De top 5 netwerkondersteuningstickets om te automatiseren
Wat frustreert u het meest aan netwerkondersteuning? Niets voelt beter dan detective spelen over een obscuur netwerkprobleem en de IT-held zijn die het oplost. Maar te veel...

De rol van de netwerkingenieur evolueert, maar voordat je met je ogen rolt en zegt: "oh nee, niet weer een artikel over netwerkautomatisering", hoor me uit. Er zijn een aantal geweldige artikelen die onderzoeken hoe netwerkautomatisering deel uitmaakt van deze verandering, maar sinds ik een paar jaar geleden de VAR-wereld heb verlaten en intern in een paar grotere ondernemingen heb gewerkt, lijkt mijn dagelijkse werk zich meer te concentreren en meer over één ding: analyse.
Analytics is het verzamelen en interpreteren van gegevens, en netwerkanalyse is het verzamelen en analyseren van gegevens van onze netwerkinfrastructuur, met name met betrekking tot applicatieprestaties. Ik heb altijd relatief traditionele rollen als netwerkingenieur vervuld, dus ik houd me niet bezig met het analyseren van gegevens, simpelweg omdat ik van gegevens hou. In plaats daarvan wil ik die informatie gebruiken om patronen, correlaties en zoiets te vinden zinvol en uitvoerbaar om het netwerk op de een of andere manier te verbeteren.

De verschuiving voor mij in de afgelopen paar jaar heeft ertoe geleid dat ik me minder concentreerde op het configureren van een datacenter-core-cutover en meer op het uitzoeken wat er werkelijk dagelijks in het netwerk gebeurt. Dit had met name te maken met het oplossen van slechte applicatielevering, informatiebeveiliging en capaciteitsplanning. En dit alles vereiste analyse van netwerkgegevens.
Kort nadat ik een functie bij een grote onderneming had aangenomen, kreeg ik een e-mail van een wetenschapper die de high-performance computing-clusters van zijn team beheerde. Elke nacht op ongeveer hetzelfde tijdstip mislukte de gegevensoverdracht naar onze externe klanten, waarna het vele minuten duurde om te herstellen. Deze wetenschappers verzamelden gedurende de dag een enorme hoeveelheid atmosferische gegevens die ze vervolgens analyseerden voor klanten die de rapporten, de onbewerkte gegevens of beide kochten. Sommige van deze klanten waren zeer grote wetenschappelijke instellingen die deze extreem tijdgevoelige informatie over FTP haalden.
De applicatie die het cluster beheerde, stond op een bare metal-server die zich bovenaan het rack bevond en via een eigen verbinding met het cluster was verbonden, maar ook was verbonden met het LAN voor beheerdoeleinden en om de voltooide rapporten te leveren. De storing deed zich voor bij verschillende klanten, dus ik verwierp dat het probleem aan hun kant lag. Het moest van ons zijn. Er gebeurde iets op een van onze hosts, de clustercontroller of ergens in ons netwerkpad.
De hoofdwetenschapper nam het incident over en controleerde of de applicatie en de servers correct werkten. Alles leek in orde aan zijn kant, dus vermoedde hij een netwerkprobleem. We konden niet gemakkelijk een netwerkactiviteit lokaliseren die een conflict zou hebben veroorzaakt, dus begon ik met het bekijken van de configuratie van alle netwerkapparaten in het pad. Ik logde in op schakelaars, firewalls en routers, maar zag niets verkeerds.
Wat was hier aan de hand? De logboeken zouden het antwoord onthullen. Met behulp van de software die we destijds hadden, zag ik dat we heel weinig informatie verzamelden van heel weinig apparaten. Verder was er niet veel om naar te kijken. We hadden een soort van zinvolle informatie nodig. Natuurlijk had ik de hele nacht rond apparaten kunnen snuffelen om in realtime te zien wat er aan de hand was, maar ik wist dat ik niets gemakkelijk zou kunnen correleren. In plaats daarvan heb ik onze tool voor gegevensverzameling geconfigureerd om alles op het netwerk te verzamelen. Ik heb SNMP geconfigureerd op sommige apparaten, NETFLOW op andere, en voor degenen die geen van beide ondersteunden, heb ik de verzamelingstool geconfigureerd om die IP's voortdurend te pingen en hun open poorten te scannen.
Na een paar dagen bellen, googlen en praten met de hoofdwetenschapper, werd een klant erg ongeduldig en boos dat hun import bijna elke nacht mislukte. Dit werd een spraakmakende kwestie en een topprioriteit voor mij. Ik heb meer opslagruimte toegewezen aan de software voor gegevensverzameling en deze een week laten draaien. Toen ik me in de resultaten verdiepte, zag ik elke nacht rond dezelfde tijd een ongebruikelijke piek in de CPU van de applicatiecontroller – het tijdstip waarop het probleem begon. Dit was een goed begin, maar er was geen reden die de hoofdwetenschapper op de server zelf kon vinden die dit zou veroorzaken. De netwerkverbindingen zagen geen ongebruikelijke congestie en geen van onze schakelaars in het pad vertoonde ook maar iets ongewoons.
Omdat onze verzameltool middelmatig was, moest ik zelf heel wat uren besteden aan het doorspitten van al die nieuwe gegevens. Mijn collega hielp door een script te schrijven om te zoeken naar CPU-, link- en geheugengebruik en dat vervolgens in een grafisch formaat te presenteren via een soort slimme e-mailconnector. Na al die tijd en moeite verscheen er een rode vlag die ons wees naar een toegangsschakelaar die elke nacht een CPU-piek had. Ik logde in op de switch en zag dat de uptime een weerspiegeling was van een waarschijnlijke herstart op het noodlottige tijdstip van de vorige nacht.
Voordat ik het werk verliet, verving ik de switch, zorgde ik ervoor dat het IP-adres een van de widgets op ons monitoringdashboard was en zette ik een eenvoudige, permanente ping op. Mijn collega schreef een script om ons een e-mail te sturen als de pings wegvielen, en we hebben de bewakingssoftware ingesteld om een waarschuwing te sturen als de CPU piekt. Tot onze ontsteltenis kregen we de volgende ochtend e-mails met de melding dat pings wegvielen en meldingen van de verzamelsoftware dat de CPU piekte. We hebben de schakelaar gecontroleerd - hij stond aan. Ik controleerde de uptime - liet een herstart midden in de nacht zien. We waren er zeker van dat het antwoord in de data lag. Maar het was zo vervelend om er doorheen te mijnen en het duurde veel te lang voor onze klant. Er moet ergens een patroon of verband zijn geweest dat we niet hadden gevonden, dus we bleven zoeken. We hadden een betere manier nodig om dit te doen, maar voorlopig hebben we ons zo goed mogelijk door de software en aangepaste scripts heen geploeterd. Dan hebben we iets gevonden. Een onbekend apparaat op een onbekend IP-adres werd erg spraakzaam toen de switch opnieuw werd opgestart. Het was geen dubbel adres en het bevond zich niet op hetzelfde subnet, maar het gebeurde elke avond op dezelfde tijd.
Het opsporen van het apparaat was eenvoudig. Het zat niet in DNS, maar het was een reservering in DHCP. Het bleek de controller te zijn voor de back-up AC die elke nacht aan stond. Normaal gesproken zou dit geen probleem zijn, maar toen we naar de serverruimte gingen, ontdekten we dat de AC-unit op dezelfde PDU was aangesloten als de switch. Er was niets anders op de PDU en het was niet iets waar we eerder naar keken.
Toen de AC-unit aanging, was er genoeg van het circuit dat de schakelaar opnieuw opstartte. Dat was tenminste onze theorie. We hebben de schakelaar naar een andere PDU verplaatst en de HVAC-mensen gebeld. De schakelaar startte die nacht niet opnieuw op en voor zover ik begrijp, vonden de HVAC-mensen een probleem met een sensor en loste de elektricien het stroomprobleem op.
Om dit uit te zoeken, moesten veel gegevens worden verzameld en intelligent worden geanalyseerd. Dat is waar mijn netwerkingenieur-collega's en ik ons tegenwoordig in bedrijfs-IT bevinden. Natuurlijk is er af en toe een firewall-upgrade of vervanging van een MDF-switch, maar meestal verzamel en analyseer ik gegevens om problemen met de prestaties van applicaties op te lossen of aan een informatiebeveiligingstaak te werken.
Ik geloof niet dat de rol van een netwerkengineer zodanig verandert dat we programmeurs en datawetenschappers moeten worden, maar wat ik wel zie, is een groeiende trend om zeer bedreven te zijn in het verzamelen en analyseren van een enorme hoeveelheid dynamische en vluchtige informatie.
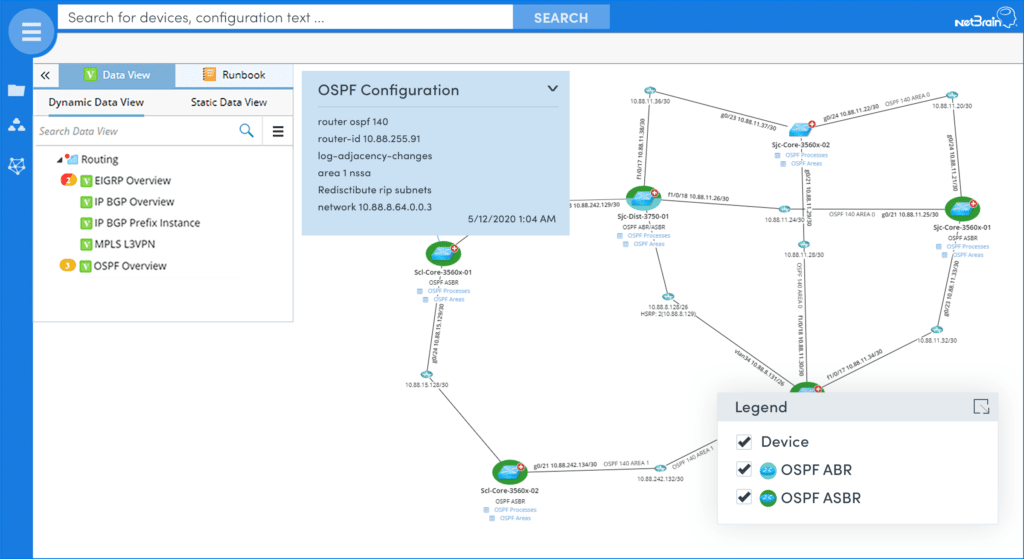
NetBrain heeft onlangs een veelbelovende technologie aangekondigd die tot doel heeft deze analyse-uitdaging aan te pakken - noemen ze het Uitvoerbaar Runbooks. Kortom, een Runbook biedt een manier om netwerkgegevens automatisch te verzamelen en te analyseren. Sinds deze RunbookZe kunnen worden aangepast (zowel door programmeurs als niet-programmeurs) en kunnen worden gebruikt om analyses uit te voeren voor elke netwerkfunctie. Het onderstaande voorbeeld is een Runbook dat is geschreven om het OSPF-routeringsontwerp te analyseren.