Les 5 meilleurs tickets de support réseau à automatiser
Qu'est-ce qui vous frustre le plus dans le support réseau ? Rien de mieux que de jouer au détective sur un problème de réseau obscur et d'être le héros informatique qui le résout. Mais trop...

Voici le The Perfect Storm!
Dans cette série, nous examinerons les Pas si évident scénarios où la "bonne" combinaison de "mauvaises" choses s'est produite, et le résultat produit une perte d'accessibilité, de connectivité, etc. Nous examinerons également comment l'échec a pu être évité ou minimisé en utilisant NetBrain.
Commençons!!
Dans ce scénario, nous constatons qu'une section du réseau ne peut pas communiquer avec une ressource basée sur le cloud pendant les tests d'acceptation.
Voici l'environnement réseau avec lequel nous travaillons :
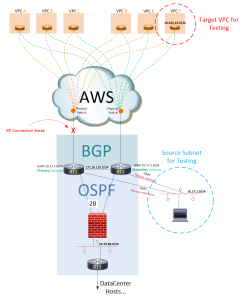
Figure 1 : Connectivité du centre de données au cloud AWS
RT1 et RT2 s'appairent chacun dans un environnement AWS via BGP, et chacun a un Physique chemin vers AWS. Ces deux routeurs ont une relation iBGP entre eux sur le réseau 172.16.110.0. De plus, RT1 et RT2 exécutent OSPF sur deux réseaux distincts : le réseau 172.16.110.0 et le réseau 10.70.28.0. Le trafic sur le réseau 10.70.28.0 (de RT1 et RT2) passe à travers un pare-feu pour accéder à un troisième voisin OSPF, RT3, qui gère le routage/trafic de couche 3 pour les sous-réseaux du centre de données.
Au cours des deux dernières soirées à 11h, une station de gestion de réseau sur le réseau 10.17.1.0 exécute des tests de performances vers un hôte AWS sur le réseau 10.192.16.0. Les tests prennent normalement 10 à 15 minutes. Lors de la troisième et dernière nuit de test, les tests sont retardés jusqu'à @2h du matin, au milieu de la fenêtre de maintenance du fournisseur de circuits AWS (où la maintenance est effectuée sur Chemin physique A). Bien qu'aucun problème lié à la connectivité n'ait été signalé à partir des hôtes du centre de données, les tests de performances exécutés à partir de la station de gestion du réseau ont échoué. Pourquoi a-t-il échoué ?
MÉTHODOLOGIE DE DÉPANNAGE
Examinons de plus près l'environnement, voyons ce qui a changé et déterminons comment ces changements ont influencé l'environnement. Alors, que s'est-il passé les première et deuxième nuits de test ? Nous allons jeter un coup d'oeil:
MAINTENANT, regardez spécifiquement ce qui s'est passé la troisième nuit !! Tout d'abord, nous pouvons commencer par identifier ce que nous savons : la connexion principale du FAI a été interrompue.
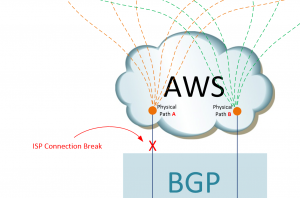
Figure 2 : Présentation du problème, c'est-à-dire la suppression de la connexion principale du FAI
Parlons ensuite de la façon dont la rupture du circuit a affecté les tables de routage… en particulier sur RT1. Avant la fenêtre de maintenance du FAI, RT1 avait une route eBGP dans sa table à partir de l'homologue eBGP du VPC F.
RT1#route maritime 10.192.16.0
Entrée de routage pour 10.192.16.0/24
Connu via "bgp 65535", distance 20, métrique 0
Balise 7224, type externe
Redistribution via ospf 1
Annoncé par ospf 1 sous-réseaux route-map DENY-SUMM
Dernière mise à jour de 192.168.8.6 il y a 00:04:10
Blocs de description de routage :
* 192.168.8.6, depuis 192.168.8.6, il y a 00:04:10
La métrique d'itinéraire est 0, le nombre de parts de trafic est 1
SA sauts 1
Étiquette de route 7224
Étiquette MPLS : aucune
RT1 #
Cependant, après la coupure du circuit, la table de routage de RT1 est très différente. La table RT1s a maintenant deux entrées pour le réseau 10.192.16.0, une vers RT2 sur son interface GigabitEthernet 0/3, et une autre vers RT2 sur son interface GigabitEthernet 0/1.
RT1#route maritime 10.192.16.0
Entrée de routage pour 10.192.16.0/24
Connu via "ospf 1", distance 110, métrique 400
Balise 7224, type externe 2, métrique directe 1
Redistribution via bgp 65535
Dernière mise à jour du 10.170.28.12 sur GigabitEthernet0/1, il y a 00:00:37
Blocs de description de routage :
* 172.16.110.12, à partir du 10.70.28.12, il y a 00:00:41, via GigabitEthernet0/3
La métrique d'itinéraire est 400, le nombre de parts de trafic est 1
Étiquette de route 7224
10.70.28.12, à partir du 10.70.28.12, il y a 00:00:37, via GigabitEthernet0/1
La métrique d'itinéraire est 400, le nombre de parts de trafic est 1
Étiquette de route 7224
VIRL-PHX-AWS-RT1#
Mais comment cela provoquerait-il un échec? Comment un supplément Info de contact. route entraîne l'échec de la connexion de la station de gestion au VPC F ? Pour comprendre cela, examinez comment le trafic circule entre le VPC F et le sous-réseau de gestion. Le trafic entrant circule du VPC F vers R2 (le seul chemin disponible), puis vers le sous-réseau de gestion.
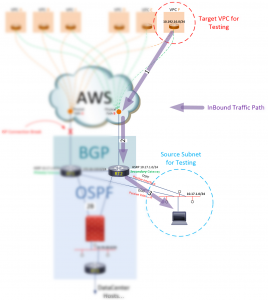
Figure 3 : Comprendre les flux de trafic entrant
Le trafic sortant prend un chemin différent. Ce chemin sortant est initialement dicté par le membre actif HSRP pour le sous-réseau 10.17.1.0. Il est toujours réglé sur RT1. Bien que le trafic sorte désormais via RT2, RT1 reste le routeur actif (passerelle par défaut) pour le sous-réseau 10.17.1.0. Dans cet esprit, suivez le flux sortant ci-dessous :
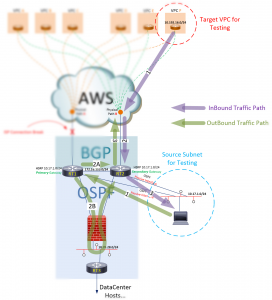
Figure 4 : Comprendre les flux de trafic sortant
Nous pouvons voir le premier chemin allant vers la passerelle par défaut (représentée par RT1), mais il y a deux sauts égaux représenté sur le second chemin ! Un vers RT2 via le réseau 172.16.110.0 et un vers RT2 via le réseau 10.70.28.0. Avec deux routes Layer3 égales vers RT2 disponible, RT1 équilibrera la charge, envoyant une partie du trafic sur le chemin du pare-feu (2B). Le pare-feu verra une conversation incomplète et appellera "Routage asymétrique" et l'interrompra.
ANALYSE DE LA CAUSE ORIGINELLE
Maintenant que nous comprenons mieux ce qui s'est passé, il est peut-être temps de vous demander : "Comment ai-je pu voir cela venir?" Quelles questions dois-je me poser pour mieux me préparer à de telles situations, et quels outils offriront une plus grande visibilité sur mon réseau Infrastructure Underlay/Overlay ? Comment puis-je devenir un meilleur "dépanneur de réseau» et pas seulement un « tireur » ?
Dans l'exemple ci-dessus, le problème a été identifié lorsque nous avons cartographié le traffic path. Ci-dessous j'ai utilisé NetBrain représenter graphiquement un traffic path en demandant aux routeurs comment aller de la source (dans ce cas, j'ai utilisé RT1…) à la destination :
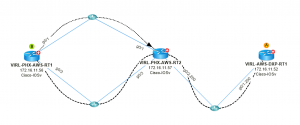
Figure 5 : Créer le traffic path en utilisant NetBrain
Au dessous de, NetBrain nous présente les données réelles de maintenance avant/après des tables de routage RT1, représentant les données réelles de "prise de décision" pour le traffic paths nous avons regardé ci-dessus.
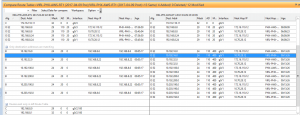
Figure 6 : La table de routage du routeur 1 utilisée pour déterminer le traffic paths
Et enfin, on voit (en utilisant NetBrain pour comparer les états de voisinage BGP avant et après maintenance de RT1) BGP un état homologue qui est à l'origine de tous les événements de ce scénario… Inactif (ou tout autre état non établi) par rapport aux états établis entre les voisins BGP RT1.
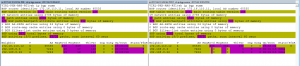
Figure 7 : Comparaison des configurations « avant » et « après »
En utilisant NetBrain avec VIRL sur paquet est une combinaison imbattable pour simuler et surveiller/enregistrer les performances et les caractéristiques du réseau en temps réel, en utilisant de véritables buildouts "Production Like", d'une manière qui peut être facilement documentée et transférée (configurations, surveillance, etc.) dans un environnement de production.
Pour en apprendre plus sur NetBrain, visitez https://www.netbraintech.com/plateforme/