What Happens After BGP?
Gaining Full Path Visibility in Hybrid Cloud Networks In the modern enterprise, Border Gateway Protocol (BGP) plays a foundational role in connecting distributed networks. It is the routing protocol that...

As businesses become more reliant on the network to deliver services and products, network automation is becoming ever more critical. The network doesn’t take days off, and in my time as a network engineer, I learned this the hard way. Years ago, I was at a backyard barbecue when my old boss called, frantic: A critical file server was locked up as the likely result of a ransomware attack. I immediately raced to the console and segregated the site of the cyber attack from the rest of the global network to mitigate the risk.
After things settled down, the CIO called asking for an update: Did we lose any data? How did the ransomware get in? How did it spread? Do we have good backups?
The typical NOC workflow is manual and repetitive. With a level-0 network automation, a NetBrain diagnosis is automatically kicked off via API integration as soon as your monitoring or event management system registers an event.
I sat in our empty office and put my detective cap on in search of clues among the myriad scan data in front of me, which was no trivial task. I pored over dozens of graphs, jumped from screen to screen in multiple tools, logged into dozens of devices, and even had to call a few of my colleagues to get a complete picture of the network.
If only I had at my fingertips the information of what was happening to the network right at the time of the cyber attack. If only I had an automated script that kicked off the moment malicious activity was detected . . . then I’d still be savoring my cheeseburger and chips.
Situations like this happen all the time. Consider the typical tiered escalation workflow. When an event trouble ticket is submitted, a level-1 engineer kicks off a basic set of diagnostic workflows, most likely based on a standard playbook. Usually, this involves a lot of manual data collection via the CLI, followed by wading through raw text in “stare and compare” mode. If the level-1 engineer is unable to resolve this issue, the ticket is passed up the food chain to the level-2 engineer, who likely repeats the basic diagnosis to verify the data received and then dig a little deeper. And then it’s rinse and repeat when the problem escalates to a level-3 engineer.
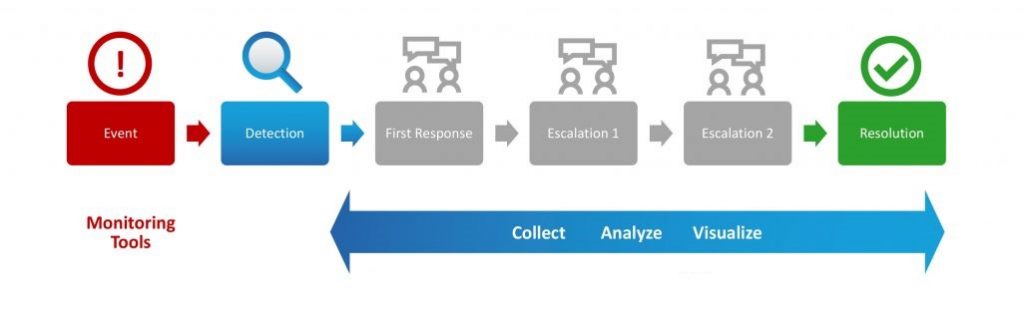
Automated monitoring wastes virtually no time detecting an event, but resolving it remains a highly inefficient manual process.
This typical NOC workflow is manual and repetitive. It involves a lot of duplicated effort to verify data. As the ticket is escalated, the diagnostic data supplied is either too little to draw any conclusions from or too much (i.e., a log dump). Surely, there has to be a more efficient way.
NetBrain redefines the NOC escalation workflow to begin with an event-triggered diagnosis. We call this a level-0 diagnosis. With a level-0 diagnosis, a NetBrain diagnosis is automatically kicked off via API integration as soon as your monitoring or event management system registers an event. Data is immediately collected at the time the event is detected, and the results of the diagnosis are written to the ticket for troubleshooters to review and leverage.
Network teams can set up level-0 diagnostics with any platform that is API-enabled, including event management systems, ticketing systems, IDS and other monitoring systems.
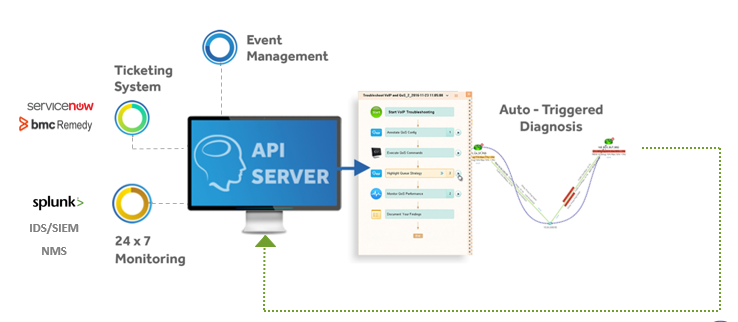
A 3rd-party system event triggers an API call to NetBrain to map and analyze the issue in real time, as it’s happening.
Let’s say you integrate NetBrain with your intrusion detection system. When the IDS reports an intrusion and fires off an alert, NetBrain automatically maps the cyber attack path along the network, gathers all relevant data and assesses the impact in real time. As a result, you have a range of data gathered while the intrusion was in progress – even if you can’t analyze the issue until later. This opens a whole new world for security teams: now they can analyze what actually happened during the security event, finding vulnerabilities and mitigating them faster than ever.
And the same event-triggered level-0 diagnosis can be kicked off by your monitoring tools (SolarWinds and others), ticketing system (ServiceNow, BMC Remedy), Splunk or anything with an API.
Uniting all your team’s API-enabled systems through NetBrain allows for almost infinite possibilities and vastly improved effectiveness; not just for NetBrain but for every single platform in the ecosystem.