Les 5 meilleurs tickets de support réseau à automatiser
Qu'est-ce qui vous frustre le plus dans le support réseau ? Rien de mieux que de jouer au détective sur un problème de réseau obscur et d'être le héros informatique qui le résout. Mais trop...

Si vous êtes comme la plupart des ingénieurs réseau, en haut de votre liste des tâches les plus frustrantes, vous essayez de résoudre un problème réseau qui n'est plus en jeu. Nous sommes tous passés par là : vous ouvrez un ticket d'incident, mais quelles que soient les circonstances à l'origine du problème, elles ont maintenant changé et le problème semble s'être évanoui. Le mieux que nous puissions faire est de fermer le ticket en tant que NTF (aucun problème trouvé) ou CND (impossible de dupliquer) et d'espérer qu'il ne réapparaîtra pas. (Alerte spoiler : ce sera le cas, et probablement au pire moment possible.) Et avec le SDN "devenant réel", nous ne verrons que davantage de ces problèmes intermittents éphémères avancer.
Il est presque impossible de reproduire ces problèmes intermittents et il faut avoir de la chance pour les voir « en direct » en temps réel. Mais maintenant avec NetBrain vous pouvez déclencher un diagnostic automatisé d'un problème dès qu'il se produit - dépannage du réseau avec automatisation "juste à temps".
En fait, résoudre un problème intermittent est assez simple. Mais l'épingler ne l'est pas.
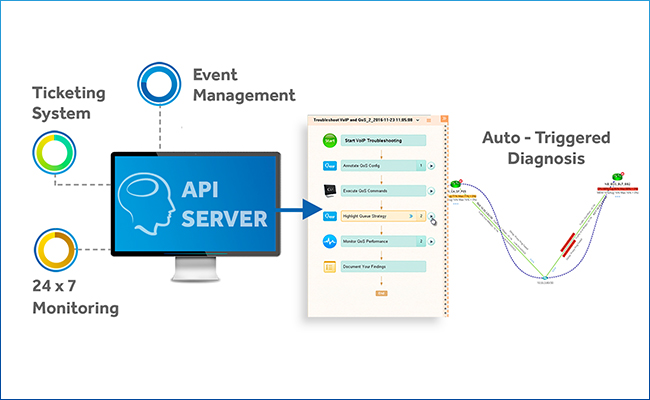
NetBrain Integrated Edition introduit l'intégration d'API avec d'autres systèmes de gestion de réseau - comme ServiceNow, vos solutions de surveillance IDS/SIEM, Splunk, 24×7 - de sorte que dès qu'une alerte est déclenchée, le chemin de la zone problématique est automatiquement cartographié, et Exécutable Runbooks entrent instantanément en action pour capturer toutes les données et analyses sur l'événement en temps réel. Nous appelons cela l'automatisation "juste à temps" car lorsqu'un événement se produit, toutes les données dont vous avez besoin sur le problème sont automatiquement collectées, analysées et visualisées en contexte sur un Dynamic Map. Aucune intervention humaine n'est nécessaire. Lorsque vous répondez à l'incident, tout n'attend que vous.
Au moment d'un événement, l'automatisation « juste à temps » effectue deux actions distinctes :
Dynamic Maps Définir automatiquement l'étendue du problème
Supposons que du jour au lendemain, votre outil de surveillance 24 × 7 a détecté qu'une application s'exécutait lentement et qu'un ticket ServiceNow a été créé. Le ticket ServiceNow s'est déclenché automatiquement NetBrain pour cartographier le chemin le long duquel le trafic de l'application circulait entre le serveur Web et le serveur de base de données - et chaque saut entre les deux - à ce moment précis. Ce n'est pas votre moyenne traceroute: NetBrain se connecte à la passerelle par défaut du serveur Web pour commencer à analyser le chemin, en commençant par les tables de routage, puis en analysant les paramètres avancés (VRF, ACL, PBR, NAT, etc.). Et vous verrez également le chemin de flux inverse - un aperçu crucial si le trafic de l'application est asymétrique. Cela vous donne une précision portée du problème en temps réel - pas à un moment ultérieur, après que le réseau a modifié dynamiquement le traffic path pour un certain nombre de raisons ou après que les dépanneurs précédents ont essayé de remapper l'application. Une URL de la carte est écrite directement dans le ticket ServiceNow. Un clic et vous êtes dans le Dynamic Map, qui peuvent être enrichies d'informations supplémentaires sur les performances de votre solution de surveillance (ou de tout autre système doté d'une API). Tout est là sur une seule vitre.
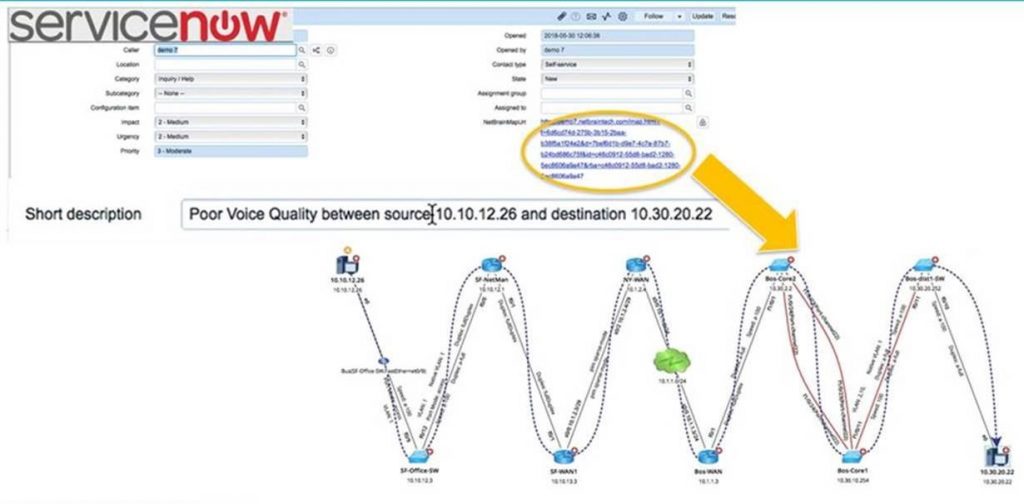
Le dépannage réseau « juste à temps » exécute les mêmes étapes que vous le feriez, mais automatiquement, sans que vous ayez à être là lorsque l'alerte est arrivée.
Runbooks Exécuter automatiquement les étapes pour diagnostiquer le problème
En même temps — encore une fois, automatiquement — un exécutable Runbook collecte des données de performances et émet des commandes CLI sur plusieurs appareils de plusieurs fournisseurs d'un seul coup pour obtenir les données pertinentes dont vous avez besoin pour déterminer exactement ce qui cause la lenteur. Vous voyez à quoi ressemblaient l'utilisation de la mémoire et du processeur lorsque l'alerte a été envoyée, ainsi que l'état de l'interface. Le Runbook recherchera automatiquement les collisions d'interface et les erreurs CRC sur traffic path, vérifiez la vitesse ou l'incompatibilité duplex, les ID OSPF en double, les numéros AS mal configurés pour les connexions voisines BGP, etc. Puisque notre première question est toujours, "Qu'est-ce qui a changé?" une Runbook effectue une analyse comparative de la topologie et du routage entre le moment où le problème a été détecté et un moment antérieur (lorsque l'application fonctionnait parfaitement). Il existe des centaines de diagnostics automatisés prêts à l'emploi et vous pouvez personnaliser un Runbook pour exécuter pratiquement n'importe quelle tâche de collecte ou d'analyse de données, sans avoir à écrire une seule ligne de code.
(Matt Speidel donne plus de détails dans Comment exécutable Runbooks Travail.)
La Runbook effectue les mêmes étapes de dépannage réseau que vous le feriez, mais automatiquement - sans que vous ayez à être là lorsque l'alerte est arrivée. Et tous les résultats de diagnostic sont documentés dans le Runbook qui est attaché à la carte. Cliquez simplement sur l'URL de la carte dans le ticket d'incident, et toutes les collectes et analyses de données que vous auriez faites de toute façon ont déjà été faites pour vous.
Un responsable réseau senior que je connais a dit un jour que les problèmes intermittents ne sont pas particulièrement intermittents ; c'est juste notre conscience d'eux qui l'est. Il y a de fortes chances que si un problème survient une fois, il réapparaîtra à nouveau - ou ailleurs dans le réseau. NetBrain a introduit une nouvelle capacité qui vous permet de tirer parti de sa puissance d'automatisation pour de manière continue et proactive surveiller tout problème que vous venez de résoudre. En d'autres termes, ces mystérieux problèmes intermittents deviennent des problèmes connus.
Regardez cette courte vidéo pour avoir un aperçu de la façon dont NetBrain s'intègre à d'autres systèmes (tels que ServiceNow, des outils de surveillance 24 × 7) pour fournir un diagnostic de dépannage réseau « juste à temps » d'un problème réseau dès qu'il se produit.
Nous pouvons également considérer ce dépannage de réseau automatisé déclenché par un événement comme un diagnostic « de niveau o » car toute la collecte, l'analyse et la visualisation des données ont été effectuées avant même qu'un ingénieur de niveau 1 ne commence à enquêter sur le problème. En fait, l'automatisation gère tout ce travail avant même qu'un humain n'entre en scène.
Vous ne pouvez pas réparer ce que vous ne pouvez pas voir. Dans les environnements réseau en constante évolution d'aujourd'hui, trop souvent, les problèmes ont disparu au moment où nous allons les résoudre. Habituellement, la résolution d'un problème intermittent est assez simple. Mais l'épingler ne l'est pas. C'est là qu'intervient l'automatisation « juste à temps ».