What Happens After BGP?
Gaining Full Path Visibility in Hybrid Cloud Networks In the modern enterprise, Border Gateway Protocol (BGP) plays a foundational role in connecting distributed networks. It is the routing protocol that...

I get nervous before major network changes, and my ingrained best-practice methodology seems to go out the window when a change goes wrong. Years of experience has taught me that the solution is thorough planning, accurate testing, and clear rollback procedures. There are just too many things to think about in a network-down situation.
The problem for me is that though I may have a strong understanding of technology, it’s very difficult to know with a high degree of certainty how a change affects an entire network. Understanding the output of commands such as show IP OSPF database, show IP route, and show IP CEF can provide a very skilled engineer with an immediate sense of what the entire OSPF graph looks like. There is certainly a class of networking professionals that can do this, but how can we mere mortals operating large networks paint a mental picture of how OSPF is selecting paths across an entire network?
This kind of thinking doesn’t pertain only to the CCIE exam. In my experience, it’s relevant to the day-to-day network operations of many large organizations. For them, every single OSPF configuration is mission-critical.
Years ago I worked on a global network with geographic locations kept isolated with two egress points into the global network. In some cases, these geographic locations running OSPF represented entire countries, each with dozens of locations and thousands of end users.
For one project I was required to configure routes via one egress to be preferred over the other because the less preferred path was through a site that was being decommissioned. Also, the entire region ran extremely old routers, and one by one they and their links to the ISP were being upgraded. What I had to contend with was an OSPF area with a variety of old hardware and low-speed links and several locations with new hardware and high-speed links.
During my change window, I scanned the OSPF configuration, the routing table on the two ASBRs, and the LSA database. I hardcoded a low OSPF cost on one link and adjusted the reference bandwidth in order to influence how that router calculated its metrics.
When it comes time to changing default timers, link cost, and influencing path selection on many routers at once, configuring even a simple change can become much more complex.
I waited for my various persistent pings and traceroutes to look the way I wanted, but they never did. In fact, it seemed that I created a small crisis.
I forgot that all routers in an OSPF domain must agree on the reference bandwidth because the cost is inversely related to the bandwidth of a link. In my mind, decreasing the cost made the link more preferred, but by changing the reference bandwidth incorrectly, I made the link less preferred.
Behind these two ASBRs was an entire OSPF domain being run by a variety of router platforms. After SPF was recalculated in the area, traffic patterns changed enough that not only was the less preferred egress being used but traffic was being tromboned among several old routers using very low bandwidth links.
Basically, I had no idea what was going on other than the fact that everything was slow and weird. I needed granular real-time visibility before and after my change.
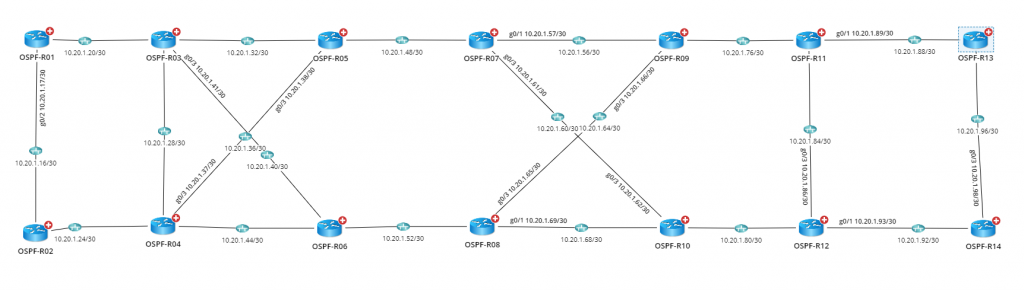 NetBrain Dynamic Maps give you end-to-end visibility of your entire OSPF configuration.
NetBrain Dynamic Maps give you end-to-end visibility of your entire OSPF configuration.
In a very simple network, there isn’t much going on with OSPF other than turning it on an interface and letting SPF do the rest. But when it comes time to changing default timers, link cost, and influencing path selection on many routers at once, configuring even a simple change can become much more complex. Logging into one device at a time to make these sorts of changes means change windows are long, the risk for human error is high, and real-time network visibility is almost non-existent.
This is why I believe network automation is becoming a normal part of how engineers manage networks. A programmatic approach to making several changes to an OSPF config on dozens of routers
The rollback plan for my network change was simple. I removed the cost configuration and reference bandwidth. After bouncing a few interfaces to force SPF to run again, traffic patterns returned to the pre-change-window state.
In my next change window, I gave it another shot but with some changes to my strategy. This time, I changed the reference bandwidth on all the routers in that OSPF area, changed the cost on several interfaces, and modified the description of almost all the interfaces running OSPF in that area and its adjacent area.
The change window needed to be longer because I anticipated longer downtime, and my methods weren’t anything sophisticated. I had snippets of config in Notepad on my left screen, which I copied and pasted into the appropriate terminal windows on my right screen. Thankfully I made only a couple of mistakes putting the wrong config onto the wrong router, and thankfully I didn’t lose connectivity to the devices as a result. But I should have had zero mistakes and a much shorter change window.
NetBrain’s built-in Executable Runbooks make running show commands across many devices at once a matter of a single click of a button. Realistically, a Runbook will have more in it than just one simple show command, though.
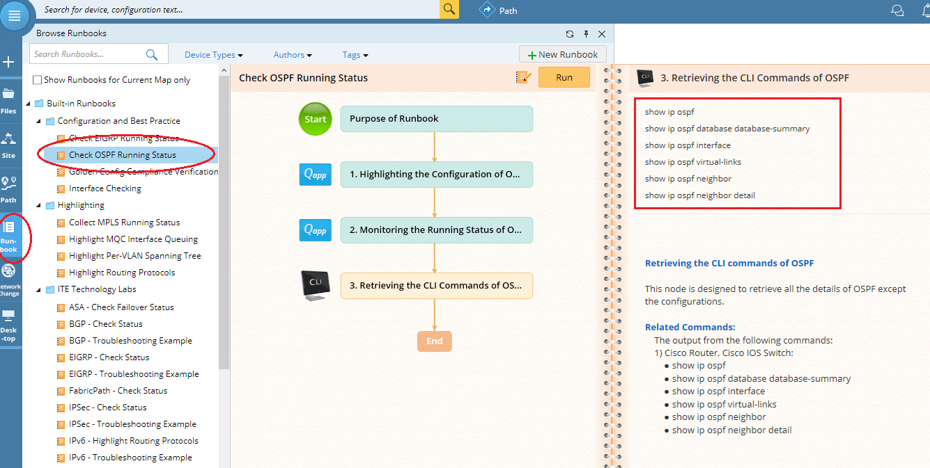
An Executable Runbook checks the current OSPF running status. The command set that the Runbook executes is shown on the right.
The power of NetBrain Runbooks is in how a variety of commands can be run at once or triggered to run automatically. In my case, an Executable Runbook could have been configured with the appropriate show commands to gather a significant amount of OSPF-specific and routing information. With one click, NetBrain would have gathered this information across many devices without the need for me to log into one router at a time.
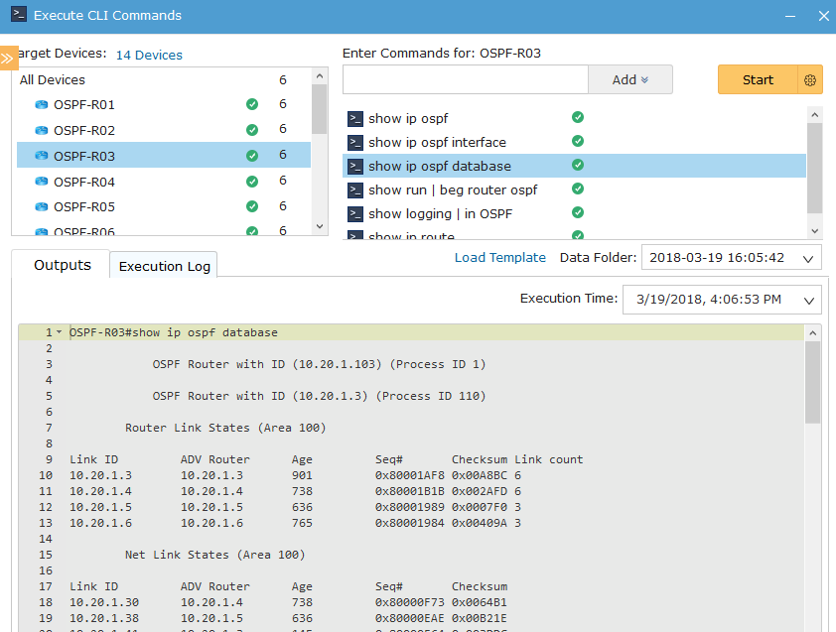
The power of NetBrain Runbooks is in how a variety of commands can be run at once or triggered to run automatically.
Staring at pages of output isn’t really what I needed, though. NetBrain’s Dynamic Network Maps then take that output and represent it in an interactive real-time snapshot of how routing is operating on the network. In this way, I could have immediately seen path selection and clicked on suspect routers.
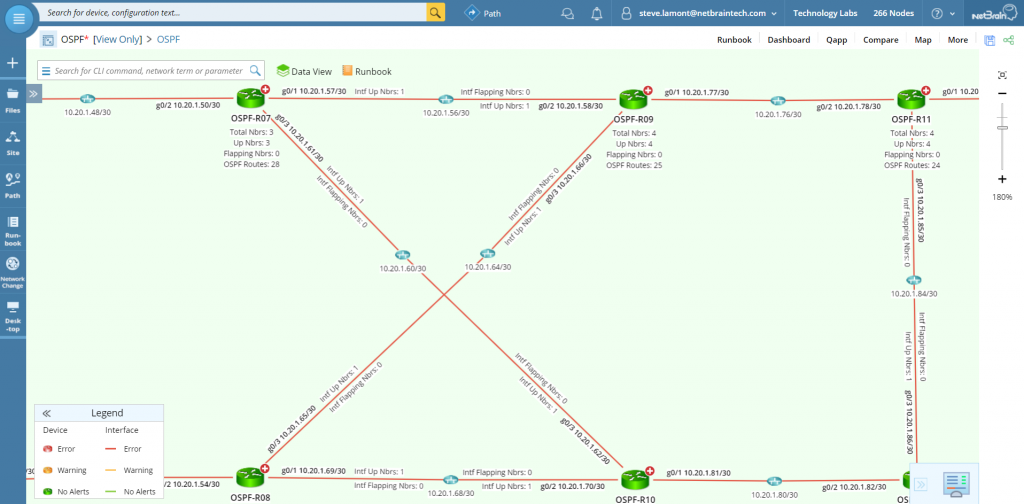 The Runbook highlights the neighbor count and the routes of OSPF and displays it right on the Dynamic Map.
The Runbook highlights the neighbor count and the routes of OSPF and displays it right on the Dynamic Map.
Pushing configuration changes across all devices is relatively easy, but NetBrain provides deep functionality with their Dynamic Maps such as the Path function which graphically presents traffic patterns after each configuration push. And when we need to sanity-check our configs, the Compare function is a built-in diff tool that provides a one-click mechanism to identify differences in configuration among devices.
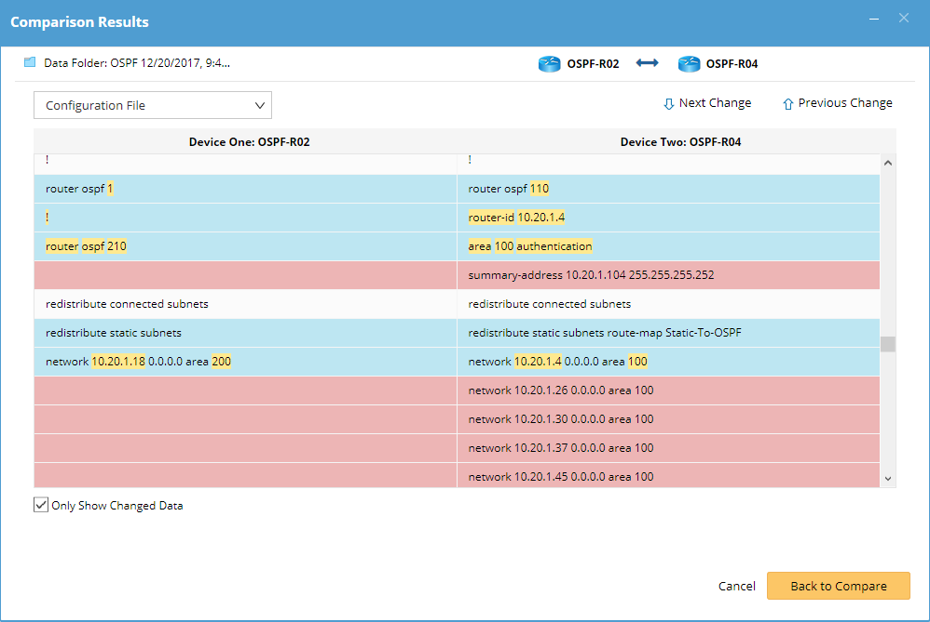 An engineer can immediately see the OSPF configuration differences between routers 2 and 4.
An engineer can immediately see the OSPF configuration differences between routers 2 and 4.
I’m not ashamed to admit that I get anxious before a major network change. However, using a programmatic method to monitor and configure a network both at a device level and holistically helps me move forward with confidence, knowing that I understand exactly how each change affected the network in real time. NetBrain’s Runbook Automation and Dynamic Mapping technologies offer engineers this type of programmable environment to make changes to routing without fear.