DORA: What Financial IT Must Know
The Digital Operational Resilience Act (DORA) entered into application across the European Union on 17 January 2025, reshaping how financial institutions manage cyber and operational risk [1]. Although the United...

Ed. note: The following transcript has been drawn from the on-demand recording — no registration needed or form to fill out — of NetBrain’s Just in Time Automation for IT Operations webinar. Jason Baudreau, NetBrain VP of Marketing, is your host.
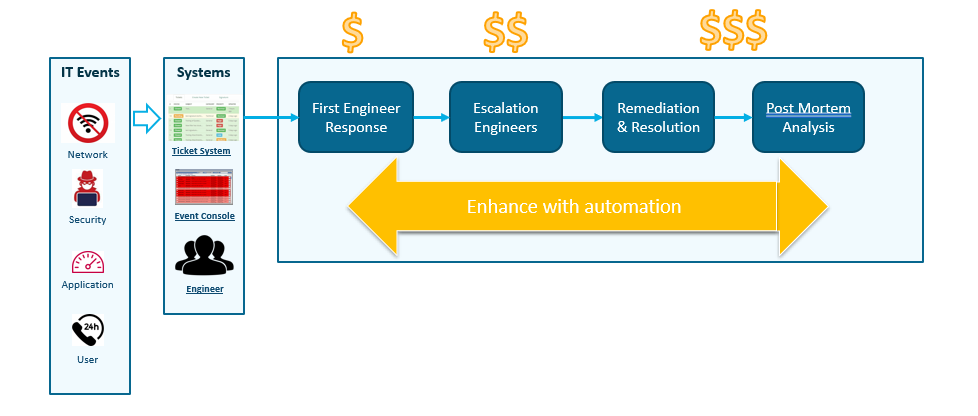
Here’s a view of a typical workflow in response to an IT event — take, for example, a slow application. So enterprise network teams will typically have an event console like SolarWinds or Splunk that’s going to listen and try to detect any anomalies that are occurring in the network. Or maybe it’s just a user calling the help desk to generate a ticket. They’ll have these ticketing systems like ServiceNow or BMC Remedy for incident management.
This problem gets picked up by, usually, a tier 1 engineer. Then if it’s not trivial, it’s going to be escalated to somebody with more expertise who can help solve it. Then there’s the remediation: the actual change or the actual fix that needs to go in place. And finally the teams review what’s happened to see how they can do better next time. This is typically done through a post-mortem analysis–type activity.
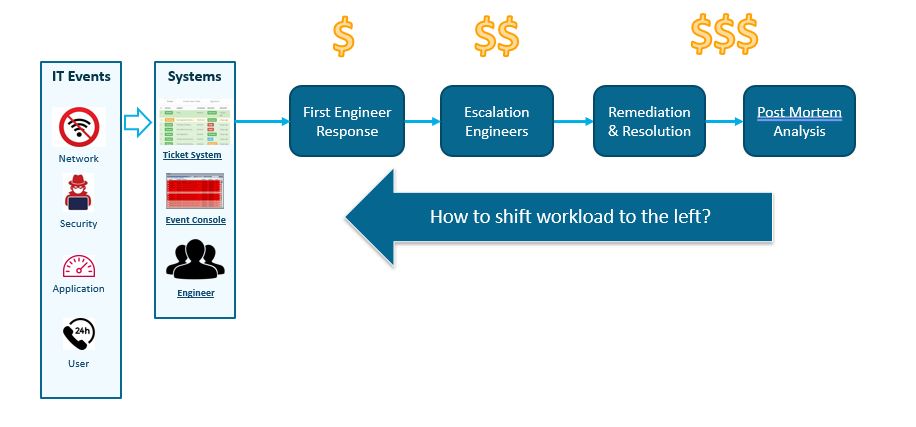
So the question is, What can we do to shift this workflow to the left? Because as this workflow progresses and the issues escalate, the teams involved get more and more expensive.
This workflow can be ultimately shifted to the left through automation. Automation can be leveraged each step of the way through this workflow, from the moment an event is detected all the way through post-mortem analysis — with the ultimate goal to reduce mean time to repair (MTTR) and make more effective use of operations teams during this response.