 by 10. September 2019
by 10. September 2019
Ed. Hinweis: Das folgende Transkript wurde aus der On-Demand-Aufzeichnung gezogen – keine Registrierung erforderlich oder Formular zum Ausfüllen – von NetBrain Just-in-Time-Automatisierung für den IT-Betrieb Webinar. Jason Baudreau, NetBrain VP of Marketing, ist Ihr Gastgeber.
Hier sehen Sie einen typischen Workflow als Reaktion auf ein IT-Ereignis – nehmen Sie zum Beispiel eine langsame Anwendung. Daher verfügen Unternehmensnetzwerkteams in der Regel über eine Ereigniskonsole wie SolarWinds oder Splunk, die zuhört und versucht, alle im Netzwerk auftretenden Anomalien zu erkennen. Oder vielleicht ist es nur ein Benutzer, der den Helpdesk anruft, um ein Ticket zu erstellen. Sie werden diese Ticketing-Systeme wie ServiceNow oder BMC Remedy für das Incident Management haben.
Dieses Problem wird normalerweise von einem Tier-1-Ingenieur aufgegriffen. Wenn es dann nicht trivial ist, wird es an jemanden mit mehr Fachwissen eskaliert, der bei der Lösung helfen kann. Dann gibt es die Behebung: die eigentliche Änderung oder die eigentliche Korrektur, die vorgenommen werden muss. Und schließlich überprüfen die Teams, was passiert ist, um zu sehen, wie sie es beim nächsten Mal besser machen können. Dies erfolgt in der Regel durch eine Post-Mortem-Analyse-artige Aktivität.
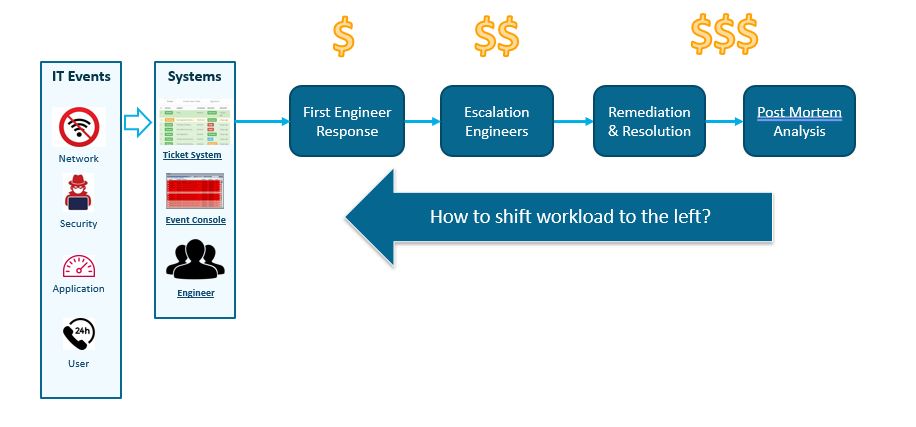
Die Frage ist also: Was können wir tun, um diesen Workflow nach links zu verschieben? Denn je weiter dieser Workflow fortschreitet und die Probleme eskalieren, desto teurer werden die beteiligten Teams.
- Wie können grundlegende Tier-1-Engineering-Aufgaben automatisiert werden?
- Wie können First-Level-Ingenieure es mit Fortgeschrittenen aufnehmen? Fehlersuche?
- Wie können Teams die bei jedem Fehlerbehebungsereignis gewonnenen Erkenntnisse demokratisieren, um es beim nächsten Mal besser zu machen oder sogar das Auftreten von Problemen zu verhindern?
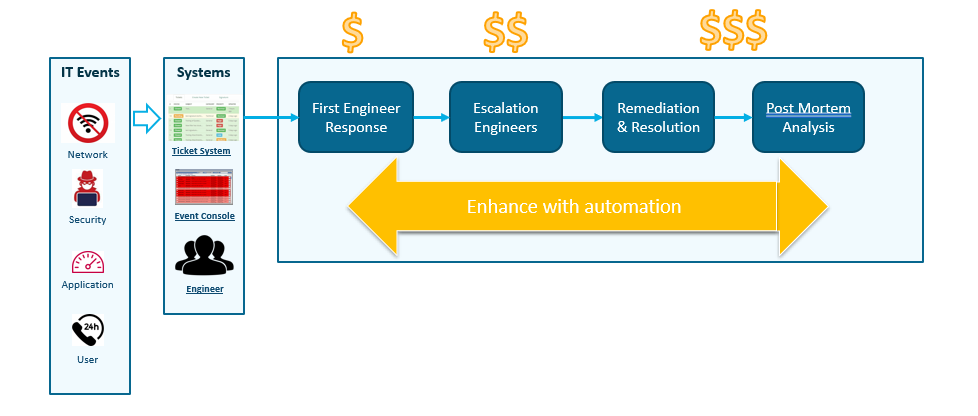
Dieser Workflow kann durch Automatisierung letztendlich nach links verschoben werden. Die Automatisierung kann bei jedem Schritt dieses Workflows genutzt werden, von dem Moment an, in dem ein Ereignis erkannt wird, bis hin zur Post-Mortem-Analyse – mit dem ultimativen Ziel, die mittlere Reparaturzeit zu verkürzen (MTTR) und während dieser Reaktion Einsatzteams effektiver einzusetzen.
Sehen Sie sich die 2-Minuten-Aufzeichnung an
Next Up:
Diskussion und Demo der ereignisgesteuerten Netzwerkautomatisierung
Vereinfachung der Netzwerkkomplexität mit interaktiver Automatisierung (mit Demo)
Fehlersuche ist ein Teamsport: Automatisierung fördert die Zusammenarbeit (mit Demo)
Machen Sie sicherere Änderungen: Automatisierte Änderungsvalidierung (mit Demo)
Oder schau dir das ganze an Just-in-Time-Automatisierung für den IT-Betrieb Webinar-On-Demand-Aufzeichnung – keine Registrierung oder Formular zum Ausfüllen erforderlich.