 by Mark Harris Jan 3, 2022
by Mark Harris Jan 3, 2022
Eines der am häufigsten verwendeten Tools im Netzwerk Fehlersuche ist wohl der Traceroute (und sein kleiner Bruder Ping). So hilfreich dieses Tool auch ist, es gibt einige kritische Herausforderungen bei der Verwendung von Traceroute, um die viel komplexeren Probleme von heute zu bewältigen. Denken Sie daran, dass Traceroute in den späten 1980er Jahren entwickelt wurde, als Netzwerke noch viel einfacher waren. Alles war physisch, Point-to-Point war der letzte Schrei, es gab weniger Protokolle zu handhaben und Switches wurden allgemein als Bridges bezeichnet, wobei LAN-zu-WAN-Router von einem Gebäude zum nächsten gingen. (Denken Sie daran, das war ein halbes Dutzend Jahre, bevor das Internet überhaupt existierte)! Und wer erinnert sich noch an „T1 Leased Lines“? Die gute alte Zeit sozusagen.

Wie halten sich also antike Tools wie dieses in der heutigen Welt des softwaredefinierten und virtualisierten Alles? Sicherlich muss es einen moderneren Weg geben, um bei der Fehlersuche in den heutigen Netzwerken zu helfen? Ja, das gibt es, also lesen Sie weiter…
Lassen Sie uns zunächst etwas mehr darüber verstehen, was ein Traceroute-Befehl ist.
Was ist ein Traceroute-Befehl?
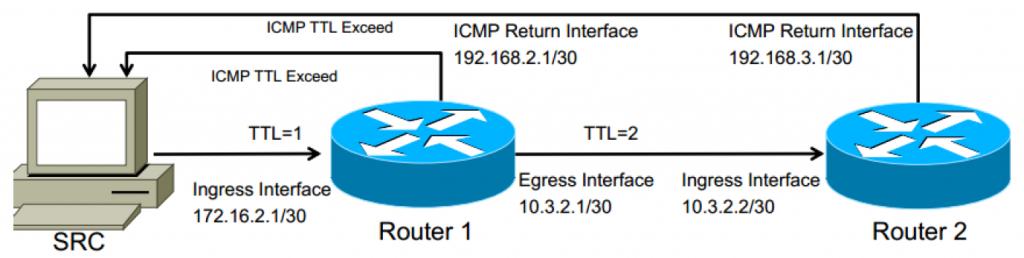
Der Quellcomputer (SRC) sendet normalerweise drei Testpakete an die Ziel-IP-Adresse, beginnend mit der Einstellung Time to Live (TTL) auf 3. Es wird fälschlicherweise angenommen, dass der Typ des Testpakets immer ICMP ist, obwohl er in Wirklichkeit vom Gerät abhängt Ursprung der Traceroute. Windows-Betriebssysteme verwenden häufig ICMP, während Unix- und Routing-Geräte häufiger UDP-Nachrichten an kurzlebige Ports (Ports größer als 1, bei denen es sich nicht um bekannte Dienste wie DNS, SMTP, WEB usw. handelt) verwenden.
Wenn das Prüfpaket an jedem Gerät der Schicht 3 empfangen wird, wird die TTL dekrementiert. Wenn TTL 0 erreicht, sendet das empfangende Gerät eine ICMP-Nachricht „TTL Expired“ von der Schnittstelle, die dieses Paket empfangen hat. So kennt Traceroute jeden Hop auf dem Weg.
In der Abbildung unten wären 172.16.2.1 und 10.3.2.2 die Adressen, die in den Traceroute-Ergebnissen zurückgegeben werden.
Herausforderungen mit Traceroute-Befehlen für heutige Netzwerke:
#1: Asymmetrische Pfade sind nicht leicht zu erkennen. Standardmäßig wird nur A-to-B gemeldet. B-zu-A erfordert eine weitere Traceroute vom anderen Ende, um den Pfad zu vervollständigen.
Asymmetrisches Routing ist heutzutage in Netzwerken weit verbreitet. Es sind viele ECMP-Protokolle (Equal-Cost Multi-Path) und sogar Multi-Path-Routing-Protokolle mit ungleichen Kosten im Einsatz, und abhängig vom Hashing-Algorithmus wird der Datenverkehr wahrscheinlich in jede Richtung einen anderen Weg nehmen. Diese unterschiedlichen Pfade sind mit einer einzigen Traceroute-Befehlsausführung sehr schwer zu erkennen und daher sehr schwierig, genau zu erkennen, woher das Verzögerungsergebnis kommt und beeinflusst wird.
Wie Sie oben sehen können, steigt der Verzögerungswert bei diesem bestimmten Sprung sprunghaft an, aber die Frage ist: „Wo ist diese Verzögerung?“ Ist es auf dem Vorwärtspfad oder auf dem Rückpfad?
#2: Schnittstellen sind nicht bekannt, nur der IP-Knoten des Geräts. Es gibt keine zusätzlichen Details.
Wenn wir uns die Traceroute oben noch einmal ansehen, sind die einzigen bereitgestellten Informationen ein Hostname/eine IP und ein verzögertes Ergebnis. Wenn ein Benutzer Hop 6 untersuchen würde, müsste er eine Telnet/SSH-Verbindung zum Router herstellen und feststellen, an welche Schnittstelle diese IP-Adresse angeschlossen ist (IP-Route 129.259.2.41 anzeigen war meine bevorzugte Methode, dies zu ermitteln, aber Sie könnten die IP-Schnittstelle anzeigen). und leiten Sie die Ausgabe an a weiter parser… IP-Schnittstelle kurz anzeigen | in 129.150.2.41). Zweitens müsste zur Bestimmung der Ausgangsschnittstelle (ausgehend) eine zweite Suche durchgeführt werden, um diese Informationen zu ermitteln (z. B. IP-Route 192.41.37.40).
Nr. 3: Traceroute stützt sich auf ICMP-Nachrichten, die möglicherweise eine längere Verzögerung melden, als vom Datenverkehr tatsächlich wahrgenommen wird, da sie auf dem „langsamen Pfad“ eines Geräts verarbeitet werden und nicht auf dem „schnellen Pfad“, der zum Weiterleiten von Daten verwendet wird, die durch den Router gehen .
Slow-Path lässt sich am einfachsten so zusammenfassen, dass der Router den Inhalt des Pakets verarbeiten muss. Praktisch jedes Paket, das für ein Gerät bestimmt ist, wird auf diese Weise behandelt. Neuere Router verfügen über interne Mechanismen, um zu priorisieren, welche Pakete sie verarbeiten (Routing-Protokollaktualisierungen vor ICMP-Nachrichten), aber dies erhöht das Problem hier nur. Wie wir bereits besprochen haben, verwenden die meisten Systeme eine UDP-Nachricht, aber das Generieren der ICMP-TTL-Ablaufnachricht hat eine niedrigere Priorität, und dann ist der Rückweg eine ICMP-Nachricht, sodass die in den Ergebnissen bereitgestellten Verzögerungsmetriken schwierig sind als echte Probleme akzeptieren.
TIPP: Wenn Sie eine Traceroute sehen, die an einem bestimmten Schritt im Ergebnis springt und alle folgenden Ergebnisse niedrig sind, ist dies ein Hinweis darauf, dass der „langsame“ Router bei der Verarbeitung verzögert ist. Wenn der Pfad springt und dann jeder folgende Schritt entlang des Pfads inkrementiert wird, bedeutet dies typischerweise eine Form von Warteschlangen aufgrund von Staus.
#4: Die Traceroute-Ausgabe ist der statische Text, auf den nicht einfach reagiert werden kann.
Okay, jetzt kennen wir den Weg zu einem bestimmten Ziel, aber was ist, wenn ich tiefer in einen oder mehrere Abschnitte auf diesem Weg eintauchen möchte? Bei einer Telnet/SSH-Konsolensitzung muss sich der Benutzer bei diesen Geräten anmelden. In der Traceroute-Antwort wird nur die IP-Adresse der Schnittstelle angegeben. Dies kann in vielen Netzwerken eine Herausforderung darstellen, da Benutzer aus sicherheitspolitischer Sicht eine Telnet/SSH-Verbindung zur Verwaltungs-IP-Adresse herstellen müssen. Telnet könnte auf den spezifischen Schnittstellen blockiert werden, die in der Traceroute gemeldet werden, was eine manuelle Suche erfordert, um die Verwaltungsschnittstelle eines Geräts mit dieser Schnittstellenadresse zu ermitteln. Ohne DNS-Auflösung ist dies möglicherweise nahezu unmöglich. Bei einem Ausfall kann jede Sekunde zu Ihrem Nachteil zählen.
#5: Pfade mit gleichen Kosten werden nicht dargestellt (nur der tatsächlich zurückgelegte Pfad wird gemeldet).
Wie bereits erwähnt, sind Mehrwegerouten mit gleichen oder ungleichen Kosten heute in den meisten Netzwerken alltäglich. Traceroute meldet nur den spezifischen Pfad, der Teil der Anfragenachrichten war. Da die gängigsten Traceroute-Implementierungen 3 Prüfpakete mit unterschiedlichen UDP-Zielports senden, ist es möglich, dass in einer ECMP-Umgebung für jeden Hop bis zu 3 verschiedene IP-Adressen gemeldet werden. Nachzuverfolgen, welche Antwort Teil welchen Pfads ist, kann mühsam werden.

#6: Traceroute ist Layer-3 (es berichtet nicht über Layer-2-Hops)
Wie wir jetzt verstehen, arbeitet Traceroute daran, den TTL-Wert in einem IP-Paket zu verringern und ICMP-Nachrichten über abgelaufene TTL zu generieren. TTL wird nur auf Layer-3-Geräten dekrementiert, daher gibt es keine integrierte Sichtbarkeit oder die Möglichkeit, den Layer-2-Pfad anhand des Ergebnisses einfach zu bestimmen. In Unternehmens- und Rechenzentrumsumgebungen wird fast immer eine Art Layer-2-Zugriffs-Switch zur Aggregation von Endstationen verwendet. In einigen Designs gibt es auch eine Schicht-2-Verteilungsschicht, bevor sie einen Kernrouter erreicht, der tatsächlich die erste Schicht-3-Routing-Funktion ausführt, die auf eine Traceroute-Anfrage zurückmelden kann. Wenn in der Traceroute-Ausgabe ein Paketverlust angezeigt wird, kann dies an einem fehlerhaften Hashing eines Layer-2-Portkanals oder einer Link Aggregation Group (LAG), einem Spanning Tree-Problem, einer Duplex-Konfiguration auf einem Switch oder einem anderen Problem liegen, das nur von erkannt werden kann Untersuchen der Layer-2-Elemente entlang des Pfads. Um diese Informationen zu finden, wäre Folgendes erforderlich:
- Ermitteln der MAC-Adresse des Quellgeräts auf dem Layer-2-Segment (Überprüfen der ARP-Tabelle auf dem Router oder auf dem Quellgerät,
- Überprüfung der Dokumentation, um festzustellen, welche Switches verwendet werden
- Sich in jeden möglichen Pfad einloggen und MAC-Tabellen auf die spezifische MAC-Adresse prüfen,
- Ausführen von Befehlen zum Überprüfen der Leistung und Konfiguration
- Bestimmung der vom aktiven Gerät wegführenden Trunks
- Melden Sie sich beim nächsten Layer2-Gerät an und wiederholen Sie den Vorgang, bis Sie den ersten Router erreichen.
Dieser Vorgang kann sehr zeitaufwändig sein, insbesondere wenn CDP/LLDP im Netzwerk nicht aktiviert ist oder die Dokumentation veraltet ist.
#7: Traceroute fehlen historische Informationen
Die Ergebnisse, die Sie mit einer Traceroute sehen, sind der aktuelle Zustand. Es gibt keine Möglichkeit festzustellen, wie der Pfad war, als der Datenverkehr erfolgreich war (z. B. gestern). Betrachten Sie die folgende Traceroute. Es wäre gut zu verstehen, was Hop 4 war, bevor sich die Dinge geändert haben, um das mögliche Problem einzugrenzen.
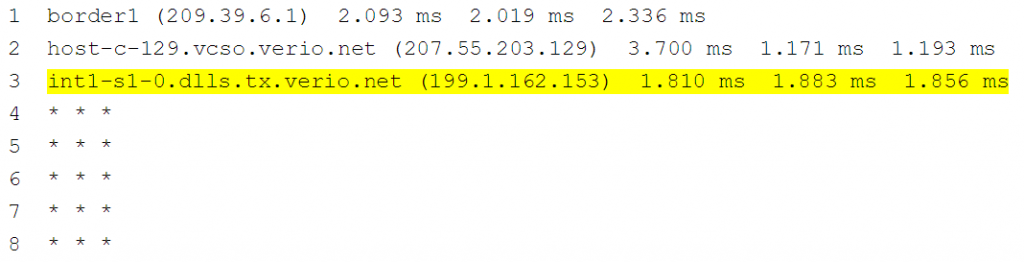
HINWEIS: Unserer Erfahrung nach werden Techniker basierend auf der Ausgabe des obigen Traceroute-Befehls davon ausgehen, dass Hop 3 das Problem ist. Dies ist oft nicht der Fall. Die erste Prüfung, die ein Benutzer durchführen sollte, besteht darin, sich bei Hop 3 beim Gerät anzumelden und zu prüfen, ob das Gerät einen Routing-Eintrag zum Ziel hat. Wenn dies der Fall ist, ist das problematische Gerät häufig der nächste Hop im Routing-Eintrag. Um gründlich zu sein, ist es nützlich, die Egress-Schnittstelle zum nächsten Routing-Hop zu überprüfen, um die Leistung auf Schnittstellenebene und die ACL-Konfiguration zu überprüfen.
#8: Traceroute hat ein kryptisches Fehlermeldungssystem.
Wenn ich auf ein Traceroute-Befehlsproblem stoße, erhalte ich hin und wieder ein Zeichen in der Ausgabe, das mich überrascht. Die folgende Tabelle stammt aus der Traceroute-Implementierung von Cisco. Obwohl sie einfach erscheinen mögen, erfordert das genaue Verständnis dessen, was passiert, fast immer zusätzliche Nachforschungen.
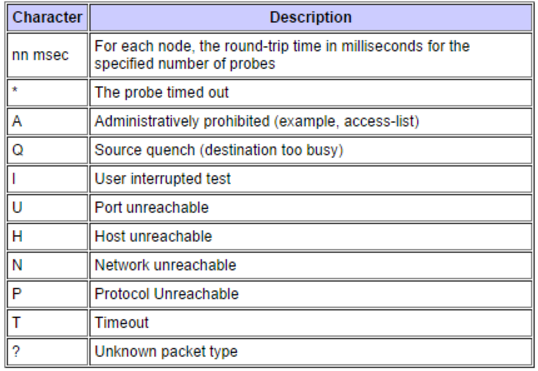
Sagen wir zum Beispiel, ich erhalte den Buchstaben A in der Traceroute-Antwort, ich kann verstehen, dass es wahrscheinlich eine Zugriffsliste gibt, die das Traceroute blockiert, aber welche Zugriffsliste ist das? Um dies festzustellen, muss ich mich beim Router anmelden, feststellen, über welche Schnittstelle das Paket eingetreten ist, die Konfiguration überprüfen und die Zugriffsliste untersuchen, wenn ich sie finde. Dies kann ein langwieriger Prozess sein, und da wir uns bei der Fehlerbehebung immer Gedanken über den Zeitpunkt machen, wäre es großartig, eine bessere Möglichkeit zu haben, auf diese Informationen zuzugreifen.
HINWEIS: Nach unserer Erfahrung werden diese Fehlermeldungen immer nur basierend auf der Ingress-Schnittstelle bereitgestellt. Sobald ein Paket in Ordnung empfangen und dann an den nächsten Hop entlang des Pfads weitergeleitet wird, wenn es eine ACL am Egress-Port gibt, erhalten Sie einfach ein * * * für den nächsten Hop, was zusätzliche Schritte bedeutet, um sicherzustellen, dass die Egress-Schnittstelle bekannt ist. und auch alle ACLs, die an diesem Port validiert wurden.
Was ist die moderne Lösung?
NetBrain umfasst eine Fülle von Automatisierungs- und Visualisierungsfunktionen, die für die Wartung moderner Netzwerke erforderlich sind. Es versteht Software-definiert, virtualisiert und sogar die Cloud. Es kommuniziert kontinuierlich mit jedem Gerät im End-to-End-Netzwerk und erstellt in Echtzeit einen digitalen Zwilling des Netzwerks. Dieser digitale Zwilling ist eine exakte Nachbildung der Details jedes Geräts. Es umfasst die Möglichkeit, Echtzeitnetzwerke zu visualisieren, und enthält einen modernen Ersatz für Traceroute, der als bezeichnet wird A/B-Pfad-Rechner. Dadurch werden all diese Herausforderungen angegangen, indem Ingenieure dynamisch unterstützt werden ein Netzwerk abbilden Pfad zwischen zwei beliebigen Punkten im Netzwerk und stellen Sie extreme Details dieses Pfads bereit. Diese Funktion unterstützt die Zuordnung durch moderne Technologien (z. B. SDN, SD-WAN, Firewalls, Lastausgleich), Underlays und Overlays unter Berücksichtigung erweiterter Protokolle (Routing, Zugriffslisten, PBR, VRF, NAT usw.). Und sobald sie bereitgestellt ist, schafft dieselbe Struktur, die in Echtzeit visualisiert werden kann, nun die perfekte Plattform dafür No-Code-Automatisierung jeder Aufgabe, groß und klein!
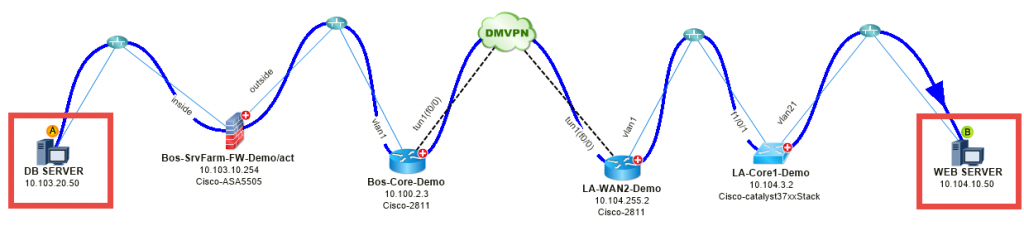
Drei Beispiele aus der Praxis des A/B-Pfadrechners
# 1: Karte eine langsame Anwendung – Eine Webanwendung ist zwischen Boston und Los Angeles langsam.
Nr. 2: Ordnen Sie den VoIP-Verkehrsfluss zu – Der Sprachverkehr zwischen Boston und San Fran ist nervös.
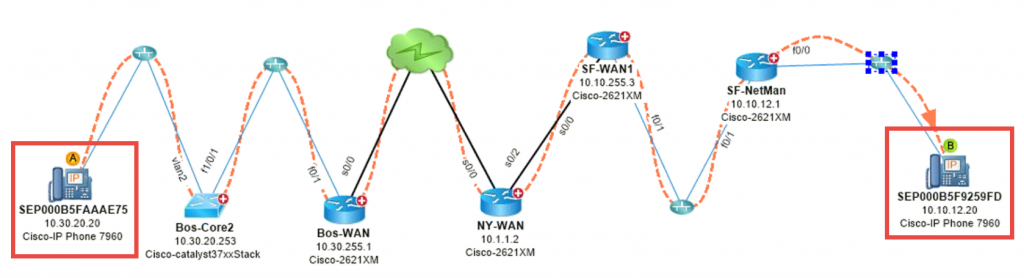
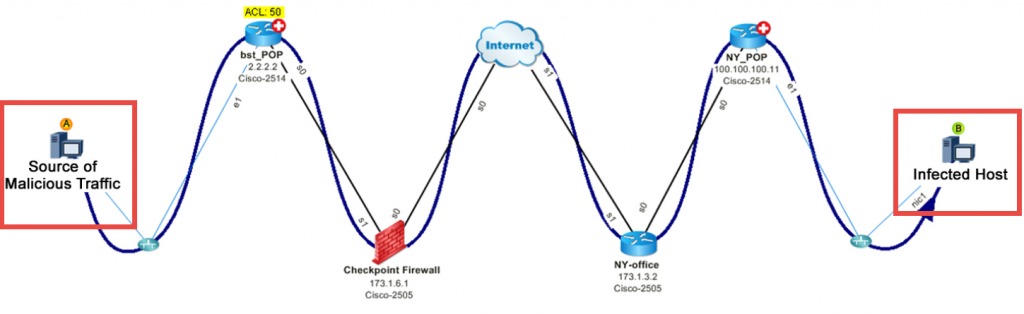
Nr. 3: Map-DDoS-Angriff – Ein bösartiger Host injiziert DoS-Datenverkehr in das Netzwerk. Woher kommt der Traffic und welche Auswirkungen hat er? Indem Sie NetFlow nutzen, um den Top-Talker zu identifizieren, können Sie den Pfad abbilden.
Service-Delivery-Assurance
NetBrain Anwendungssicherung (AAM) bildet alle Ihre Anwendungs-Hybrid-Cloud-Netzwerkpfade in einer einzigen Ansicht ab, validiert kontinuierlich die Leistung der End-to-End-Pfade anhand gesunder Pfad-Baselines und alarmiert proaktiv die richtigen Teams, damit sie auf Probleme reagieren können, bevor sie Ihr Geschäft stören. Es bietet Ihren Teams die Möglichkeit, schnell Fehler bei der Anwendungsleistung auf der Ebene des Datenverkehrsflusses zu beheben und diese zu diagnostizieren.
Es ist jetzt möglich, eine Verschlechterung der Anwendungsleistung zu verhindern NetBrainist kein Code Intent-based automation.
NetBrain AAM schützt das Benutzererlebnis durch:
- Automatische Zuordnung aller möglichen Anwendungspfade und ihrer Geräte
- Definieren von Verhaltensweisen für alle Anwendungspfade
- Abgleich von Live-Anwendungspfaden mit „goldenen“ Pfaden auf Karten
- Visualisierung der Leistung und des Verlaufs jedes Anwendungspfads in einem einzigen Dashboard
- Wir machen Sie auf potenzielle Probleme aufmerksam, sobald die Leistung des Anwendungspfads nachlässt