
10. Kapazitätsbewertung
Wissen Sie, ob die Bandbreite Ihres Netzwerks knapp wird? Eine kontinuierliche Kapazitätsbewertung kann das Risiko einer Über- und Unterauslastung in allen Netzwerken verringern.
Durch die kontinuierliche Überwachung und Analyse von Netzwerkverkehrsmustern, Ressourcennutzung und Leistungsmetriken können Sie wertvolle Einblicke in den Netzwerkkapazitätsbedarf gewinnen und potenzielle Probleme proaktiv angehen, bevor sie sich auf Benutzer auswirken oder Geschäftsprozesse stören.
Ermöglichen Sie proaktive Planungs- und Skalierungsstrategien, indem Sie zukünftige Kapazitätsanforderungen vorhersehen, um kostspielige reaktive Maßnahmen zu vermeiden, indem Sie diese Schlüsselkennzahlen überwachen:
- Bandbreitennutzung: Überwacht den Prozentsatz der genutzten verfügbaren Bandbreite und weist auf mögliche Überlastungspunkte hin.
- Geräteressourcenauslastung: Verfolgt die Auslastung von CPU, Speicher und anderen Ressourcen auf Netzwerkgeräten und identifiziert potenzielle Engpässe.
- Anwendungsleistungsmetriken: Bewerten Sie die Leistung kritischer Anwendungen unter unterschiedlichen Netzwerkbedingungen und heben Sie mögliche Kapazitätsbeschränkungen hervor.
Treffen Sie fundiertere Entscheidungen, um die Leistung zu optimieren und Skalierbarkeit sicherzustellen.
Automatisierung hält die Antworten für stc bereit
Das Rechenzentrum und die Designteams von stc nutzen NetBrainRegelmäßige Netzwerkbewertungen für Anwendungsleistungs-Gesundheitsprüfungen, geschützt change managementund proaktive Infrastrukturüberwachung. Lesen Sie die vollständige Fallstudie.
No-Code-Netzwerkautomatisierung verwandelt die traditionelle Netzwerkbewertung von einer veralteten prüfungsbezogenen Aufgabe in ein strategisches Echtzeit-Betriebstool, das Betriebsteams jeden Tag unterstützt. Bewerten Sie die Netzwerkleistung proaktiv mit automatisierten Diagnosen und Erkenntnissen, sodass Sie potenzielle Probleme erkennen und beheben können, bevor sie sich auf den Geschäftsbetrieb auswirken. Kontinuierliche Netzwerkbewertungen bieten einen umfassenden Überblick über die Echtzeit-Betriebsbedingungen Ihres Netzwerks.
 by
by