 by Kelly Yue Le 3 janvier 2022
by Kelly Yue Le 3 janvier 2022
L'un des outils les plus couramment utilisés en réseau dépannage est sans doute le traceroute (et son petit frère ping). Aussi utile que soit cet outil, il existe quelques défis critiques liés à l'utilisation de traceroute pour gérer les problèmes beaucoup plus complexes d'aujourd'hui. Rappelez-vous, ce traceroute a été créé à la fin des années 1980 lorsque les réseaux étaient beaucoup plus simples ; tout était physique, le point à point était à la mode, il y avait moins de protocoles à gérer et les commutateurs étaient communément appelés ponts, avec des routeurs LAN à WAN traversant d'un bâtiment à l'autre. (Rappelez-vous que c'était une demi-douzaine d'années avant même qu'Internet n'existe) ! Et qui se souvient des 'Leased T1 Lines' ? Le bon vieux temps pour ainsi dire.
Alors, comment des outils anciens comme celui-ci résistent-ils dans le monde d'aujourd'hui où tout est défini par logiciel et virtualisé ? Il doit sûrement y avoir un moyen plus moderne d'aider à dépanner les réseaux d'aujourd'hui ? Oui, il y en a alors continuez à lire…
Pour commencer, comprenons un peu plus ce qu'est une commande traceroute.
Qu'est-ce qu'une commande Traceroute ?
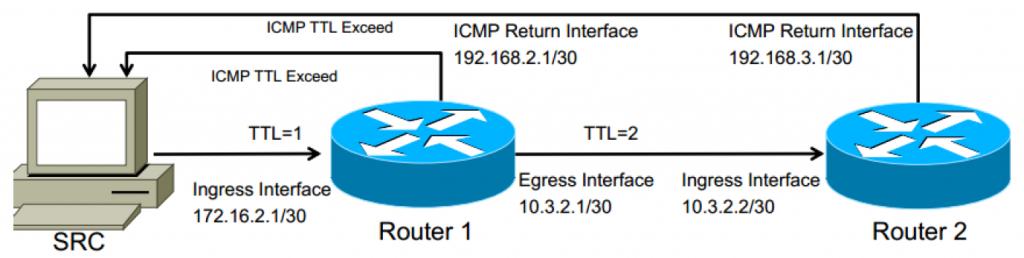
La machine source (SRC) enverra généralement 3 paquets de sonde vers l'adresse IP de destination, en commençant par la durée de vie (TTL) définie sur 1. On pense à tort que le type de paquet de sonde est toujours ICMP alors qu'en réalité, cela dépend de l'appareil à l'origine du traceroute. Les systèmes d'exploitation Windows utiliseront souvent ICMP, tandis que les appareils Unix et de routage utiliseront plus couramment les messages UDP vers des ports éphémères (ports supérieurs à 1024 qui ne sont pas des services bien connus comme DNS, SMTP, WEB, etc.)
Au fur et à mesure que le paquet de sonde est reçu sur chaque périphérique de couche 3, le TTL est décrémenté. Lorsque TTL atteint 0, l'appareil récepteur enverra un message ICMP "TTL expiré" à partir de l'interface qui a reçu ce paquet. C'est ainsi que traceroute connaît chaque saut en cours de route.
Dans l'image ci-dessous, 172.16.2.1 et 10.3.2.2 seraient les adresses renvoyées dans les résultats de traceroute.
Défis avec les commandes Traceroute pour les réseaux d'aujourd'hui :
#1 : Les chemins asymétriques ne peuvent pas être vus facilement. Seul A-to-B est signalé par défaut. B-to-A nécessite un autre traceroute à partir de l'autre extrémité pour compléter le chemin.
Le routage asymétrique est courant dans les réseaux aujourd'hui. Il existe de nombreux protocoles de routage multi-chemins à coût égal (ECMP) et même à coût inégal en jeu, et selon l'algorithme de hachage, le trafic empruntera probablement un chemin différent dans chaque direction. Ces différents chemins sont très difficiles à détecter avec une seule exécution de commande traceroute, et donc très difficiles à détecter exactement d'où vient le résultat du retard.
Comme vous pouvez le voir ci-dessus, la valeur de retard saute à ce saut particulier, mais la question est "Où est ce retard?" Est-ce sur le chemin aller ou sur le chemin retour ?
#2 : Les interfaces ne sont pas connues, seul le nœud IP de l'appareil. Il n'y a pas de détail supplémentaire.
Si nous regardons à nouveau le traceroute ci-dessus, les seules informations fournies sont un nom d'hôte/IP et un résultat différé. Si un utilisateur devait enquêter sur le saut 6, il aurait besoin de telnet/ssh au routeur et de déterminer à quelle interface cette adresse IP était attachée (montrer que la route IP 129.259.2.41 était ma façon préférée de le déterminer, mais vous pouvez montrer l'interface IP et dirigez la sortie vers un parser… afficher le résumé de l'interface IP | dans 129.150.2.41). Deuxièmement, pour déterminer l'interface de sortie (sortante), une deuxième recherche devrait être effectuée pour déterminer ces informations (afficher la route IP 192.41.37.40 par exemple)
#3 : Traceroute s'appuie sur la messagerie ICMP qui peut signaler un délai plus long que ce qui est réellement perçu par le trafic puisqu'ils sont traités sur le « chemin lent » d'un appareil par rapport au « chemin rapide » qui est utilisé pour transférer les données passant par le routeur .
Le chemin lent est plus facilement résumé comme lorsque le routeur doit traiter le contenu du paquet. Pratiquement tous les paquets destinés à un périphérique sont traités de cette manière. Les nouveaux routeurs ont des mécanismes internes pour hiérarchiser les paquets qu'ils traitent (routage des mises à jour de protocole avant les messages ICMP), mais cela ne fait qu'augmenter le problème ici. Comme nous l'avons vu précédemment, la plupart des systèmes utiliseront un message UDP, mais le fait de générer le message expiré ICMP TTL est une priorité inférieure, puis le chemin de retour sera un message ICMP, de sorte que les métriques de retard fournies dans les résultats sont difficiles accepter comme de vrais problèmes.
CONSEIL : Lorsque vous voyez un traceroute qui saute à une étape particulière du résultat et que tous les résultats suivants sont faibles, cela indique que le routeur "lent" est retardé dans le traitement. Si le chemin saute et que chaque étape suivante le long du chemin est incrémentée, cela signifie généralement une forme de file d'attente due à la congestion.
#4 : La sortie Traceroute est le texte statique sur lequel il est difficile d'agir.
Très bien, nous connaissons maintenant le chemin vers une destination spécifique, mais que se passe-t-il si je veux plonger plus profondément dans un ou plusieurs sauts le long de ce chemin ? La session de console Telnet/SSH exigera que l'utilisateur se connecte à ces appareils. Seule l'adresse IP de l'interface est fournie dans la réponse traceroute. Cela peut poser un défi dans de nombreux réseaux, car, du point de vue de la politique de sécurité, les utilisateurs doivent telnet/ssh à l'adresse IP de gestion. Telnet peut être bloqué sur les interfaces spécifiques signalées dans le traceroute, ce qui nécessite une certaine forme de recherche manuelle pour déterminer l'interface de gestion d'un périphérique avec cette adresse d'interface. Sans résolution DNS, cela peut être presque impossible. En cas de panne, chaque seconde compte pour vous.
#5 : Les chemins à coût égal ne sont pas représentés (seul le chemin réellement parcouru est signalé).
Comme mentionné précédemment, les itinéraires multi-chemins à coût égal ou inégal sont monnaie courante dans la plupart des réseaux aujourd'hui. Traceroute ne signalera que le chemin spécifique qui faisait partie des messages de sonde d'enquête. Étant donné que les implémentations de traceroute les plus courantes envoient 3 paquets de sonde avec différents ports de destination UDP, il est possible que dans un environnement ECMP, chaque saut ait jusqu'à 3 adresses IP différentes signalées. Garder une trace de quelle réponse fait partie de quel chemin peut devenir fastidieux.

#6 : Traceroute est Layer-3 (il ne signale pas les sauts de Layer 2)
Comme nous le comprenons maintenant, traceroute fonctionne en décrémentant la valeur TTL dans un paquet IP et en générant des messages ICMP expirés TTL. Le TTL n'est décrémenté que sur les appareils de couche 3, il n'y a donc pas de visibilité intégrée ou la possibilité de déterminer facilement le chemin de couche 2 tiré du résultat. Dans les environnements d'entreprise et de centre de données, il existe presque toujours une forme de commutateur d'accès de couche 2 utilisé pour agréger les stations terminales. Dans certaines conceptions, il existe également une couche de distribution de couche 2 avant d'atteindre un routeur central qui exécute en fait la première fonction de routage de couche 3 qui peut rendre compte à une demande de traceroute. Si la perte de paquets est présentée dans la sortie de traceroute, cela peut être dû à un hachage incorrect d'un canal de port de couche 2 ou d'un groupe d'agrégation de liens (LAG), à un problème d'arbre couvrant, à une configuration duplex sur un commutateur ou à un autre problème qui ne peut être découvert que par inspecter les éléments de la couche 2 le long du chemin. Pour trouver ces informations, il faudrait :
- Détermination de l'adresse MAC de l'équipement source sur le segment de couche 2, (vérification de la table ARP sur le routeur ou sur l'équipement source,
- Vérification de la documentation pour déterminer quels commutateurs sont utilisés
- Se connecter à chaque chemin possible et vérifier les tables MAC pour l'adresse MAC spécifique,
- Exécution de commandes pour vérifier les performances et la configuration
- Détermination des troncs qui s'éloignent de l'appareil actif
- Connectez-vous au périphérique de couche 2 suivant et répétez le processus jusqu'à atteindre le premier routeur.
Ce processus peut prendre beaucoup de temps, en particulier si CDP/LLDP n'est pas activé sur le réseau ou si la documentation est obsolète.
#7 : Il manque des informations historiques à Traceroute
Les résultats que vous voyez avec un traceroute sont l'état actuel. Il n'y a aucun moyen de déterminer quel était le chemin lorsque le trafic a réussi (hier par exemple). Considérez le traceroute ci-dessous, il serait bon de comprendre ce qu'était le saut 4 avant que les choses ne changent pour aider à isoler le problème possible.
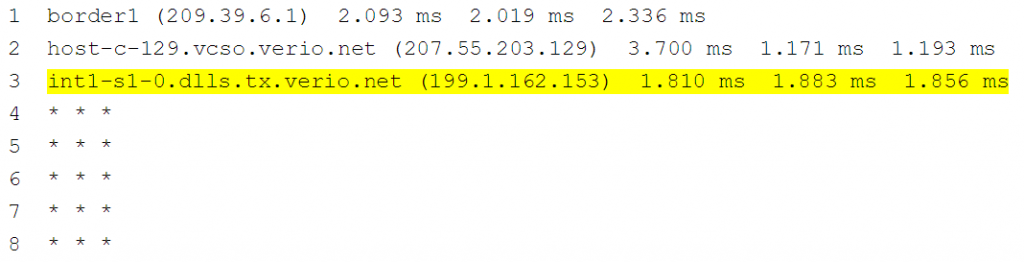
REMARQUE : Selon notre expérience, sur la base de la sortie de la commande traceroute ci-dessus, les ingénieurs supposeront que le saut 3 est le problème. Ce n'est souvent pas le cas. La première vérification qu'un utilisateur doit effectuer est de se connecter à l'appareil au saut 3 et de vérifier si l'appareil a une entrée de routage vers la destination. Si c'est le cas, souvent, le périphérique problématique est le saut suivant dans l'entrée de routage. Pour être complet, la vérification de l'interface de sortie vers le prochain saut de routage est utile pour vérifier les performances au niveau de l'interface et la configuration ACL.
#8 : Traceroute dispose d'un système de messagerie d'erreur cryptique.
Lorsque je rencontre un problème de commande traceroute, de temps en temps, j'obtiens un caractère dans la sortie qui me surprend. Le tableau ci-dessous provient de l'implémentation Cisco de traceroute. Bien qu'ils puissent sembler assez simples, comprendre exactement ce qui se passe nécessite presque toujours des recherches de suivi supplémentaires.
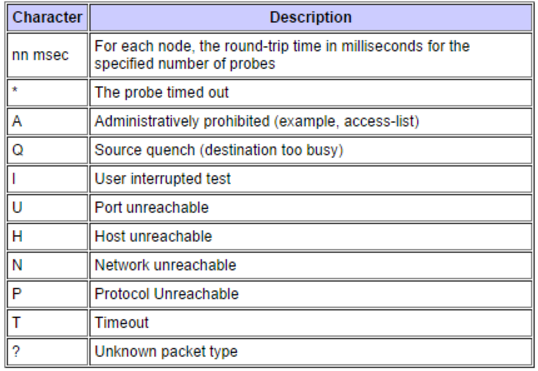
Disons, par exemple, que je reçois la lettre A dans la réponse de traceroute, je peux comprendre qu'il y a probablement une liste d'accès bloquant la traceroute, mais de quelle liste d'accès s'agit-il ? Pour le déterminer, je dois me connecter au routeur, déterminer l'interface dans laquelle le paquet est entré, vérifier la configuration et examiner la liste d'accès lorsque je la trouve. Cela peut être un long processus, et comme nous sommes toujours préoccupés par le temps qu'il faut pour résoudre les problèmes, il serait bon d'avoir un meilleur moyen d'accéder à ces informations.
REMARQUE : D'après notre expérience, ces messages d'erreur ne sont fournis qu'en fonction de l'interface d'entrée. Une fois qu'un paquet est reçu correctement, puis transmis au prochain saut le long du chemin s'il y a une ACL sur le port de sortie, vous obtenez simplement un * * * pour le prochain saut, ce qui signifie des étapes supplémentaires pour s'assurer que l'interface de sortie est connue, et toutes les ACL validées sur ce port également.
Quelle est la solution moderne ?
NetBrain comprend une multitude de fonctionnalités d'automatisation et de visualisation nécessaires à la maintenance des réseaux modernes. Il comprend le software-defined, la virtualisation et même le cloud. Il communique en permanence avec chaque appareil du réseau de bout en bout et crée un jumeau numérique en temps réel du réseau. Ce jumeau numérique est une réplique exacte des détails de chaque appareil. Il inclut la possibilité de visualiser les réseaux en temps réel et inclut un remplacement moderne de traceroute, appelé le Calculateur de chemin A/B. Cela répond à tous ces défis en aidant les ingénieurs de manière dynamique cartographier un réseau chemin entre deux points quelconques du réseau et fournissez des détails extrêmes sur ce chemin. Cette fonction prend en charge le mappage via les technologies modernes (par exemple, SDN, SD-WAN, pare-feu, équilibrage de charge), les sous-couches et les superpositions, tout en tenant compte des protocoles avancés (routage, listes d'accès, PBR, VRF, NAT, etc.). Et une fois déployée, la même structure qui peut être visualisée en temps réel crée désormais la plate-forme idéale pour automatisation sans code de chaque tâche, grande et petite !
Trois exemples concrets du calculateur de chemin A/B
# 1: Carte une application lente – Une application Web est lente entre Boston et Los Angeles.
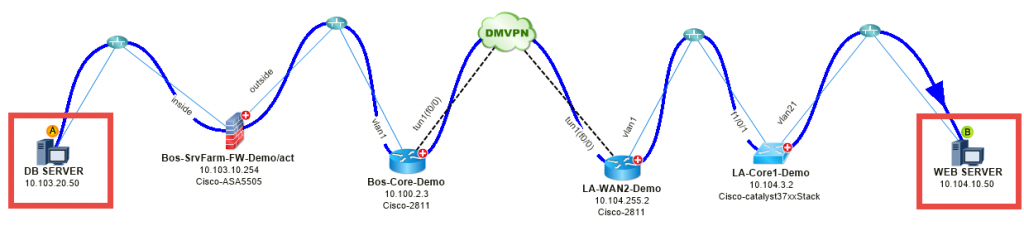
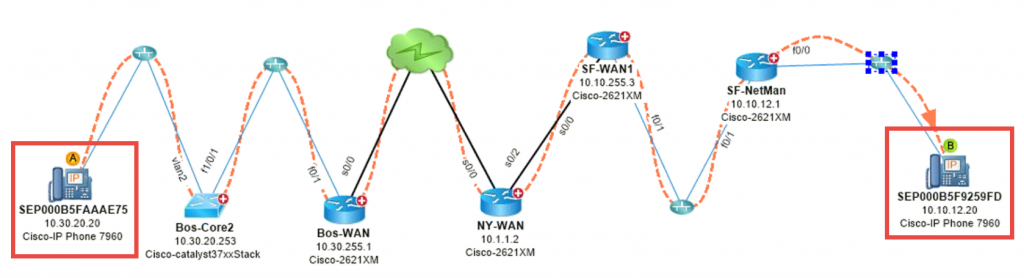
#2 : Mapper le flux de trafic VoIP – Le trafic vocal est agité entre Boston et San Francisco.
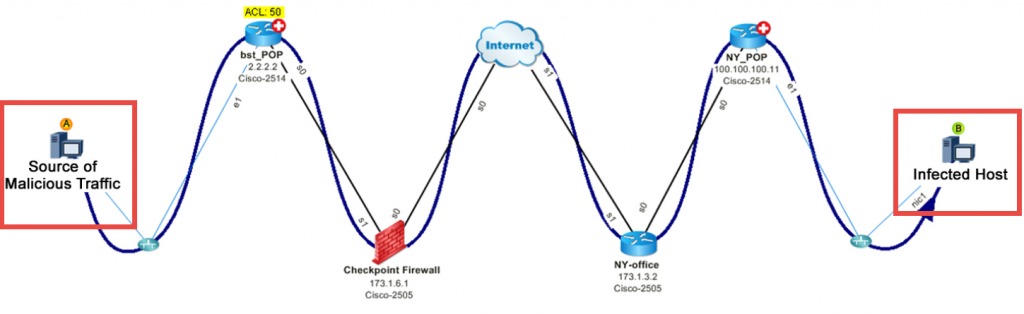
#3 : Map DDoS Attack – Un hôte malveillant injecte du trafic DoS sur le réseau. D'où vient le trafic et quel en est l'impact ? En tirant parti de NetFlow pour identifier le meilleur locuteur, vous pouvez tracer le chemin.
Assurance de prestation de service
NetBrain's Garantie des applications (AAM) cartographie tous les chemins d'accès au réseau de cloud hybride de vos applications dans une vue unique, valide en permanence les performances des chemins de bout en bout par rapport à des lignes de base de chemin saines et alerte de manière proactive les bonnes équipes afin qu'elles puissent agir sur les problèmes avant qu'ils ne perturbent votre activité. Il offre à vos équipes la possibilité de dépanner et de diagnostiquer rapidement les performances des applications au niveau du flux de trafic.
Il est maintenant possible d'empêcher la dégradation des performances des applications avec NetBrainAutomatisation basée sur l'intention sans code de 's.
NetBrain AAM protège l'expérience utilisateur en :
- Cartographier automatiquement tous les chemins d'application possibles et leurs appareils
- Définition des comportements pour tous les chemins d'application
- Baselinisation des chemins d'application en direct par rapport aux chemins "or" sur les cartes
- Visualisation des performances et de l'historique de chaque chemin d'application dans un seul tableau de bord
- Vous avertir des problèmes potentiels dès que les performances du chemin d'application se dégradent