Les 5 meilleurs tickets de support réseau à automatiser
Qu'est-ce qui vous frustre le plus dans le support réseau ? Rien de mieux que de jouer au détective sur un problème de réseau obscur et d'être le héros informatique qui le résout. Mais trop...

Les problèmes de réseau d'aujourd'hui nécessitent de plus en plus plus qu'un seul ingénieur — ou plus d'une équipe — pour les résoudre. Ces problèmes peuvent impliquer une partie du réseau (ou une technologie) avec laquelle vous n'êtes pas familier, il peut s'agir de problèmes vraiment délicats qui doivent être transmis à un ingénieur senior qui possède des « connaissances tribales » plus étendues, ou ils peuvent être des problèmes qui ne relèvent pas de votre domaine de responsabilité immédiat. Ce type de dépannage collaboratif n'est pas rare et les lacunes dans la collaboration inter-informatique sont importantes. NetBrainSondage sur l'état de l'ingénieur réseau a révélé que le manque de collaboration était le premier obstacle à un dépannage efficace.
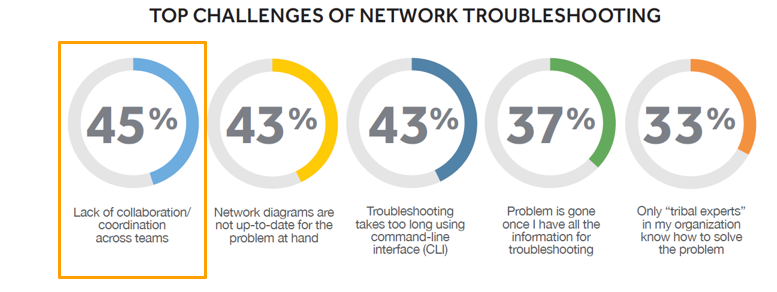
Alors, qu'est-ce qui empêche la collaboration au sein des équipes et entre elles ? C'est rarement parce qu'il y a une sorte d'obstination intentionnelle – une mentalité « nous contre eux ». Ce n'est pas comme si nous ne le faisions pas souhaitez collaborer avec d'autres ingénieurs ou d'autres groupes. Ce n'est pas que le personnel moins expérimenté se renvoie la balle ou que les cadres supérieurs adorent combattre les incendies. La collaboration est entravée car il est si difficile de :
Ces défis sont encore plus prononcés lorsqu'il s'agit d'atténuer les problèmes de sécurité du réseau, alors qu'une collaboration efficace peut souvent faire la différence entre une réponse opportune et bien conçue à une menace et une attaque détruisant votre réseau.
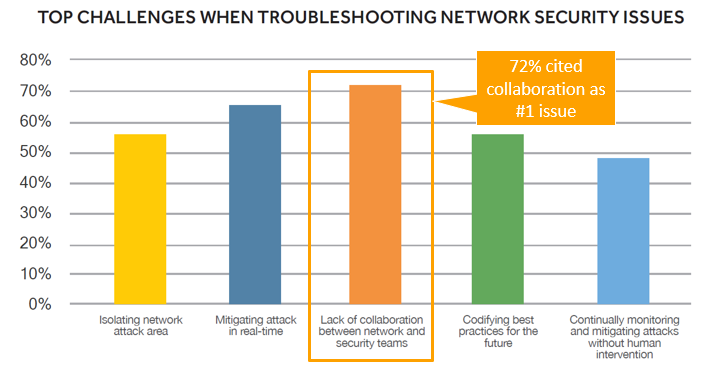
Les grands réseaux d'aujourd'hui subissent des changements constants (modifications de pannes/réparations, mises à niveau d'appareils et de logiciels, évolution architecturale) avec des changements exécutés par différentes personnes et différentes équipes. Les diagrammes de réseau traditionnels deviennent rapidement obsolètes et, trop souvent, les notes de conception critiques et autres documents sont incomplets (plus probablement inexistants). Les entreprises modernes ont une compréhension disparate et décentralisée de leur réseau, d'un campus à l'autre, d'une équipe fonctionnelle à l'autre. L'époque des ingénieurs individuels ayant une expertise dans tous les domaines d'un réseau d'entreprise est révolue.
Cela introduit une problème de visibilité: vous n'avez pas une image claire de ce à quoi ressemble réellement le réseau en direct. Trop souvent, vous êtes tout simplement incapable de visualiser les données informatiques critiques au moment où elles sont nécessaires, contextualisé pour votre tâche particulière à accomplir. Les diagrammes de réseau traditionnels ne sont que des cartes topologiques basées sur des icônes, où les images statiques représentent les périphériques mais manquent d'intelligence. NetBrain Dynamic Maps, d'autre part, sont pilotés par les données - chaque élément représente un "jumeau numérique" d'un périphérique réseau en direct, avec des centaines d'attributs de données, y compris son fichier de configuration, ses protocoles de routage, ses voisins, etc. La découverte approfondie (via non seulement SNMP mais aussi telnet/SSH) qui construit ce modèle mathématique signifie que la documentation dont vous avez besoin pour dépanner efficacement est maintenue et mise à jour automatiquement. Tu peux créer sur mesure une carte spécifique à la tâche à accomplir à la demande : des informations complètes et précises sont disponibles à portée de main lorsque vous en avez le plus besoin.
NetBrainLa découverte approfondie de signifie que vous pouvez créer sur demande une carte spécifique à la tâche à accomplir.
Conclusion : vous n'avez plus seulement un diagramme, mais une console d'investigation partagée avec des détails pratiquement infinis, accessible à tous, où que vous soyez. Toutes les informations réseau pertinentes sont disponibles pour être visualisées directement sur la carte, ce qui facilite le partage avec d'autres équipes. Activez ou désactivez simplement les données contextuelles dont vous avez besoin pour le problème que vous résolvez. Visualisez instantanément votre conception EIGRP ou OSPF en un coup d'œil, vérifiez l'état Actif/Veille des périphériques de basculement ASA - la liste est longue. Pratiquement toutes les données de n'importe quelle source peuvent être capturées dans un Dynamic Map — données de performance de votre outil de surveillance 24 × 7 (par exemple, SolarWinds), tickets ouverts de ServiceNow, données Splunk. S'il a une API, NetBrain peut ingérer les données et les relier au système source directement depuis la carte.
NetBrainLa capacité unique de rassembler (a) les données telnet/SSH de n'importe quel appareil dans un réseau multi-fournisseurs et (b) les informations pertinentes provenant d'autres sources via les API REST signifie que vous pouvez désormais visualiser également les constructions SDN telles que la structure Cisco ACI comme votre réseau traditionnel sur un Dynamic Map. Ceci est inestimable lors du dépannage d'une application lente qui circule à la fois sur la structure ACI et sur le réseau hérité, par exemple.
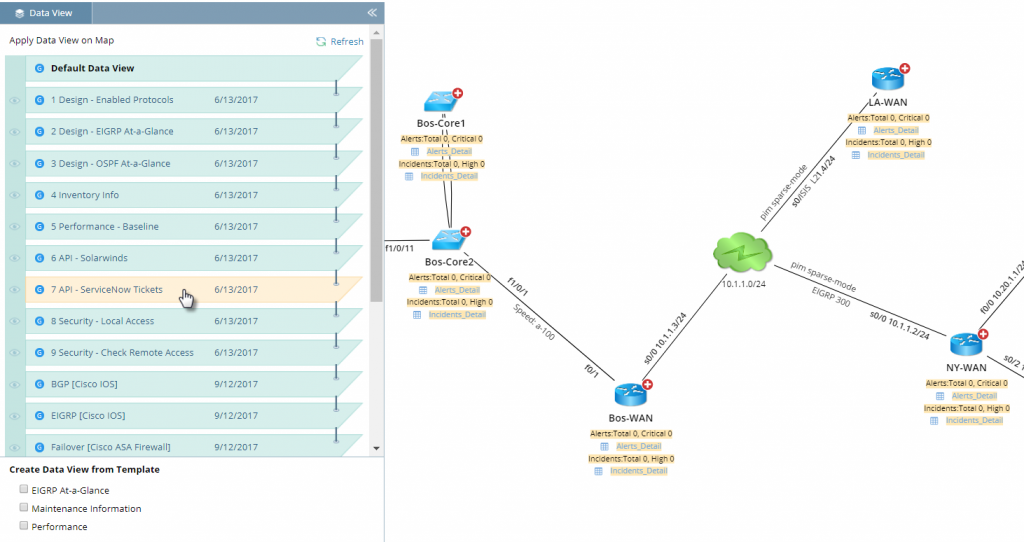 Activez ou désactivez pratiquement toutes les informations réseau, y compris les autres données NMS, directement sur la carte.
Activez ou désactivez pratiquement toutes les informations réseau, y compris les autres données NMS, directement sur la carte.
Plus besoin d'envoyer des fichiers journaux par e-mail et de parcourir des vidages de données textuels. Plus besoin de fouiller manuellement dans la CLI, un appareil à la fois, une commande à la fois, ou de sauter d'un écran à l'autre parmi divers outils pour assembler des informations.
Vous obtenez un aperçu complet de votre réseau sur une véritable fenêtre unique où tout le monde peut réellement utiliser les données - la carte.
Le flux de travail de dépannage manuel et répétitif typique implique de nombreux efforts en double pour vérifier les données. Au fur et à mesure que les cas s'intensifient entre différents niveaux d'ingénieurs, les données de diagnostic sont généralement trop ou trop peu. Lorsque nous sommes sous le feu, trop souvent, nous ne laissons que des notes superficielles aux ingénieurs de niveau supérieur. Des informations critiques se perdent en cours de route ou sont enfouies dans des vidages de journaux. Si vous êtes le suivant, vous devez relancer les mêmes diagnostics que le précédent, soit parce que c'est plus rapide que de parcourir un tas de données textuelles, soit parce que vous n'êtes tout simplement pas sûr qu'il demandait le bonnes questions. Vous finissez par réinventer la roue.
Mais avec Automatisation Runbooks, tous ces diagnostics de « première étape » que vous exécutez toujours peuvent être effectués automatiquement, les résultats étant capturés et enregistrés automatiquement. Les ingénieurs de niveau supérieur peuvent voir exactement quelles analyses ont déjà été effectuées (et quand et par qui), avec les résultats de diagnostic clairement présentés sur le Dynamic Map Dans le contexte. (En savoir plus sur Comment exécutable Runbooks Travail.)
Trop souvent, vous finissez par réinventer la roue - en réexécutant les mêmes diagnostics de dépannage simplement parce que vous pouvez tirer des enseignements du vidage de données de la personne précédente.
Dans l'exemple ci-dessous, le Runbook annoté la configuration QoS sur la partie du réseau mappée, exécuté automatiquement les commandes CLI sur tous les appareils d'un seul coup, mis en évidence la stratégie de file d'attente et vérifié les mesures de performance QoS. Tous les résultats de ces étapes sont disponibles sur la carte. En tant qu'ingénieur de niveau supérieur, vous venez d'éviter le manège des diagnostics répétés.
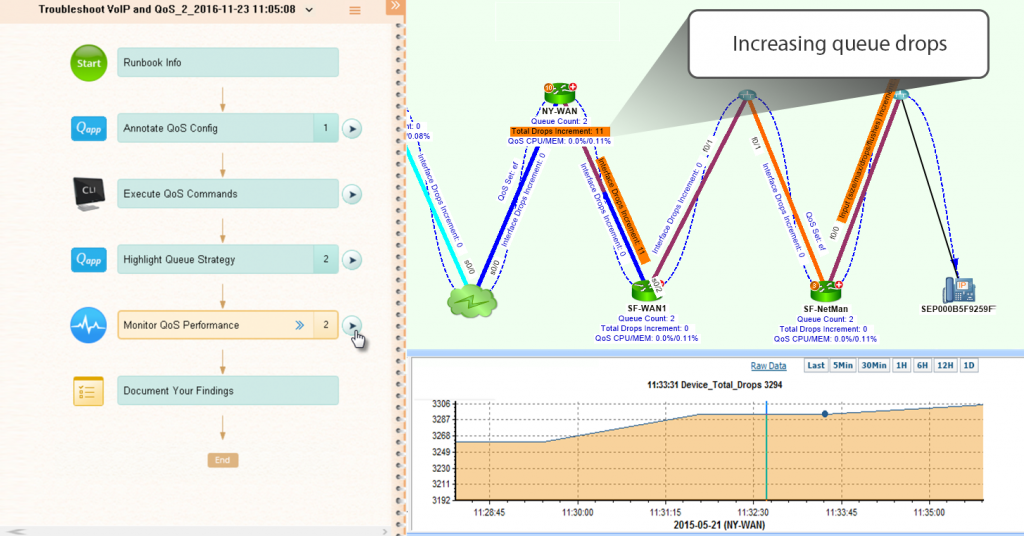 Lors du dépannage de QoS, Runbooks facilitent le partage des métriques de performance sur la carte (nombre de files d'attente actuelles, nombre total d'abandons, accessibilité et QoS utilisation CPU/mémoire).
Lors du dépannage de QoS, Runbooks facilitent le partage des métriques de performance sur la carte (nombre de files d'attente actuelles, nombre total d'abandons, accessibilité et QoS utilisation CPU/mémoire).
Runbooks facilitent également la communication efficace avec d'autres ingénieurs et d'autres équipes. Vous pouvez alerter une personne en particulier sur un appareil ou une carte en particulier lors de l'escalade des problèmes. Dans l'exemple ci-dessous, j'ai (en tant qu'ingénieur du premier intervenant) calculé le chemin AB entre un serveur Web et un serveur de base de données, exécuté un test ping et exécuté un Qapp Overall Health Monitor (l'un des NetBrainpersonnalisables de qui tirent parti de l'automatisation pour extraire des données des périphériques réseau et les analyser) qui surveille les 5 principales causes de lenteur du réseau (état de l'interface et performances des liens comme les retards, les erreurs et l'utilisation). Tout avait l'air d'aller bien, donc je dois envoyer le problème à un ingénieur de deuxième niveau, Jason. La fonction @Mention identifie la demande d'aide à Jason, et la fonction #Mention spécifie l'URL unique du Dynamic Map où il peut trouver tous les résultats de diagnostic. Maintenant, j'ai donné à Jason un bon départ pour découvrir ce qui ne va pas - il n'a pas à recommencer à zéro.
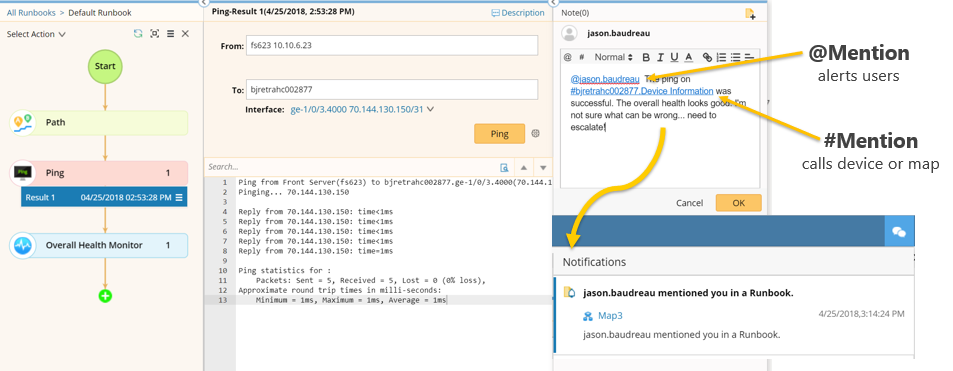 Runbooks facilitent le partage d'informations et l'escalade des problèmes lors de la collaboration sur un événement.
Runbooks facilitent le partage d'informations et l'escalade des problèmes lors de la collaboration sur un événement.
Une fois le problème résolu, toute analyse post-mortem est généralement limitée. Les données brutes que nous avons collectées lors du dépannage (sortie CLI) sont perdues, et j'ai peut-être appris ou non quelque chose qui m'aiderait la prochaine fois que ce type de problème se reproduirait (ce qui sera très probablement le cas). Si j'ai de la chance, Jason - le gars à qui j'ai dû faire remonter le problème - m'aurait montré ce qu'il avait fait. Mais Jason est comme la plupart des autres ingénieurs réseau expérimentés de nos jours : une fois ce problème particulier réglé, il y en a un million d'autres sur le pont. Il n'a tout simplement pas le temps d'expliquer comment il l'a fait, il l'a juste fait et est passé à autre chose.
C'est là que NetBrain Runbooks entrent. Il pourrait exécuter ses étapes de dépannage dans le Runbook (faisant les mêmes choses qu'il ferait manuellement, n'ayant NetBrain les exécuter automatiquement) afin qu'ils soient documentés à la volée. Aucun codage requis. La prochaine fois que ce genre de problème se présentera, je pourrai exécuter ceci Runbook et effectuez les mêmes étapes suivantes que Jason.
En gros, nous avons transféré son savoir-faire et lui avons permis de partager son expertise sans en perdre une miette.
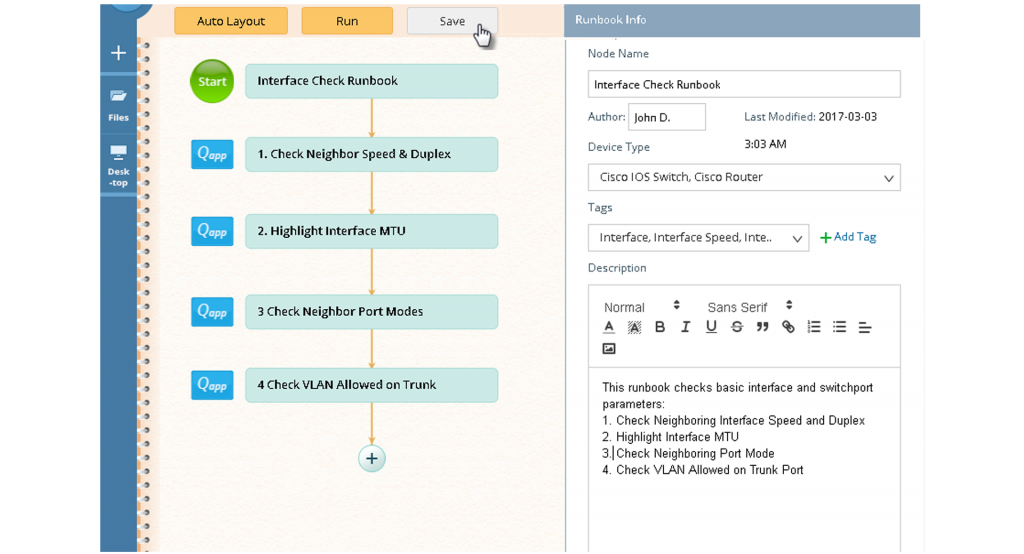 Chacun peut numériser son expertise particulière en Runbook flux de travail sans avoir besoin de connaissances particulières en programmation.
Chacun peut numériser son expertise particulière en Runbook flux de travail sans avoir besoin de connaissances particulières en programmation.
Les ingénieurs réseau n'ont plus à se soucier de savoir qui est sur le bon partage de fichiers, à faire circuler des classeurs imprimés ou à se fier à un cahier manuscrit à spirale dans une boîte ignifuge dans le NOC. Au lieu de cela, toutes les équipes de données dont les équipes ont besoin pour travailler ensemble sont contenues dans le NetBrain plate-forme.
Vouloir voir Dynamic Maps et Runbook L'automatisation en action ? Vous avez des questions ? Découvrez l'une de nos démonstrations quotidiennes de produits en direct avec des sessions de questions-réponses.