What Happens After BGP?
Gaining Full Path Visibility in Hybrid Cloud Networks In the modern enterprise, Border Gateway Protocol (BGP) plays a foundational role in connecting distributed networks. It is the routing protocol that...

Last week, I discussed 6 of the most common use cases for automation that NetBrain customers have implemented in their networking environments. Using Runbooks, clients have been able to eliminate the overhead of integrating ticketing systems with their IT workflow, collecting and escalating information to higher tier engineers, operationalizing best practices, executing CLI commands in batches, and troubleshooting multi-tier issues.
However, let’s dive in this week to 4 use cases that might not be immediately relevant to the average user – after all, automation is simply a facilitation of an existing process, and while it’s easy to list the common workflows, sometimes it’s important to show the oddball Runbooks and the one-off tasks that you might only encounter once in a blue moon.
In the process of explaining these more advanced workflows, I might need to get a bit technical, but don’t worry – I’ll make sure we don’t get lost in the weeds.
Let’s kick off this list with…
In a nutshell, this Runbook strings together multiple security Qapps and Gapps in order to investigate potential vulnerabilities in your device. Thanks to our robust CLI parser library (the one that lets you execute specific CLI commands en masse across your network), there is a wide range of vendors that this Runbook can support. Simply put, this Runbook performs the following steps:
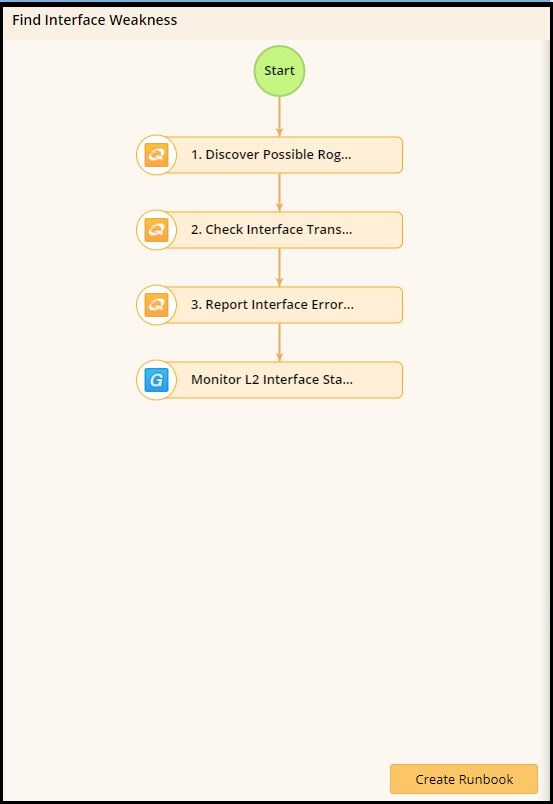
Respectively, this Runbook looks at the following contextual elements of your network:
This automation would be ideal for security professionals attempting to take proactive measures on their network; it’s important to go beyond merely reacting to some kind of breach or incident to truly excel at protecting what’s important to your business goals. As with most preventative measures, this isn’t a process that a user would be performing on a daily basis, but its nonetheless important to see how NetBrain can help you handle the sporadic and one-off workflows that might slow you down when you run into them.
This one is a Cisco-specific task. In modern data centers, uptime is one of the most important factors. With its failover feature, Cisco ASA provides high availability to the network environment to ensure high uptime and resiliency in the face of potential problems. It’s designed to monitor the failover status on individual ASA devices, and retrieve CLI-level configuration info for the user.
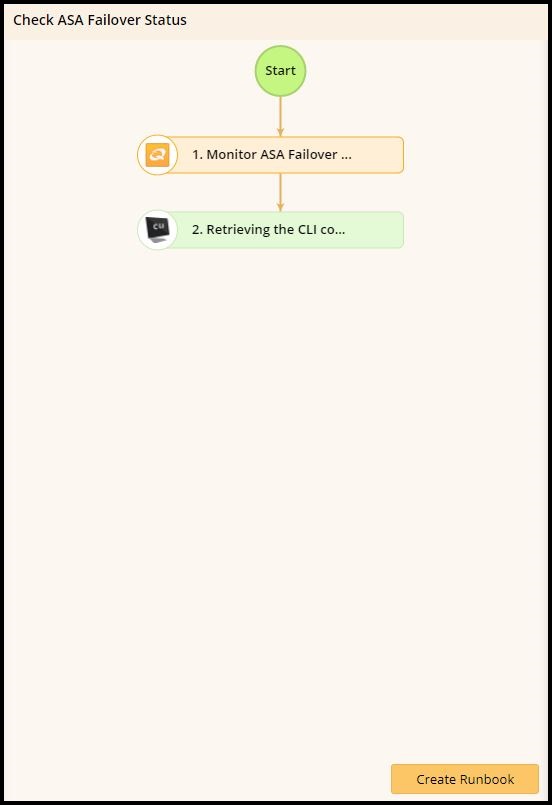
This is a useful, if relatively narrow Runbook that demonstrates how NetBrain can be useful across many different types of networking environments. From SMBs, to data centers and NOCs, NetBrain possesses the appropriate toolset to help you perform your job more easily, even if it’s a bit niche.
This is an interesting two-parter. Troubleshooting multicast is actually made up of two distinct network health checks – one for the shared tree, and one for the source tree.
(Just in case you’re not a network engineer, here’s why multicast is useful.)
Multicast is a one-to-many communication. It allows a single source to send traffic to multiple receivers by using a single multicast address. In context, routing protocols such as OSPF send traffic to multiple routers at the same time in order to conserve device resources and address space. It’s different than a broadcast, which is intended for all devices on a particular domain to receive, while multicast allows more granularity in regards to who receives it.
(For example, conference applications like Webex often use multicast, not to mention streaming applications, and financial services among many others.)
The difference between a shared tree and a source tree is slight, but significant when it comes to performance and security.
These distinctions are very important, as engineers don’t necessarily deal with multicast during their day-to-day operations. Troubleshooting multicast is incredibly time consuming, and as you might expect NetBrain has the exact tool to fit your workflow!
The shared tree health check performs the following steps.

Below is an example of the source tree health check.
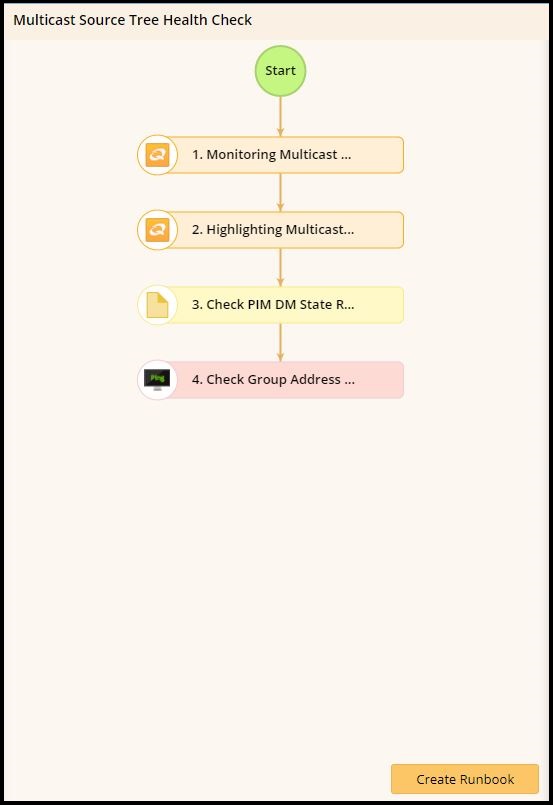
Any engineer that deals with multicast on a daily basis would know the importance of the third bullet, which is Checking PIM Dense Mode State Refresh, which floods multicast traffic to every corner of the network as a brute-force method of delivering data to the receivers. This method is efficient in certain deployments in which there are active receivers on every subnet.
Whew, that was a lot.
Last one!
NIST is a federal compliance standard, so this Runbook goes out to everyone currently dealing with federal clients. I imagine that’s probably a lot of you.
The National Institute of Standards and Technology has developed a regulation that has become a top priority in many high tech industries today. At a glance, a NIST-compliant device needs to be able to perform actions like categorizing data and information that needs to be protected, conducting risk assessments to refine the baseline and roll out security protocols to information systems among other requirements.
And, you guessed it, NetBrain has a Runbook for this too!
Although it’s a left-of-center process that you won’t see every day, you can automatically make your device compliant with the Federal NIST standard by investigating common security vulnerabilities, and visualizing this data on a Dynamic Map. This Runbook lets you
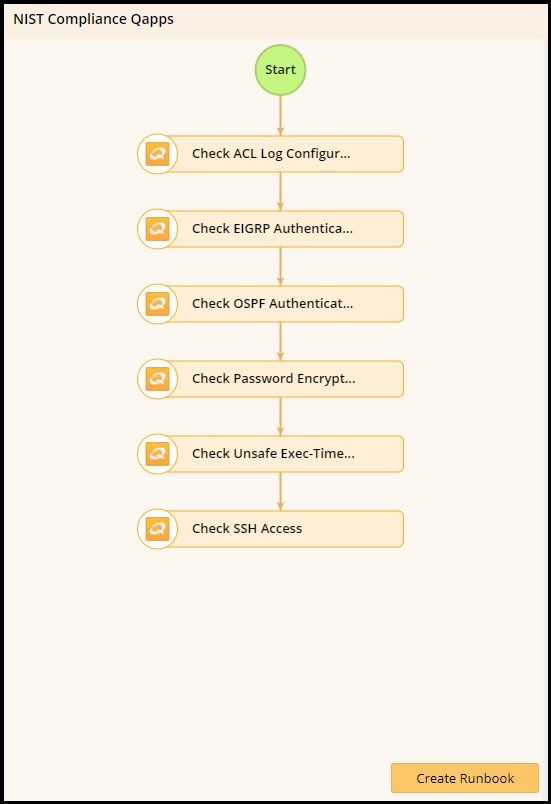
If preparing your devices for a federal compliance check is important to you, it’s good to know that NetBrain can also support these operations as well.
This blog post, as I mentioned before, is meant to show you some of the more intricate features and workflows that NetBrain is capable of. Not everyone is going to be scouting for interface weaknesses, not all of our clients work in data centers with ASA switches, or use multicast on a daily basis.
The point isn’t to be exhaustive – the point is to show you how flexible this amazing software can be for your IT department. With Runbooks, you can achieve automated network operations in a way that saves you time better-spent building and creating rather than troubleshooting and documenting. NetBrain is good for both the common issues as well as the more complex, esoteric problems that you’ll encounter during your day.