De top 5 netwerkondersteuningstickets om te automatiseren
Wat frustreert u het meest aan netwerkondersteuning? Niets voelt beter dan detective spelen over een obscuur netwerkprobleem en de IT-held zijn die het oplost. Maar te veel...

Downtime is duur. Meer dan de helft (54%) van de respondenten van de datacenterenquête van het Uptime Institute uit 2023 zegt dat hun meest recente significante, ernstige of ernstige storing meer dan $100,000 heeft gekost, terwijl 16% zegt dat hun meest recente storing meer dan $1 miljoen heeft gekost.
De zinsnede uit de film Apollo 13, ‘Falen is geen optie’, is een van de meest herkenbare filmslogans aller tijden.

Bij netwerkoperaties is het dezelfde mentaliteit. Geld en reputatie staan op het spel. Falen is geen optie.
Uit gegevens van het Uptime Institute blijkt dat er jaarlijks gemiddeld tien tot twintig spraakmakende IT-storingen of datacentergebeurtenissen wereldwijd plaatsvinden die ernstige of ernstige financiële verliezen, bedrijfs- en klantenverstoring, reputatieverlies en, in extreme gevallen, verlies van data veroorzaken. leven.
Dus waarom zijn we nog steeds zo kwetsbaar, gezien alle redundantienetwerken die erin zijn ingebouwd? Waarom blijven we zo sterk afhankelijk van handmatige processen en reactieve probleemoplossing? Netwerkingenieurs besteden talloze uren aan het leggen van de basis voor de dienstverlening, maar er vindt weinig of geen regelmatige handhaving plaats. Pas als er een probleem wordt gemeld, worden de problemen voor het oplossen van problemen (langzaam) in beweging gezet.
Het antwoord is: dat zijn we niet pro-actief genoeg. Dit komt door een gebrek aan focus op de netwerkautomatiseringsindustrie. We laten dezelfde problemen keer op keer voorkomen als we weten hoe we ze moeten oplossen, omdat we simpelweg niet over de mechanismen beschikken om deze kennis automatisch te benutten en toe te passen op hybride netwerken.
Een grote storing zorgt voor verandering bij Saudi Telecom (stc)
In 2021 kreeg een kritieke applicatie bij stc te maken met een grote serviceonderbreking. Het kostte bijna een maand om problemen op te lossen bij netwerkoperaties, servers, applicaties en beveiligingsteams om de oorzaak te achterhalen en de service te herstellen. Deze kostbare storing onderstreepte de noodzaak van een beter inzicht en een meer strategische benadering van incidentbeheer. Als gevolg hiervan drong de Group CTO van stc aan op een organisatiebrede oplossing die end-to-end zichtbaarheid biedt en incidentbeheer in de infrastructuur en applicaties automatiseert.
Stelt u zich eens voor dat u de expertise van uw technici vastlegt en deze proactief toepast op uw hele netwerk, zonder codering. Netwerkautomatisering zorgt ervoor dat netwerkoperaties sneller kunnen reageren, maar is nog niet geavanceerd genoeg (spoiler alert: tot vandaag) om die kennis op een eenvoudige manier proactief over het hele netwerk toe te passen. Wat als we de enorme kennis van onze netwerkingenieurs zouden kunnen benutten en deze zouden kunnen opslaan voor gebruik door een automatiseringsplatform?
Elke dag zijn er netwerkoperatieteams schatten het netwerk voor drift, compliance, gezondheid en verandering handmatig. Wat als ingenieurs deze beoordelingen regelmatig zouden kunnen doen met behulp van automatisering?
Netwerkautomatisering heeft zich nu snel ontwikkeld, waardoor het continu de bedrijfsomstandigheden van een netwerk kan beoordelen zonder ontwikkelingscycli. NetBrain heeft een reeks van de meest voorkomende beoordelingen opgesteld die bedrijfsnetwerkactiviteiten nodig hebben om uitvalbestendige operaties te garanderen. Het automatiseringsplatform zonder code zorgt er echter voor dat netwerkbewerkingen niet beperkt zijn tot een eindige reeks beoordelingen. Zonder hulpmiddelen toe te voegen, kunt u eenvoudig op deze sjablonen voortbouwen en uw systeem van continue evaluaties creëren voor uw unieke netwerkbehoeften. En jij kan visualiseer en deel netwerkbrede beoordelingsresultaten via op widgets gebaseerde overzichtsdashboards.
Laten we eens kijken naar de top 10 van netwerkbeoordelingen die uitval voorkomen en zien hoe NetBrain kan deze in enkele minuten maken.
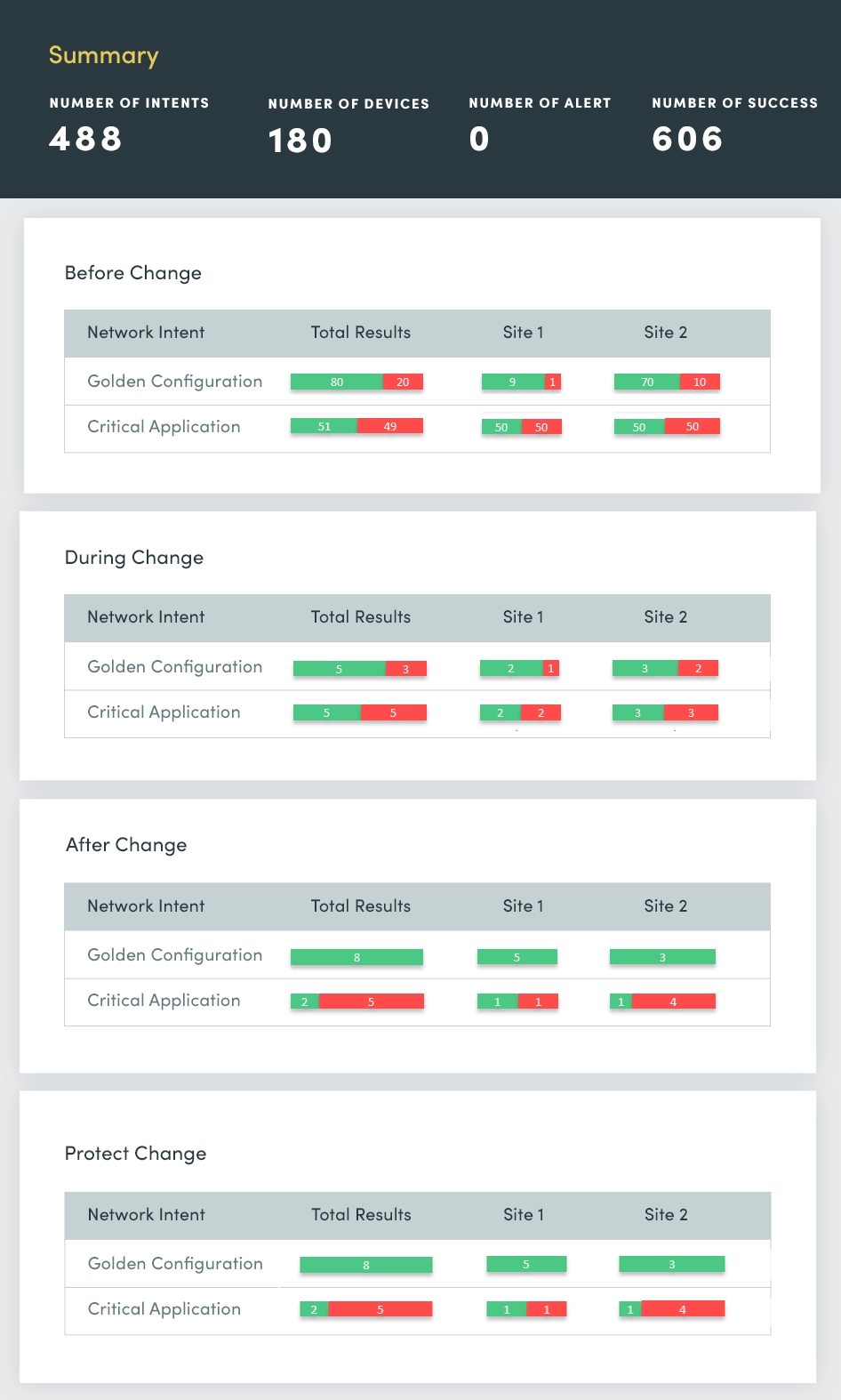
Aan het begin van elke week zijn er berichten over netwerkstoringen die de vraag oproepen: wat is er dit weekend veranderd en waar hebben deze veranderingen plaatsgevonden? U moet deze netwerkveranderingen sneller identificeren en controleren of ze een gemeenschappelijke oorsprong hebben, zodat u ze snel kunt aanpakken en oplossen om de stabiliteit van het netwerk te garanderen en verstoringen tot een minimum te beperken.
Met een Change Assessment evalueer en vat je continu samen:
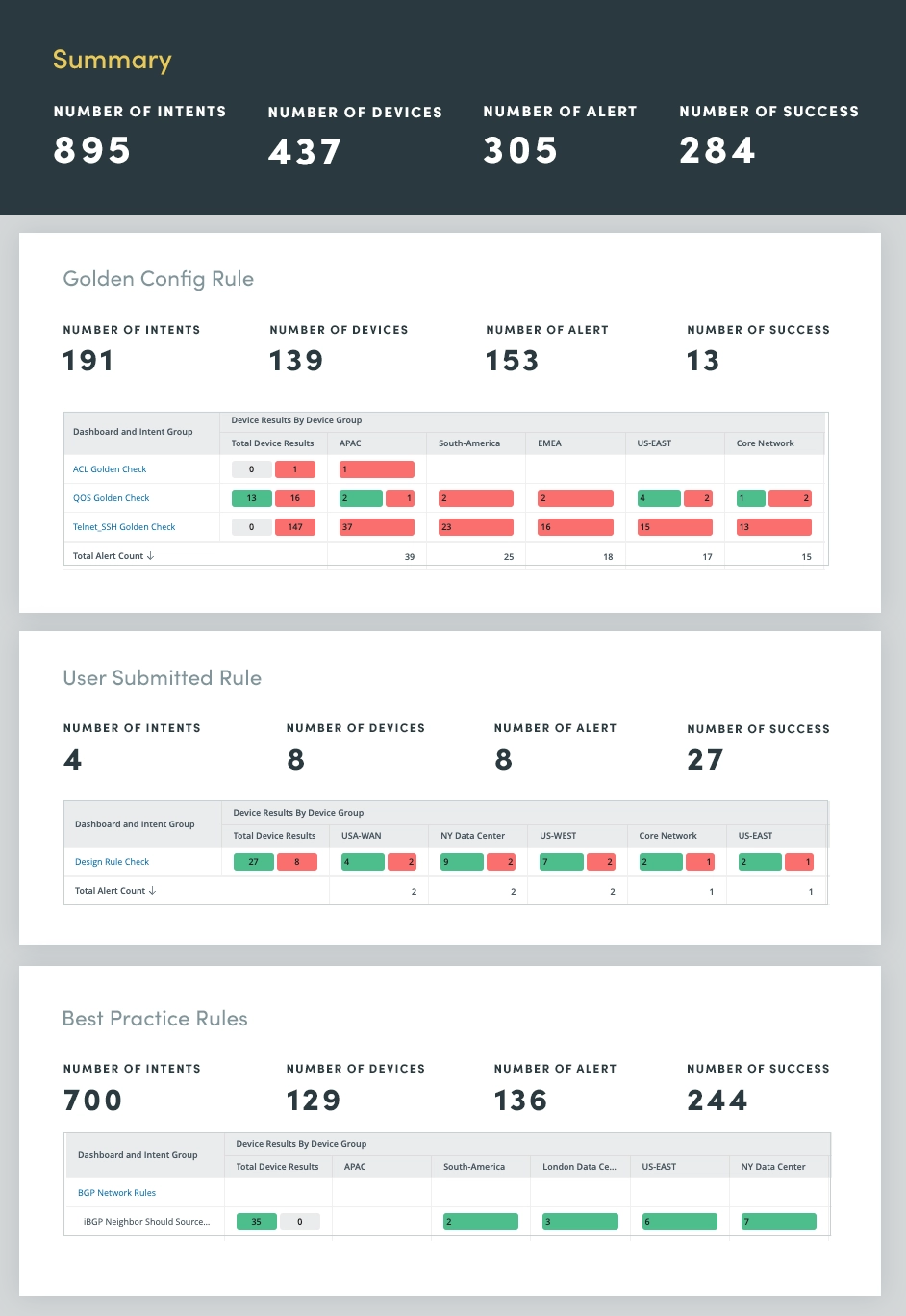
Menselijke fouten, die vaak voortkomen uit handmatige netwerkwijzigingen, zijn een belangrijke oorzaak van netwerkstoringen. Om dit aan te pakken, kunt u een netwerk Anti-drift Assessment gebruiken om afwijkingen van gevestigde configuratieregels en best practices te identificeren. Door de handhaving van deze regels te automatiseren, kunt u het aantal menselijke fouten aanzienlijk verminderen en de netwerkstabiliteit waarborgen.
De Anti-drift Assessment omvat drie regelcategorieën:
Door de handhaving van deze regels te automatiseren, kunt u configuratieafwijking effectief voorkomen en het risico op menselijke fouten minimaliseren. Deze proactieve aanpak verbetert niet alleen de netwerkstabiliteit, maar verbetert ook de algehele netwerkprestaties en beveiliging.
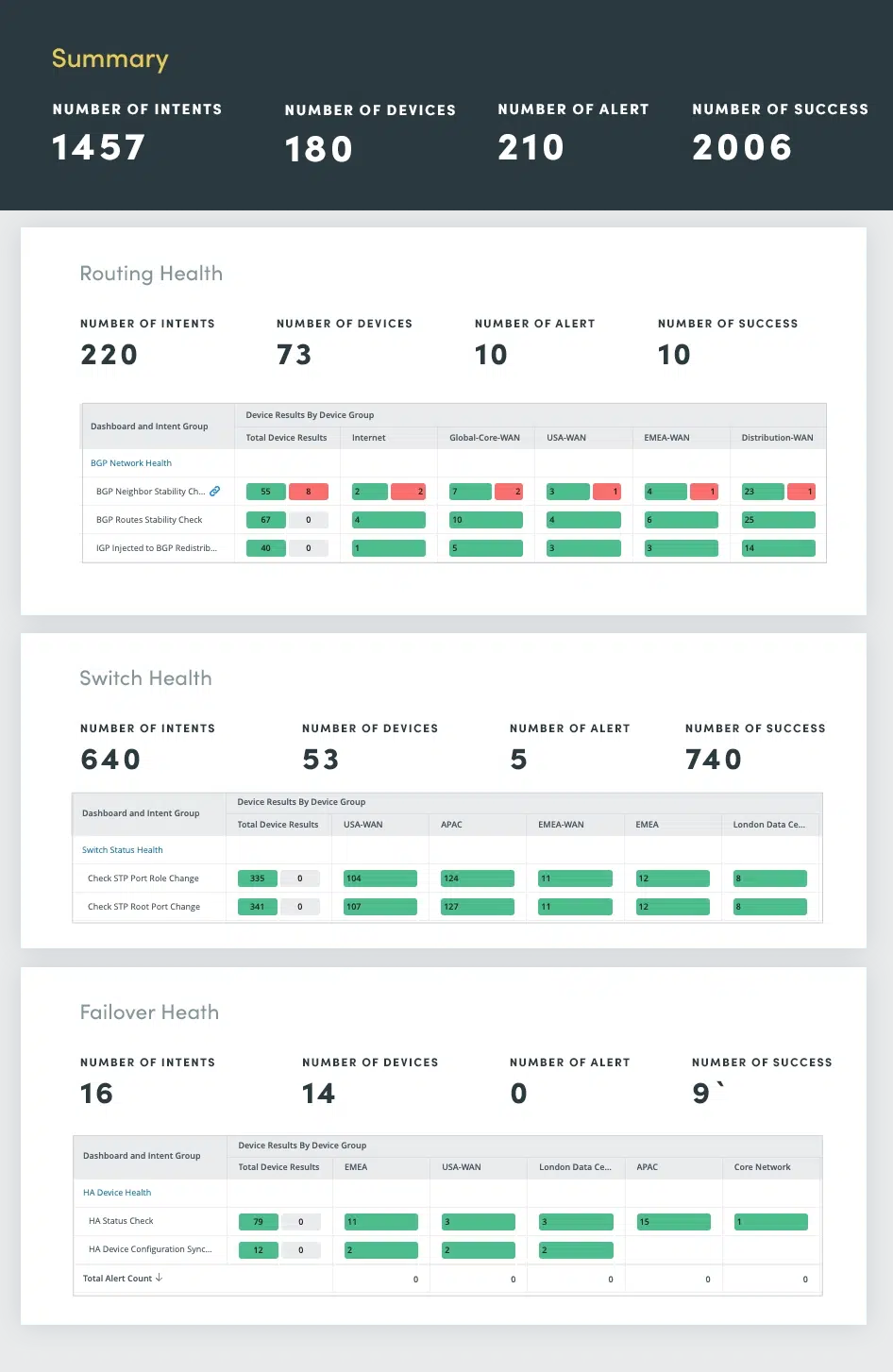
Geavanceerde netwerkredundantie zorgt voor betrouwbare en krachtige connectiviteit. Deze functies kunnen echter, als ze niet goed worden gecontroleerd en onderhouden, een bron van potentiële problemen worden. Continue netwerkgezondheidsbeoordeling speelt een cruciale rol bij het identificeren en aanpakken van potentiële problemen voordat deze escaleren tot grote storingen.
Netwerkgezondheidsbeoordeling omvat een uitgebreide evaluatie van routerings-, schakel-, failover-, VPN-, draadloze en foutlogboeken.
Door deze kritieke netwerkcomponenten voortdurend te beoordelen, kunt u potentiële problemen proactief identificeren en oplossen, waardoor optimale netwerkprestaties, beschikbaarheid en beveiliging worden gegarandeerd.
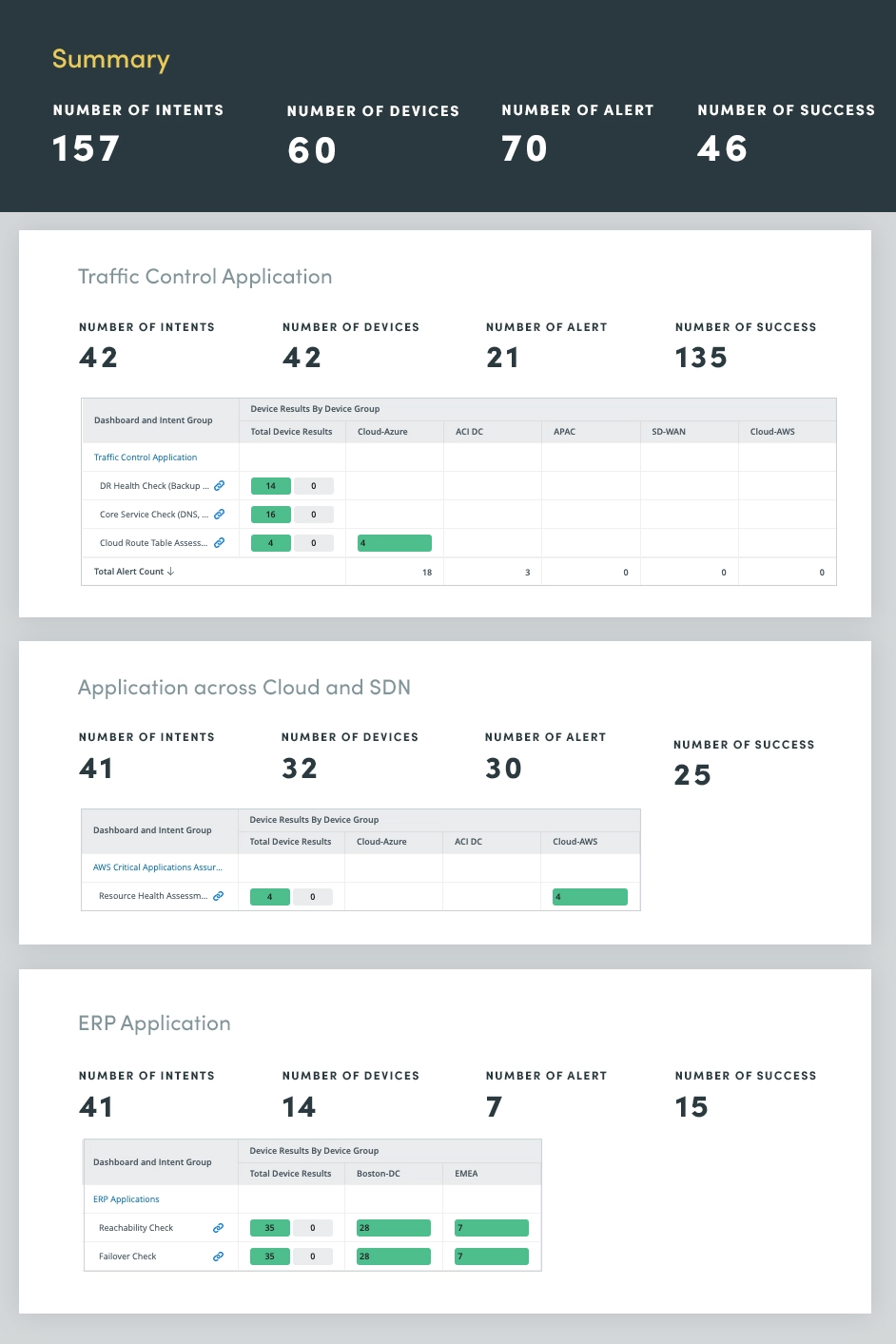
Door de gezondheid van bedrijfskritische applicaties voortdurend te monitoren en te evalueren, kunt u potentiële problemen identificeren en aanpakken voordat ze gevolgen hebben voor gebruikers of bedrijfsprocessen verstoren. Deze proactieve aanpak helpt kostbare storingen te voorkomen, de applicatieprestaties te optimaliseren en de algehele systeembetrouwbaarheid te verbeteren.
Applicatiegezondheidsbeoordeling omvat een uitgebreide evaluatie van verschillende applicatiestatistieken en -componenten, waaronder CPU- en geheugencapaciteit, QoS-dalingen, kritisch interfacegebruik en taken zoals loganalyse en gebeurtenismonitoring om potentiële applicatieproblemen proactief te identificeren en aan te pakken.
Door deze kritische applicatiestatistieken voortdurend te beoordelen, kunt u waardevolle inzichten verkrijgen in de status van applicaties, waardoor u de prestaties kunt optimaliseren, uitval kunt voorkomen en een positieve gebruikerservaring kunt behouden.
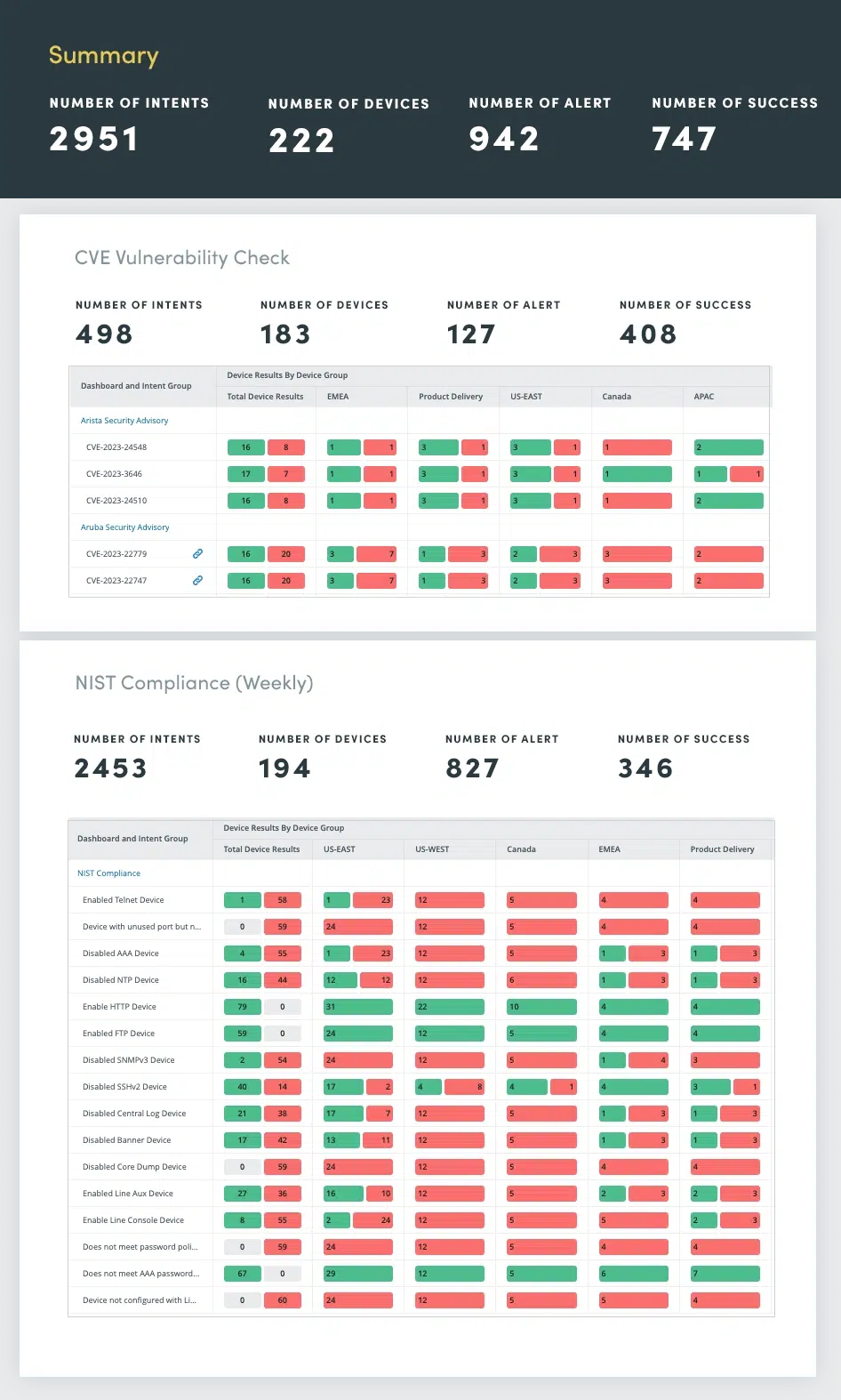
Zorg ervoor dat uw netwerk niet kwetsbaar is volgens NIST Standard en CVE Bulletins. Van beveiligingsnaleving tot aanbevelingen van leveranciers: beoordeel eventuele kwetsbaarheden en los deze op voordat er zich problemen voordoen. Regelmatige netwerkbeveiligingsbeoordelingen zijn essentieel om kwetsbaarheden te identificeren en aan te pakken die gevoelige gegevens in gevaar kunnen brengen, de bedrijfsvoering kunnen verstoren of de reputatie van een organisatie kunnen schaden.
Netwerkbeveiligingsbeoordelingen omvatten een uitgebreide evaluatie van verschillende beveiligingsaspecten, waaronder:
Door deze beveiligingsbeoordelingen te automatiseren, kunt u voortdurend de netwerkstatus monitoren, kwetsbaarheden proactief identificeren en aanpakken, en een robuuste verdediging tegen evoluerende cyberdreigingen onderhouden.
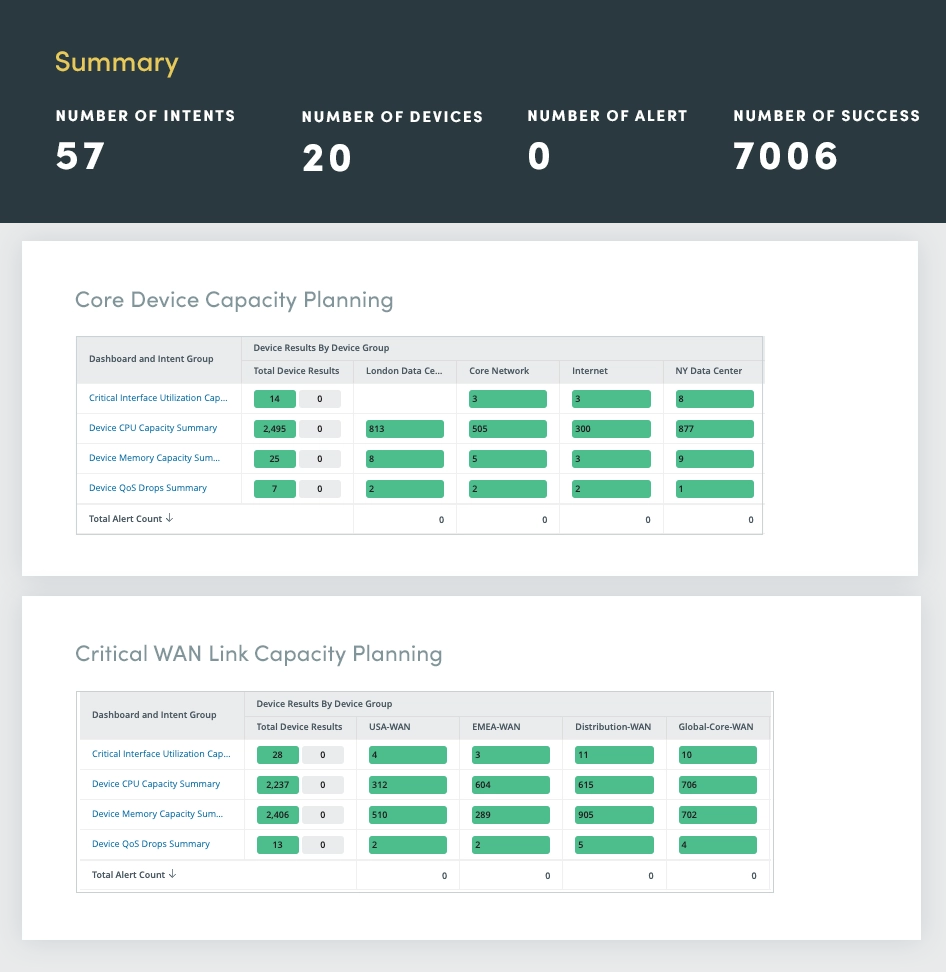
Een uitgebreide levenscyclusanalyse kan u helpen op de hoogte te blijven van de levenscyclusstatus van uw netwerkhardware, waardoor tijdige upgrades en vervangingsbeslissingen worden gegarandeerd.
Door gebruik te maken van geautomatiseerde API-oproepen naar hardwareleveranciers, zoals Cisco, krijgt u realtime informatie over:
Neem weloverwogen beslissingen over het beheer van de hardwarelevenscyclus en optimaliseer hun netwerk voor prestaties, beveiliging en kosteneffectiviteit.
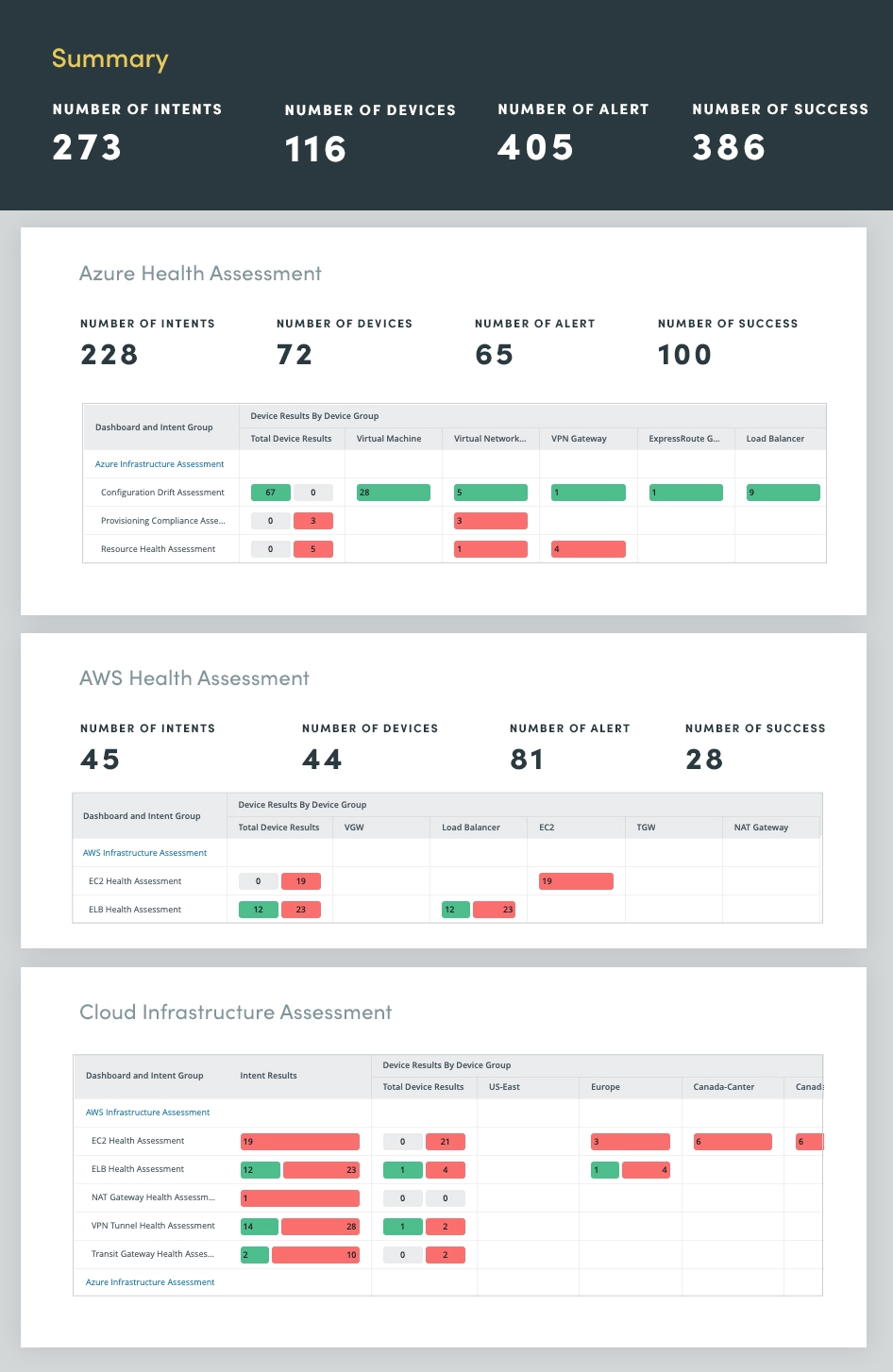
Door automatisering toe te passen op de beoordeling van hybride cloudnetwerken, kunt u uw cloudnetwerken bij meerdere cloudproviders, waaronder Microsoft Azure, Amazon AWS en Google Cloud, voortdurend monitoren en beoordelen voor inzicht in:
Door het hybride cloudnetwerk voortdurend te beoordelen, potentiële problemen proactief te identificeren en aan te pakken, de prestaties te optimaliseren en een veilige en veerkrachtige cloudinfrastructuur te onderhouden.
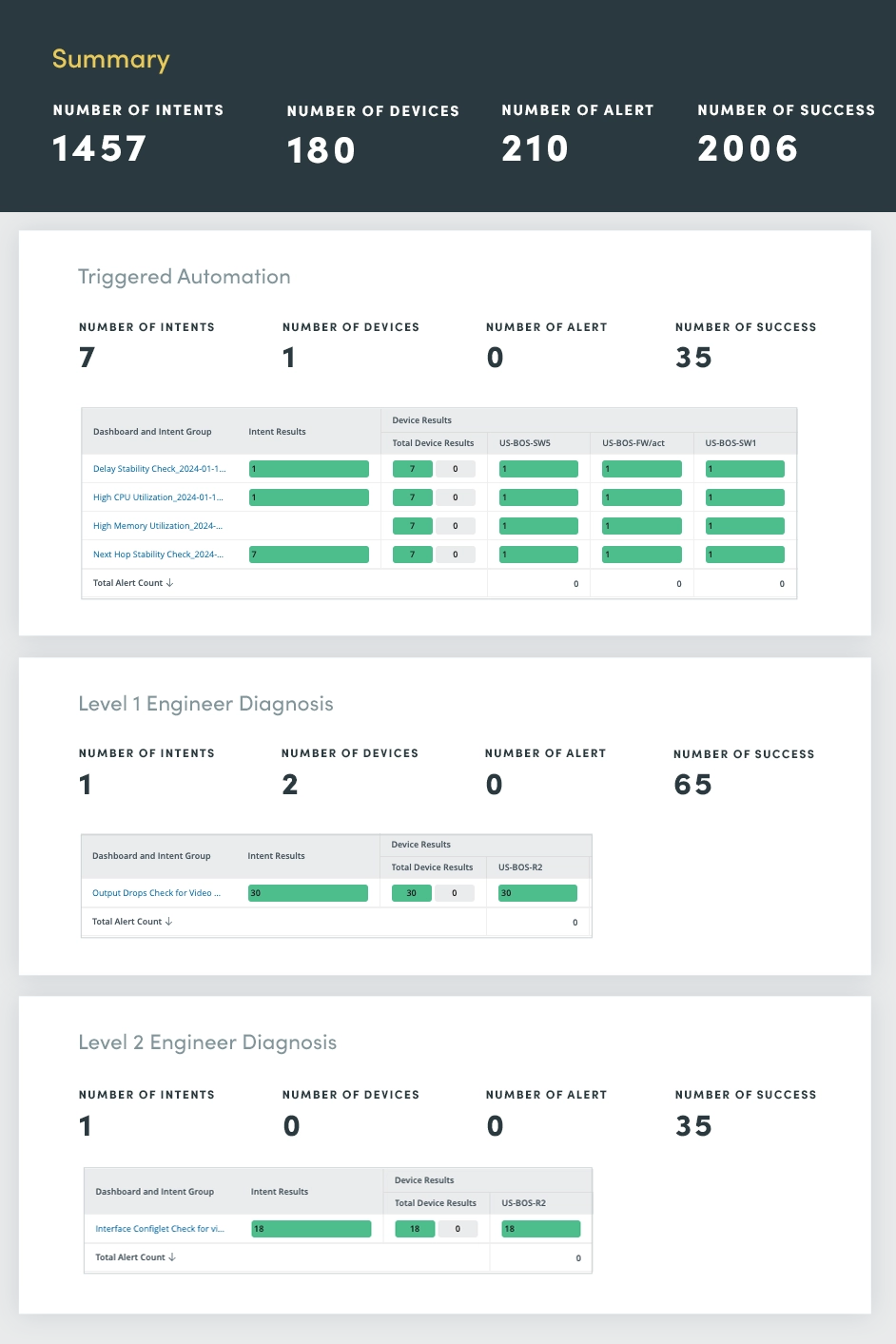
De Triggered Automation Assessment fungeert als een gecentraliseerde hub voor het in realtime monitoren van en reageren op netwerkincidenten. Door de kracht van automatisering te benutten, stroomlijnt u incidentbeheerprocessen, waardoor snelle diagnose, prioritering en oplossing mogelijk worden.
Bij ontvangst van een inkomende incidentmelding via API, past het geactiveerde automatiseringsdashboard intelligente automatische diagnosemogelijkheden toe:
Het automatiseren van deze kritieke incidentbeheertaken verkort de responstijden aanzienlijk, minimaliseert de downtime en verbetert de algehele veerkracht van het netwerk.
Doen bekende problemen zich opnieuw voor? Na een netwerkstoring moet u eventuele vergelijkbare problemen in uw netwerk beoordelen. Kan elk probleem dat zich eerder in uw netwerk voordeed, zich opnieuw voordoen in een ander deel van uw netwerk?
Het zou kunnen. Pas probleemgebaseerde assessments toe binnen uw netwerk en monitor de resultaten continu. Om toekomstige storingen effectief te voorkomen, moeten organisaties grondige beoordelingen na de storing uitvoeren, waarbij de hoofdoorzaken van incidenten uit het verleden worden geanalyseerd en potentiële kwetsbaarheden worden geïdentificeerd die tot soortgelijke problemen kunnen leiden.
Door eerdere storingen te analyseren kunnen organisaties:
Door problemen uit het verleden proactief aan te pakken en ervan te leren, kunt u de veerkracht van het netwerk aanzienlijk vergroten en het risico op uitval minimaliseren.
Weet u of uw netwerk onvoldoende bandbreedte heeft? Continue capaciteitsbeoordeling kan het risico van over- en onderbenutting binnen netwerken verminderen.
Door continue monitoring en analyse van netwerkverkeerspatronen, resourcegebruik en prestatiestatistieken te verzamelen, kunt u waardevolle inzichten verkrijgen in de eisen aan de netwerkcapaciteit en potentiële problemen proactief aanpakken voordat deze gevolgen hebben voor gebruikers of bedrijfsprocessen verstoren.
Maak proactieve plannings- en schaalstrategieën mogelijk door te anticiperen op toekomstige capaciteitsbehoeften en dure reactieve maatregelen te vermijden door deze belangrijke statistieken te monitoren:
Neem beter geïnformeerde beslissingen om de prestaties te optimaliseren en schaalbaarheid te garanderen.
Automatisering biedt de antwoorden voor stc
stc's datacenter en ontwerpteams gebruiken NetBrain's netwerkbeoordelingen regelmatig voor de gezondheidscontroles van applicatieprestaties, beschermd change managementen proactieve infrastructuurmonitoring. Lees de volledige casestudy.
No-code netwerkautomatisering transformeert de traditionele netwerkbeoordeling van een verouderde auditgerelateerde taak naar een strategische realtime operationele tool die operationele teams elke dag meer mogelijkheden biedt. Beoordeel de netwerkprestaties proactief met geautomatiseerde diagnostiek en inzichten, zodat u potentiële problemen kunt identificeren en aanpakken voordat deze van invloed zijn op de bedrijfsvoering. Continue netwerkbeoordelingen bieden een uitgebreid beeld van de realtime bedrijfsomstandigheden van uw netwerk.