What Happens After BGP?
Gaining Full Path Visibility in Hybrid Cloud Networks In the modern enterprise, Border Gateway Protocol (BGP) plays a foundational role in connecting distributed networks. It is the routing protocol that...

It was about 2 AM when we decided to break and head to the conference room where there was leftover pizza from earlier that day. I love good pizza, but even good pizza isn’t that great in the middle of the night when a network refresh isn’t going well.
All the access switches in the main office area were swapped the week before, and that part of this switch refresh project went without a hitch. Tonight, though, we were working on swapping devices in the main manufacturing facility, where we found surprise after surprise. What should have been a simple swap of straightforward access switches turned into a night of heartache and heroics.
Stopping for twenty minutes to grab a slice of pizza and guzzle some soda, I had a chance to talk to my co-workers and to our customer who gave us the network documentation in the first place. We weren’t outright angry with each other, but I sensed the beginnings of a subtle blame game.
The project wasn’t very different in scope from previous network refresh projects I’ve done, so it wasn’t the actual technology that was so frustrating. What was so difficult to stomach alongside what should have been a great midnight snack was realizing how poorly this project was planned due to a lack of quality network documentation and network discovery.
We weren’t struggling with the complexity of configuring a dozen overlays, and we weren’t struggling with figuring out a workaround to a software bug. Instead, we were struggling with poor planning and processes.
Grabbing a second slice I asked my customer if he could think of any other switches hiding in drop ceilings or undocumented wall-mounted racks. He couldn’t, so he suggested we take a walk to make sure. I didn’t like hearing that, considering what time it was, but I equally disliked hearing for the first time that they were using a VoIP over wireless phone system that required custom QoS policies to work effectively in their manufacturing facility.
We started on our quest, leaving a couple of engineers behind to relax and eat the last lukewarm pepperoni pie. My customer and I had a heart-to-heart about these issues, which really helped me to build a sense of urgency in him.
You see, the control center was generating enough traffic to saturate the 1 gig trunk link back to the data center, but the design didn’t call for a port channel or at the very least a single 10 gig trunk link. This should have been a matter of course in any network refresh cycle, but neither the customer nor our pre-sales folks performed a baseline traffic analysis.
Also, I explained that since we were writing a custom QoS policy on the fly tonight, there would be no way to truly validate its effectiveness until the next day when the network was under load. What we should have done is simulate the network as much as possible and push the configuration out programmatically. Unfortunately, we were going to have to touch every new switch one by one to add the relevant QoS configuration and service policy to every single trunk port.
I remember him nodding in agreement and offering to help roll back tonight’s changes so we could regroup the next day. The only problem with that, I explained, was that it was already after 2 AM and everything we had to do to roll back would be completely manual. I wasn’t sure if we had enough time.
We chose to push forward, but we settled on working right through the night and into the late morning. By about 4 AM my project manager was on site with huge quantities of coffee, and thankfully he did his best to stay out of our way. I was grateful for that, since by then not all of us had caught our second wind yet.
My team found several more rogue switches which they integrated into the new design since the customer hadn’t purchased enough to replace them. I hunted down documentation on the phone system so I could figure out the QoS policy, but my initial thought was not to bother and see how phone calls went. However, even in the middle of the night with no load on the network, our test calls were very poor.
We were working with an information deficit. The absence of decent network discovery and an understanding of how applications worked on the network prevented us from performing what should have been a straightforward network device refresh. We didn’t take into account several important considerations before undertaking this project.
Our first step should have been to gather information about the network through documentation and a network discovery. Simply counting the number of switches to replace is not enough.
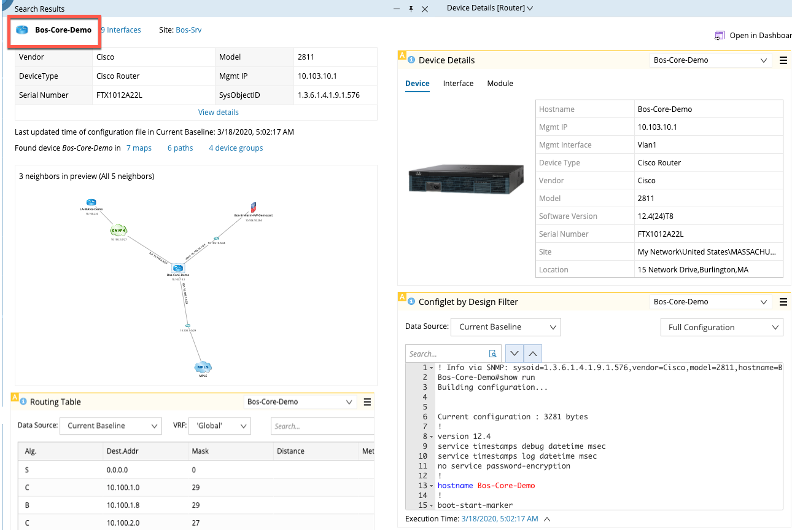
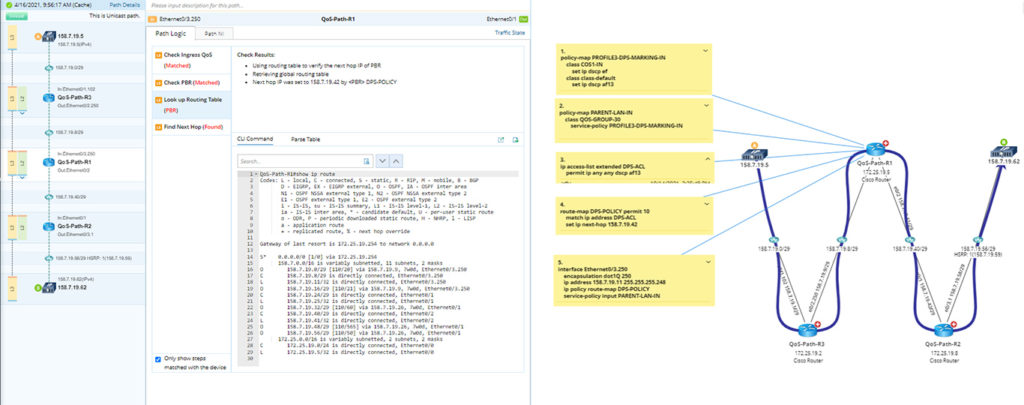
NetBrain addresses this with dynamic network maps that create accurate documentation in minutes. No team of engineers is needed to manually crawl the network for asset and topology discovery.
Keep in mind that this is much more than building an inventory spreadsheet. A successful network device refresh begins by identifying platforms and software versions so that the appropriate features can be planned for in the new design. NetBrain captures this data programmatically and on demand, which would have been extremely useful to a frustrated engineer like me at 2 AM.
Second, we needed a mechanism to evaluate features and syntax on the new gear. For example, upgrading switches from 1 gig trunks to 10 gig trunks may have ramifications to Spanning Tree or routing decisions, and this needs to be tested and evaluated before the change window timer begins.
In my case, I needed the ability to evaluate QoS configuration on the fly and quickly. Granted, it’s extremely difficult to test QoS configuration without the network being under load, but it’s just as important to test the actual implementation of the syntax because of how much it can differ from platform to platform.
And third, we had no way to programmatically touch a large number of devices. Being able to do this programmatically both in deploying configuration and in rolling back configuration can turn a network refresh from a all-hands-on-deck scenario to a manageable project that a single engineer could handle.
NetBrain can’t rack all your switches for you, but it does address the need for dynamic network discovery, on-demand documentation, and increased programmability.
That manufacturing organization network refresh project ended up being successful, but we worked for 30 hours straight with a team of five engineers to make it happen. Coffee helped, pizza helped, but having the right tools to get the information we needed beforehand and on-demand is what would have saved the day.