Los 5 mejores tickets de soporte de red para automatizar
¿Qué es lo que más te frustra del soporte de red? Nada se siente mejor que jugar al detective en un problema de red oscuro y ser el héroe de TI que lo resuelve. Pero demasiado...

Una de las herramientas más utilizadas en red. la solución de problemas es posiblemente el traceroute (y su hermano pequeño ping). A pesar de lo útil que es esta herramienta, existen algunos desafíos críticos al usar traceroute para manejar los problemas mucho más complejos de la actualidad. Recuerde que traceroute se creó a fines de la década de 1980 cuando las redes eran mucho más simples; todo era físico, punto a punto estaba de moda, había menos protocolos con los que lidiar y los conmutadores se conocían comúnmente como puentes, con enrutadores de LAN a WAN que atravesaban de un edificio a otro. (¡Recuerde que esto fue media docena de años antes de que existiera Internet)! ¿Y quién se acuerda de 'Líneas T1 Arrendadas'? Los buenos viejos tiempos, por así decirlo.

Entonces, ¿cómo se mantienen las herramientas antiguas como esta en el mundo actual de todo virtualizado y definido por software? Seguramente debe haber una forma más moderna de ayudar a solucionar los problemas de las redes actuales. Sí, así que sigue leyendo…
Para comenzar, comprendamos un poco más sobre qué es un comando traceroute.
¿Qué es un Comando Traceroute?
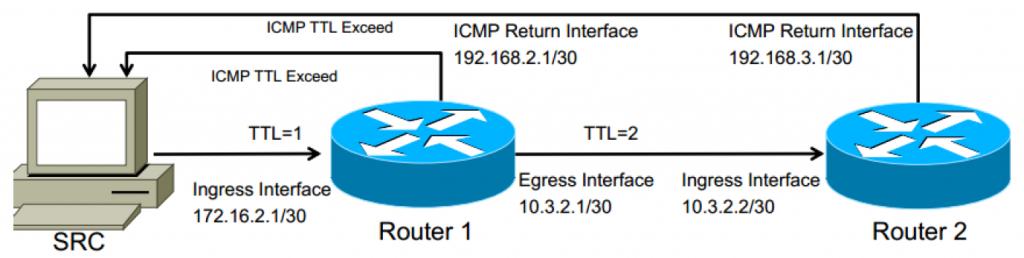
La máquina de origen (SRC) generalmente enviará 3 paquetes de prueba hacia la dirección IP de destino, comenzando con el tiempo de vida (TTL) establecido en 1. Se cree erróneamente que el tipo de paquete de prueba siempre es ICMP cuando en realidad depende del dispositivo. originando el traceroute. Los sistemas operativos Windows suelen utilizar ICMP, mientras que los dispositivos Unix y de enrutamiento suelen utilizar mensajes UDP para puertos efímeros (puertos superiores a 1024 que no son servicios conocidos como DNS, SMTP, WEB, etc.)
A medida que el paquete de prueba se recibe en cada dispositivo de capa 3, el TTL se reduce. Cuando TTL llega a 0, el dispositivo receptor enviará un mensaje ICMP "TTL Expired" desde la interfaz que recibió ese paquete. Así es como traceroute conoce cada salto en el camino.
En la imagen a continuación, 172.16.2.1 y 10.3.2.2 serían las direcciones devueltas en los resultados de traceroute.
Desafíos con los comandos Traceroute para las redes actuales:
#1: Los caminos asimétricos no se pueden ver fácilmente. Solo se informa de A a B de forma predeterminada. B-a-A requiere otro trazado de ruta desde el otro extremo para completar la ruta.
El enrutamiento asimétrico es común en las redes de hoy. Hay muchos protocolos de enrutamiento de rutas múltiples de igual costo (ECMP) e incluso de costos diferentes en juego, y dependiendo del algoritmo hash, es probable que el tráfico tome una ruta diferente en cada dirección. Estas rutas diferentes son muy difíciles de detectar con una sola ejecución del comando traceroute y, por lo tanto, muy difícil de detectar exactamente de dónde proviene el resultado del retraso.
Como puede ver arriba, el valor de la demora salta en este salto en particular, pero la pregunta es "¿Dónde está esta demora?" ¿Está en el camino de ida o en el camino de regreso?
#2: No se conocen las interfaces, solo el nodo IP del dispositivo. No hay ningún detalle adicional.
Si volvemos a mirar el traceroute anterior, la única información proporcionada es un nombre de host/IP y un resultado retrasado. Si un usuario investigara el salto 6, necesitaría hacer telnet/ssh al enrutador y determinar a qué interfaz se adjuntó esta dirección IP (mostrar la ruta IP 129.259.2.41 fue mi forma favorita de determinar esto, pero podría mostrar la interfaz IP y canalice la salida a un parser… mostrar el resumen de la interfaz IP | en 129.150.2.41). En segundo lugar, para determinar la interfaz de salida (saliente), sería necesario completar una segunda búsqueda para determinar esta información (mostrar la ruta IP 192.41.37.40, por ejemplo)
N.° 3: Traceroute se basa en la mensajería ICMP, que puede reportar un retraso mayor que el que realmente percibe el tráfico, ya que se procesan en la "ruta lenta" de un dispositivo frente a la "ruta rápida" que se usa para reenviar los datos que pasan a través del enrutador. .
La ruta lenta se resume más fácilmente como cuando el enrutador necesita procesar el contenido del paquete. Prácticamente cualquier paquete destinado a un dispositivo se maneja de esta manera. Los enrutadores más nuevos tienen mecanismos internos para priorizar qué paquetes procesan (actualizaciones del protocolo de enrutamiento antes que los mensajes ICMP), pero esto solo aumenta el problema aquí. Como discutimos anteriormente, la mayoría de los sistemas usarán un mensaje UDP, sin embargo, el acto de generar el mensaje ICMP TTL caducado tiene una prioridad más baja y luego la ruta de retorno será un mensaje ICMP, por lo que las métricas de demora proporcionadas en los resultados son difíciles. aceptar como problemas reales.
CONSEJO: Cuando ve un traceroute que salta en un paso particular en el resultado y todos los resultados siguientes son bajos, esto es una indicación de que el enrutador "lento" está retrasado en el procesamiento. Si la ruta salta y luego se incrementa cada paso siguiente a lo largo de la ruta, esto generalmente significa alguna forma de cola debido a la congestión.
#4: La salida de Traceroute es el texto estático sobre el que no se puede actuar fácilmente.
Muy bien, ahora conocemos el camino hacia un destino específico, pero ¿qué pasa si quiero profundizar en uno o más saltos a lo largo de ese camino? La sesión de la consola Telnet/SSH requerirá que el usuario inicie sesión en estos dispositivos. Solo se proporciona la dirección IP de la interfaz en la respuesta de traceroute. Esto puede representar un desafío en muchas redes, ya que, desde la perspectiva de la política de seguridad, los usuarios deben usar telnet/ssh para acceder a la dirección IP de administración. Telnet podría bloquearse en las interfaces específicas que se notifican en la ruta de seguimiento, lo que requiere algún tipo de búsqueda manual para determinar la interfaz de administración de un dispositivo con esa dirección de interfaz. Sin resolución de DNS, esto puede ser casi imposible. Cuando hay un apagón, cada segundo puede contarse en su contra.
#5: Las rutas de igual costo no están representadas (solo se informa la ruta real atravesada).
Como se mencionó anteriormente, las rutas de rutas múltiples de costo igual o desigual son comunes en la mayoría de las redes de hoy. Traceroute solo informará sobre la ruta específica que formaba parte de los mensajes de la sonda de consulta. Dado que las implementaciones de traceroute más comunes envían 3 paquetes de sondeo con diferentes puertos de destino UDP, es posible que en un entorno ECMP, cada salto tenga hasta 3 direcciones IP diferentes informadas. Hacer un seguimiento de qué respuesta es parte de qué ruta puede volverse engorroso.

#6: Traceroute es Layer-3 (no informa sobre los saltos de Layer 2)
Como ahora entendemos, traceroute funciona para disminuir el valor TTL en un paquete IP y generar mensajes ICMP TTL caducados. El TTL solo se reduce en los dispositivos de la capa 3, por lo que no hay visibilidad integrada ni la capacidad de determinar fácilmente la ruta de la capa 2 tomada del resultado. En entornos empresariales y de centros de datos, casi siempre se utiliza algún tipo de conmutador de acceso de capa 2 para agregar estaciones finales. En algunos diseños, también hay una capa de distribución de capa 2 antes de llegar a un enrutador central que en realidad realiza la primera función de enrutamiento de capa 3 que puede informar a una solicitud de rastreo de ruta. Si la pérdida de paquetes se presenta en la salida de traceroute, podría deberse a un hashing incorrecto de un canal de puerto de capa 2 o un grupo de agregación de enlaces (LAG), un problema de árbol de expansión, una configuración dúplex en un conmutador u otro problema que solo puede ser descubierto por inspeccionando los elementos de la capa 2 a lo largo de la ruta. Encontrar esta información requeriría:
Este proceso puede llevar mucho tiempo, especialmente si CDP/LLDP no está habilitado en la red o si la documentación está desactualizada.
#7: a Traceroute le falta información histórica
Los resultados que ve con un traceroute son el estado actual. No hay forma de determinar cuál era la ruta cuando el tráfico fue exitoso (ayer, por ejemplo). Considere la ruta de seguimiento a continuación, sería bueno comprender qué era el salto 4 antes de que las cosas cambiaran para ayudar a aislar el posible problema.
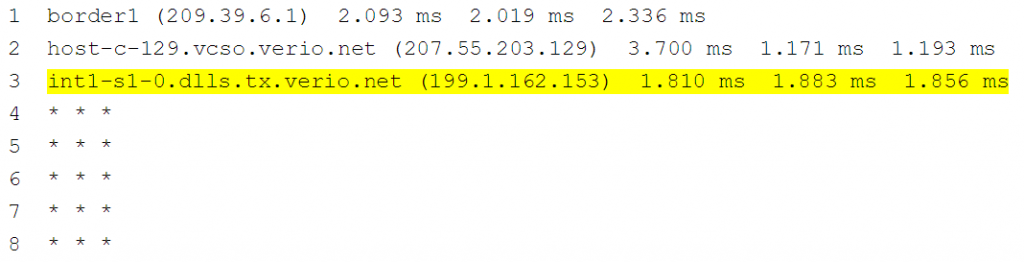
NOTA: Según nuestra experiencia, según el resultado del comando traceroute anterior, los ingenieros supondrán que el problema es el salto 3. Con frecuencia este no es el caso. La primera verificación que debe realizar un usuario es iniciar sesión en el dispositivo en el salto 3 y verificar si el dispositivo tiene una entrada de enrutamiento al destino. Si es así, a menudo, el dispositivo problemático es el siguiente salto en la entrada de enrutamiento. Para ser exhaustivo, es útil verificar la interfaz de salida hacia el siguiente salto de enrutamiento para verificar el rendimiento del nivel de interfaz y la configuración de ACL.
#8: Traceroute tiene un sistema de mensajes de error críptico.
Cuando me encuentro con un problema con el comando traceroute, de vez en cuando aparece un carácter en el resultado que me sorprende. La siguiente tabla es de la implementación de traceroute de Cisco. Si bien pueden parecer lo suficientemente sencillos, comprender exactamente lo que está sucediendo casi siempre requiere una excavación de seguimiento adicional.
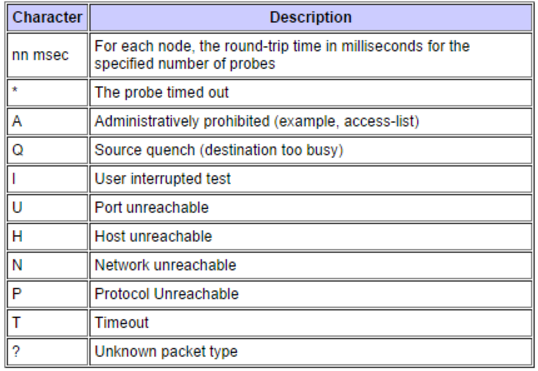
Digamos, por ejemplo, que recibo la letra A en la respuesta de traceroute, puedo entender que probablemente haya una lista de acceso que bloquee el traceroute, pero ¿qué lista de acceso es? Para determinar esto, tendré que iniciar sesión en el enrutador, determinar a qué interfaz ingresó el paquete, verificar la configuración e investigar la lista de acceso cuando la encuentre. Este puede ser un proceso largo, y dado que siempre nos preocupamos por el tiempo cuando se trata de solucionar problemas, sería genial tener una mejor manera de obtener acceso a esta información.
NOTA: Según nuestra experiencia, estos mensajes de error solo se proporcionan en función de la interfaz de ingreso. Una vez que un paquete se recibe correctamente y luego se reenvía al siguiente salto a lo largo de la ruta si hay una ACL en el puerto de salida, simplemente obtiene un * * * para el siguiente salto, lo que significa pasos adicionales para garantizar que se conozca la interfaz de salida. y cualquier ACL validada en ese puerto también.
¿Cuál es la solución moderna?
NetBrain incluye una gran cantidad de funciones de automatización y visualización necesarias para mantener las redes modernas. Entiende definido por software, virtualizado e incluso la nube. Se comunica continuamente con todos los dispositivos de la red de extremo a extremo y crea un gemelo digital de la red en tiempo real. Este gemelo digital es una réplica exacta de los detalles de cada dispositivo. Incluye la capacidad de visualizar redes en tiempo real e incluye un reemplazo moderno para traceroute, conocido como el Calculadora de rutas A/B. Esto aborda todos estos desafíos al ayudar a los ingenieros de forma dinámica. mapear una red camino entre dos puntos cualquiera en la red y proporcione detalles extremos de ese camino. Esta función admite el mapeo a través de tecnologías modernas (p. ej., SDN, SD-WAN, cortafuegos, balanceo de carga), capas subyacentes y superposiciones, al mismo tiempo que considera protocolos avanzados (enrutamiento, listas de acceso, PBR, VRF, NAT, etc.). Y una vez implementada, la misma estructura que se puede visualizar en tiempo real ahora crea la plataforma perfecta para automatización sin código de cada tarea, grande y pequeña!
Tres ejemplos del mundo real de la calculadora de rutas A/B
# 1: Mapa una aplicación lenta: una aplicación web es lenta entre Boston y Los Ángeles.
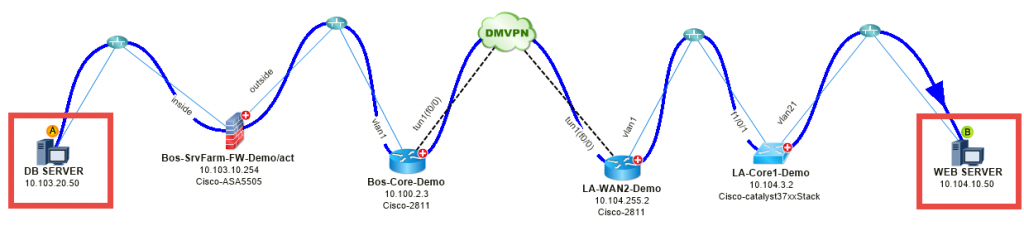
N.º 2: Mapear el flujo de tráfico de VoIP: el tráfico de voz es inestable entre Boston y San Francisco.
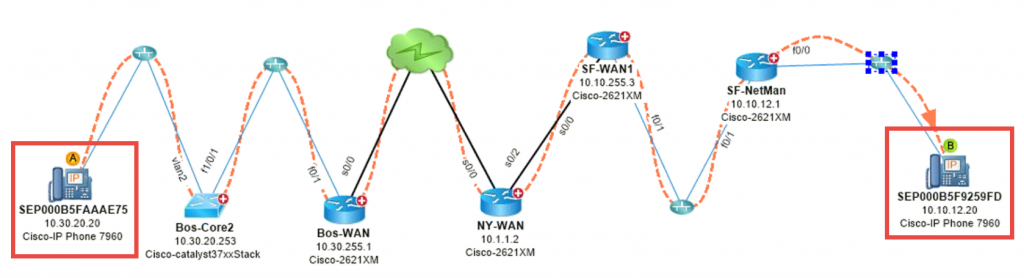
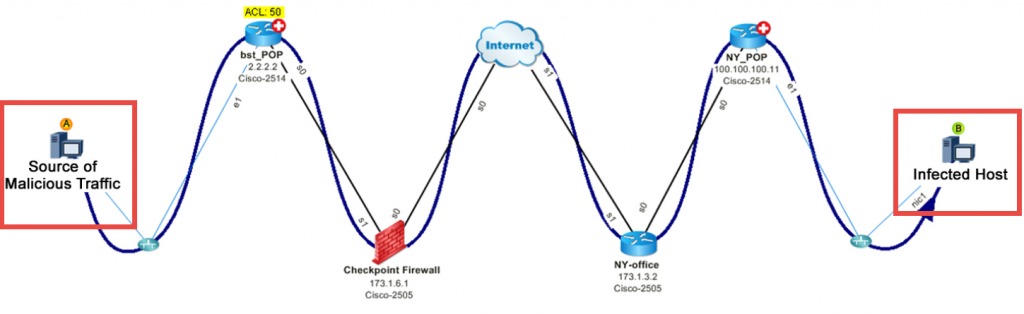
#3: Ataque DDoS de mapa: un host malicioso está inyectando tráfico DoS en la red. ¿De dónde viene el tráfico y cuál es el impacto? Al aprovechar NetFlow para identificar al que más habla, puede trazar la ruta.
Garantía de prestación de servicios
NetBrain, Garantía de aplicación (AAM) mapea todas las rutas de la red de nube híbrida de su aplicación en una sola vista, valida continuamente el rendimiento de la ruta de extremo a extremo frente a líneas de base de ruta saludables y alerta proactivamente a los equipos correctos para que puedan actuar sobre los problemas antes de que interrumpan su negocio. Brinda a sus equipos la capacidad de solucionar problemas y diagnosticar rápidamente el rendimiento de la aplicación a nivel de flujo de tráfico.
Ahora es posible evitar la degradación del rendimiento de la aplicación con NetBraines sin código Intent-based automation.
NetBrain AAM protege la experiencia del usuario al: