 by 11. Juli 2018
by 11. Juli 2018
Wenn Sie wie die meisten Netzwerktechniker sind, steht ganz oben auf Ihrer Liste der frustrierendsten Aufgaben der Versuch, ein Netzwerkproblem zu beheben, das nicht mehr im Spiel ist. Wir kennen das alle: Sie öffnen ein Trouble Ticket, aber die Umstände, die das Problem ursprünglich verursacht haben, haben sich jetzt geändert, und das Problem scheint sich in Luft aufgelöst zu haben. Das Beste, was wir tun können, ist, das Ticket als NTF (kein Problem gefunden) oder CND (kann nicht dupliziert werden) zu schließen und zu hoffen, dass es nicht wieder auftaucht. (Spoiler-Alarm: Das wird es, und wahrscheinlich zum ungünstigsten Zeitpunkt.) Und da SDN „wirklich wird“, werden wir nur noch mehr dieser kurzlebigen, zeitweise auftretenden Probleme sehen.
Es ist fast unmöglich, diese intermittierenden Probleme zu reproduzieren, und Sie müssen Glück haben, sie in Echtzeit „live“ zu sehen. Aber jetzt mit NetBrain Sie können eine automatische Diagnose eines Problems in dem Moment auslösen, in dem es auftritt – Netzwerk-Fehlerbehebung mit „Just-in-Time“-Automatisierung.
Tatsächlich ist die Behebung eines zeitweiligen Problems ziemlich einfach. Aber es festzunageln ist es nicht.
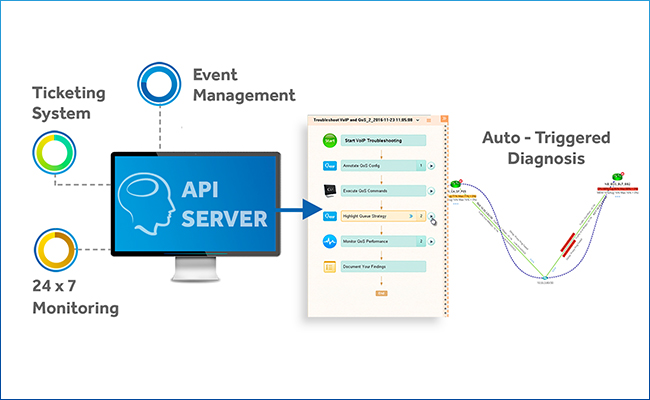
NetBrain Integrated Edition führt die API-Integration mit anderen Netzwerkverwaltungssystemen ein – wie ServiceNow, Ihr IDS/SIEM, Splunk, 24×7-Überwachungslösungen – so dass, sobald eine Warnung ausgelöst wird, der Pfad des Problembereichs automatisch abgebildet wird, und Ausführbar Runbooks sofort aktiv werden, um alle Daten und Analysen zum Ereignis in Echtzeit zu erfassen. Wir nennen das „just in time“-Automatisierung, weil während ein Ereignis stattfindet, Alle Daten, die Sie zum Problem benötigen, werden automatisch gesammelt, analysiert und im Kontext auf einem visualisiert Dynamic Map. Es ist keine menschliche Beteiligung erforderlich. Wenn Sie auf den Vorfall reagieren, wartet alles nur auf Sie.
Das ABC der „Just in Time“-Automatisierung
Im Moment eines Ereignisses führt die „Just-in-Time“-Automatisierung zwei unterschiedliche Aktionen aus:
- Eine Karte des Problembereichs wird dynamisch erstellt.
- Ein vordefinierter Satz von Prozeduren wird automatisch ausgeführt, um eine „Level-0“-Diagnose durchzuführen.
Dynamic Maps Den Umfang des Problems automatisch definieren
Nehmen wir an, Ihr 24×7-Überwachungstool hat über Nacht festgestellt, dass eine Anwendung langsam läuft, und es wurde ein ServiceNow-Ticket erstellt. Das ServiceNow-Ticket wird automatisch ausgelöst NetBrain um den Pfad abzubilden, auf dem der App-Datenverkehr zwischen dem Webserver und dem Datenbankserver floss – und jeden Hop dazwischen – in genau diesem Moment. Das ist nicht dein Durchschnitt Traceroute: NetBrain meldet sich beim Standard-Gateway des Webservers an, um mit der Analyse des Pfads zu beginnen, beginnend mit den Routing-Tabellen und dann mit der Analyse erweiterter Parameter (VRFs, ACLs, PBR, NAT und mehr). Und Sie sehen auch den Reverse-Flow-Pfad – ein entscheidender Einblick, wenn der Anwendungsdatenverkehr asymmetrisch ist. Dies gibt Ihnen eine genaue Umfang des Problems in Echtzeit — nicht zu einem späteren Zeitpunkt, nachdem das Netzwerk dynamisch das geändert hat traffic path aus einer Reihe von Gründen oder nachdem frühere Fehlerbehebungen versucht haben, die Anwendung neu zuzuordnen. Eine URL der Karte wird direkt in das ServiceNow-Ticket geschrieben. Ein Klick und Sie sind in der Dynamic Map, die mit zusätzlichen Leistungsinformationen aus Ihrer Überwachungslösung (oder jedem anderen System mit einer API) angereichert werden kann. Alles befindet sich direkt auf einer einzigen Glasscheibe.
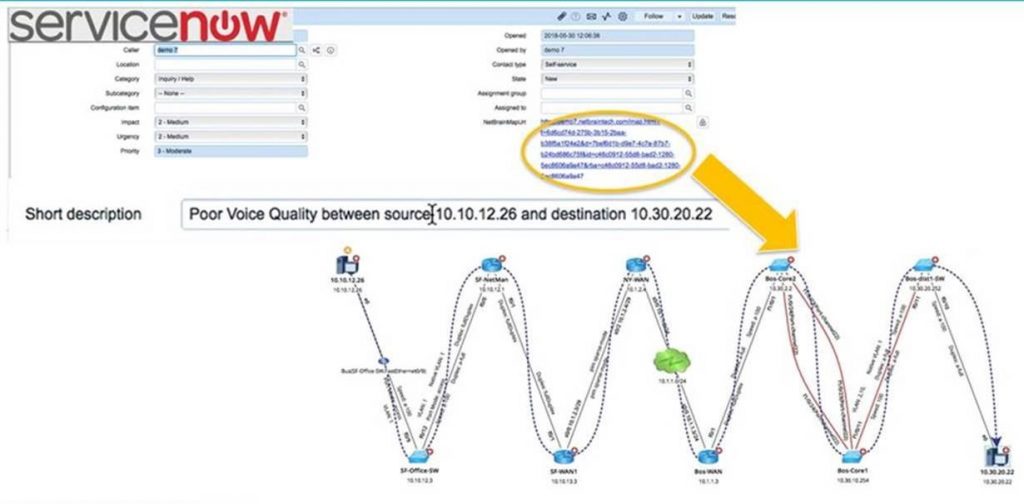
„Just-in-Time“-Netzwerkfehlerbehebung führt die gleichen Schritte aus, die Sie tun würden, nur automatisch – ohne dass Sie anwesend sein müssen, wenn die Warnung eingeht.
Runbooks Schritte zur Problemdiagnose automatisch ausführen
Gleichzeitig – wiederum automatisch – eine ausführbare Datei Runbook sammelt Leistungsdaten und gibt CLI-Befehle auf mehreren Geräten von mehreren Anbietern auf einen Schlag aus, um die relevanten Daten zu erhalten, die Sie benötigen, um genau herauszufinden, was die Langsamkeit verursacht. Sie sehen, wie die Speicher- und CPU-Auslastung aussah, als die Warnung gesendet wurde, sowie den Schnittstellenstatus. Die Runbook sucht automatisch nach Schnittstellenkollisionen und CRC-Fehlern traffic path, prüfen Sie auf Geschwindigkeits- oder Duplex-Nichtübereinstimmung, doppelte OSPF-IDs, falsch konfigurierte AS-Nummern für BGP-Nachbarverbindungen usw. Da unsere erste Frage immer lautet: „Was hat sich geändert?“ a Runbook führt eine vergleichende Analyse der Topologie und des Routings zwischen dem Zeitpunkt der Erkennung des Problems und einem früheren Zeitpunkt (als die App einwandfrei lief) durch. Es sind Hunderte von automatisierten Diagnosen sofort verfügbar, und Sie können eine anpassen Runbook um praktisch jede Datenerfassungs- oder Analyseaufgabe auszuführen – ohne eine einzige Codezeile schreiben zu müssen.
(Matt Speidel geht näher darauf ein in Wie ausführbar Runbooks Arbeit.)
Das Runbook führt die gleichen Schritte zur Fehlerbehebung im Netzwerk durch, nur automatisch – ohne dass Sie anwesend sein müssen, wenn die Warnung eingeht. Und alle Diagnoseergebnisse werden im dokumentiert Runbook das hängt an der Karte. Klicken Sie einfach auf die URL der Karte im Trouble Ticket, und die gesamte Datenerfassung und -analyse, die Sie sowieso durchgeführt hätten, wurde bereits für Sie erledigt.
Ein leitender Netzwerkmanager, den ich kenne, sagte einmal, dass sporadische Probleme nicht besonders sporadisch sind; es ist nur unser Bewusstsein von ihnen. Wenn ein Problem einmal aufgetreten ist, wird es höchstwahrscheinlich wieder auftauchen – oder an anderer Stelle im Netzwerk. NetBrain hat eine neue Funktion eingeführt, mit der Sie die Automatisierungsleistung nutzen können kontinuierlich und proaktiv Überwachen Sie das Problem, das Sie gerade gelöst haben. Mit anderen Worten, diese mysteriösen intermittierenden Probleme werden zu bekannten Problemen.
Sehen Sie sich dieses kurze Video an, um einen Eindruck davon zu bekommen, wie NetBrain lässt sich in andere Systeme integrieren (z. B. ServiceNow, 24×7-Überwachungstools), um „Just-in-Time“-Diagnose zur Netzwerkfehlerbehebung bei einem Netzwerkproblem bereitzustellen, sobald es auftritt.
Wir können uns diese ereignisgesteuerte automatisierte Netzwerkfehlerbehebung auch als „Level-O“-Diagnose vorstellen, da die gesamte Datenerfassung, -analyse und -visualisierung durchgeführt wurde, bevor ein Level-1-Ingenieur überhaupt mit der Untersuchung des Problems beginnt. Tatsächlich erledigt die Automatisierung all diese Arbeit, bevor ein Mensch überhaupt ins Spiel kommt.
Sie können nicht reparieren, was Sie nicht sehen können. In den heutigen schnelllebigen Netzwerkumgebungen sind Probleme zu oft verschwunden, wenn wir uns an die Fehlerbehebung machen. Normalerweise ist die eigentliche Behebung eines zeitweiligen Problems ziemlich einfach. Aber es festzunageln ist es nicht. Hier kommt die Automatisierung „just in time“ ins Spiel.