Los 5 mejores tickets de soporte de red para automatizar
¿Qué es lo que más te frustra del soporte de red? Nada se siente mejor que jugar al detective en un problema de red oscuro y ser el héroe de TI que lo resuelve. Pero demasiado...

Con enormes televisores de pantalla plana montados en las paredes que muestran varios mapas y luces parpadeantes, un centro de operaciones de red puede parecerse al control de la misión de la NASA. Pero el objetivo principal de un centro de operaciones de red, o NOC, no es ejecutar una misión a la luna sino mantener y optimizar las operaciones de una infraestructura de red.
Si cree que es una declaración amplia que necesita elaboración, tiene razón. La idea de operaciones de red centralizadas puede ser ambigua y el propósito multifacético, así que dividámoslo en tres áreas: monitoreo, registroy la adopción de medidas.
Monitoreo
El monitoreo es una lucha para muchos CON. Algunos unen un mosaico de agregadores de registros y sistemas de alerta en una especie de solución de monitoreo unificado. Este tipo de proyectos comienzan con gran entusiasmo, pero rápidamente se deshacen en una colección de plataformas poco utilizadas que no se comunican entre sí y en las que ya nadie inicia sesión.
Pero ya sea que un equipo de operaciones de red utilice una red de derivación fuera de banda o la funcionalidad integrada de sus conmutadores y enrutadores, las alarmas y alertas son el elemento vital de los técnicos de NOC.
Imagine este escenario: se necesita una herramienta para obtener información de los conmutadores heredados, pero esa herramienta no funciona con los nuevos conmutadores del centro de datos. Se necesita otra herramienta para esos. Y se necesita otro para los cortafuegos porque no son compatibles con CDP o LLDP.
No es fácil monitorear una variedad de plataformas divergentes a la vez. Por lo general, los ingenieros están en deuda con el software preempaquetado que contiene los módulos que los desarrolladores pensaron que necesitaban sus clientes. Esto limita lo que puede hacer el NOC y cuán efectivo puede ser en el monitoreo de una infraestructura.
Sin embargo, la monitorización es lo que proporciona a los técnicos conciencia de la red, o en otras palabras, una idea clara de lo que está haciendo la red en un momento dado.
Inicio de sesión
Los registros recuerdan todo lo que sucede en la red y brindan pistas para la resolución de problemas y evidencia de incidentes de seguridad. Desafortunadamente, su uso efectivo puede ser extremadamente oneroso, lo que hace que el registro sea tanto una maldición como una bendición para un NOC típico.
Parte de hacer uso de la información de registro es crear los puntos de referencia del estado de la red a intervalos significativos. Esto es fundamental para determinar tendencias y mapear flujos de aplicaciones. Esta idea aparece en blogs, documentos técnicos y documentos de mejores prácticas; sin embargo, los puntos de referencia rara vez los realizan incluso los NOC más grandes debido a lo difícil que es hacerlo.
Una empresa de comercio electrónico podría crear y almacenar una cantidad increíble de información de registro, pero también podría crear instantáneas de referencia de la red durante los momentos de mayor actividad, como el Black Friday, los fines de semana y durante los eventos promocionales. Esta información brinda a los técnicos de red visibilidad de los flujos de aplicaciones cuando la red está bajo presión para rastrear el equilibrio de carga y exponer los cuellos de botella.
El problema es que la creación de puntos de referencia no es fácil y, como resultado, se descuida. Requiere capturar datos de red de una variedad de plataformas a la vez y con relación entre sí. Sin embargo, la captura de estos datos a lo largo del tiempo brinda a los técnicos de NOC un modelo a partir del cual trabajar y desarrollar su conocimiento de la red. Y tener esta información disponible al instante para todo el equipo fomenta una cultura de colaboración.
Tomando Acción
Los NOC monitorean las redes para detectar actividad anómala y tomar alguna acción al respecto. Supervisan el estado y la seguridad de la infraestructura y toman medidas para garantizar un rendimiento óptimo de la red, resolver incidentes y mantener una gestión transparente. change management .
Cuando entra una alerta, el NOC responde. Se crea un ticket para rastrear el incidente, un ingeniero se hace cargo de él y comienza el proceso de resolución de problemas.
Cuando la continuidad del negocio se ve afectada, un NOC requiere un sentido de urgencia, flujos de trabajo claros y operaciones optimizadas. No hay tiempo para iniciar sesión en dispositivos aleatorios y buscar el problema tomando fotos en la oscuridad.
La automatización y el intercambio de información son vitales para remediar el incidente lo más rápido posible.
Tiempo medio de reparación, o MTTR, es el tiempo promedio que se tarda en remediar un incidente. Un NOC optimizado utilizará la automatización para reducir MTTR para restablecer la continuidad del negocio lo antes posible.
Esto podría incluir la ejecución de un script para encontrar diferencias de configuración entre la ejecución de configuraciones y puntos de referencia. También podría incluir la capacidad de revertir los cambios mediante programación para restaurar los servicios rápidamente. Y si los dispositivos deben configurarse para solucionar el problema, el NOC debe tener la confianza de que no están empeorando las cosas. Esto significa que un NOC optimizado necesita un mecanismo de validación para probar los cambios antes de implementarlos.
Cómo NetBrain Resuelve estos problemas
Depender mucho de la automatización, NetBrain se integra fácilmente en el flujo de trabajo de un NOC para proporcionar los medios para ejecutar en cada una de las tres áreas principales.
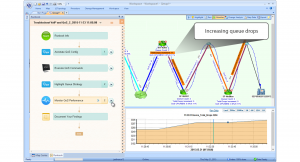 En primer lugar, NetBrain no limita a los ingenieros a unos pocos módulos específicos. Ejecutable RunbookLas s, por ejemplo, permiten a los técnicos crear una lógica personalizada que se puede implementar en grupos completos de dispositivos. De esta forma, los ingenieros pueden crear informes y alertas personalizados para satisfacer sus necesidades únicas y para sus plataformas particulares. La personalización fácil es necesaria para la visibilidad de extremo a extremo.
En primer lugar, NetBrain no limita a los ingenieros a unos pocos módulos específicos. Ejecutable RunbookLas s, por ejemplo, permiten a los técnicos crear una lógica personalizada que se puede implementar en grupos completos de dispositivos. De esta forma, los ingenieros pueden crear informes y alertas personalizados para satisfacer sus necesidades únicas y para sus plataformas particulares. La personalización fácil es necesaria para la visibilidad de extremo a extremo.
En segundo lugar, aunque la mayoría de los NOC empresariales aprecian el valor de una buena tala, NetBrain va un paso más allá para dar a los ingenieros la capacidad de crear puntos de referencia de su red, ya sea a intervalos planificados o incluso bajo demanda.
Ingenieros que buscan optimizar las operaciones NOC puede crear un punto de referencia antes y después de un cambio, a intervalos regulares, como cada semana, durante los momentos de mayor actividad o, posiblemente, al principio y al final de un turno. Esta es una manera increíble para que un NOC rastree los cambios en la red.
NetBrain brinda a todos los miembros del equipo que trabajan en un incidente un fácil acceso a la misma información en tiempo real. Dynamic Maps y ejecutable RunbookProporcionan al equipo la capacidad de memorizar información y también compartir datos al instante en un formato fácilmente consumible. 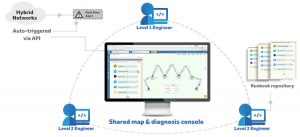 ayudar a construir la colaboración entre los ingenieros.
ayudar a construir la colaboración entre los ingenieros.
En tercer lugar, NetBrain es un activo en reduciendo el tiempo medio de reparación. Los ingenieros ya no se encuentran en medio de un apagón luchando para iniciar sesión en los dispositivos en busca de diferencias y buscar comandos; en cambio, el efecto acumulativo de Executable Runbooks, Dynamic Maps y Benchmarks a pedido significa que los equipos técnicos pueden encontrar y resolver problemas rápidamente, así como probar nuevas configuraciones de manera eficiente. Por ejemplo, NetBrain automatiza los comandos CLI y selecciona información significativa de la salida para mostrarla en un Dynamic Map — en última instancia, ahorra horas de resolución de problemas y reduce el tiempo total que le toma a un NOC encontrar una solución.
Además, disparar desde la cadera con Las herramientas de línea de comandos como traceroute están limitando y tedioso de usar. Traceroute, en particular, no puede proporcionar información sobre los saltos de la capa 2, lo que limita severamente la visibilidad, y tratar de mapear una red de esta manera puede llevar horas en lugar de segundos con NetBrain.
Los departamentos de TI de las empresas de hoy en día no ejecutan misiones a las estrellas, pero son fundamentales para mantener una red saludable. Esto significa monitoreo automatizado, registro y la capacidad de tomar medidas rápidas en caso de falla. Tal vez algún día las redes realmente se recuperen a sí mismas, pero hasta entonces, nuestros centros de operaciones de red son los héroes para mantener las luces encendidas.