 by 31. August 2018
by 31. August 2018
Heutige Netzwerkprobleme erfordern zunehmend mehr als einen einzelnen Techniker – oder mehr als ein Team – um sie zu lösen. Diese Probleme können einen Teil des Netzwerks (oder eine Technologie) betreffen, mit dem Sie nicht vertraut sind, es können wirklich knifflige Probleme sein, die an einen leitenden Ingenieur mit umfassenderem „Stammeswissen“ eskaliert werden müssen, oder sie können es sein Probleme sein, die außerhalb Ihres unmittelbaren Verantwortungsbereichs liegen. Diese Art der kollaborativen Fehlerbehebung ist nicht ungewöhnlich, und Lücken in der IT-übergreifenden Zusammenarbeit sind erheblich. NetBrain's State of the Network Engineer-Umfrage offenbarte den Mangel an Zusammenarbeit als größtes Hindernis für eine effektive Fehlerbehebung.
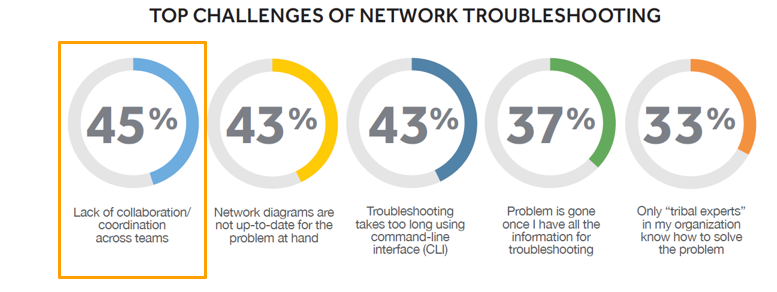
Was also verhindert die Zusammenarbeit innerhalb und zwischen Teams? Selten liegt es daran, dass es eine Art absichtliche Sturheit gibt – eine „wir gegen sie“-Mentalität. Es ist nicht so, dass wir das nicht tun wollen mit anderen Ingenieuren oder anderen Gruppen zusammenzuarbeiten. Es ist nicht so, dass weniger erfahrenes Personal einfach den Schwarzen Peter weitergibt oder dass hochrangige Leute die Brandbekämpfung lieben. Die Zusammenarbeit wird behindert, weil es so schwierig ist:
- Geben Sie jeder Person, die an dem Problem arbeitet, die Sichtbarkeit, die sie sofort und an Ort und Stelle benötigen, um das Problem anzugehen.
- Waten Sie durch einen Ozean von Daten, um die Informationen zu erhalten, die für die jeweilige Aufgabe benötigt werden.
- Teilen Sie diagnostische Ergebnisse, damit der nächste Mann – klar und sofort – sehen kann, welche Analyse bereits durchgeführt wurde.
Diese Herausforderungen sind noch ausgeprägter, wenn es um die Minderung von Netzwerksicherheitsproblemen geht, wenn eine effektive Zusammenarbeit oft den Unterschied zwischen einer ausgereiften, rechtzeitigen Reaktion auf eine Bedrohung und einem Angriff ausmachen kann, der Ihr Netzwerk lahmlegt.
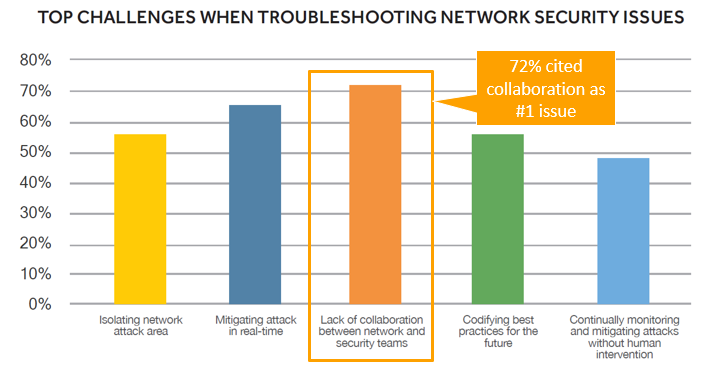
Bringen Sie alle auf dieselbe Seite – im wahrsten Sinne des Wortes
Die großen Netzwerke von heute unterliegen ständigen Änderungen – Break/Fix-Modifikationen, Geräte- und Software-Upgrades, architektonische Weiterentwicklung –, wobei Änderungen von verschiedenen Personen und verschiedenen Teams ausgeführt werden. Herkömmliche Netzwerkdiagramme veralten schnell, und allzu oft sind kritische Designnotizen und andere Dokumentationen unvollständig (eher nicht vorhanden). Moderne Unternehmen haben ein disparates und dezentralisiertes Verständnis ihres Netzwerks, von Campus zu Campus, von funktionalem Team zu funktionalem Team. Die Zeiten einzelner Ingenieure mit Fachwissen in allen Bereichen eines Unternehmensnetzwerks sind vorbei.
Dies führt ein Sichtbarkeitsproblem: Sie haben kein klares Bild davon, wie das Live-Netzwerk tatsächlich aussieht. Zu oft sind Sie einfach nicht in der Lage, die kritischen IT-Daten in dem Moment zu visualisieren, in dem sie benötigt werden, kontextualisiert für Ihre spezielle Aufgabenstellung. Herkömmliche Netzwerkdiagramme sind nur symbolgesteuerte Topologiekarten, bei denen statische Bilder Geräte darstellen, denen es jedoch an Intelligenz mangelt. NetBrain Dynamic Maps, hingegen sind datengesteuert – jedes Element repräsentiert einen „digitalen Zwilling“ eines Live-Netzwerkgeräts mit Hunderten von Datenattributen, einschließlich seiner Konfigurationsdatei, Routing-Protokolle, Nachbarn und mehr. Die Deep Discovery (nicht nur über SNMP, sondern auch über Telnet/SSH), die dieses mathematische Modell erstellt, bedeutet, dass die Dokumentation, die Sie für eine effektive Fehlerbehebung benötigen, automatisch gepflegt und aktualisiert wird. Sie können Erstellen Sie eine Karte speziell für die jeweilige Aufgabe On Demand: Vollständige und genaue Informationen stehen Ihnen jederzeit zur Verfügung, wenn Sie sie am dringendsten benötigen.
NetBrainDie tiefgreifende Entdeckung von bedeutet, dass Sie bei Bedarf eine Karte speziell für die jeweilige Aufgabe erstellen können.
Fazit: Sie haben jetzt nicht nur ein Diagramm, sondern eine gemeinsam genutzte forensische Konsole mit praktisch unbegrenzten Details, auf die jeder überall zugreifen kann. Alle relevanten Netzwerkinformationen können direkt auf der Karte visualisiert werden, wodurch sie einfacher mit anderen Teams geteilt werden können. Schalten Sie einfach die Kontextdaten ein oder aus, die Sie für das zu behebende Problem benötigen. Sehen Sie sofort Ihr EIGRP- oder OSPF-Design auf einen Blick, überprüfen Sie den Aktiv-/Standby-Status für ASA-Failover-Geräte – die Liste lässt sich fortsetzen. Nahezu alle Daten aus beliebigen Quellen können in einem erfasst werden Dynamic Map — Leistungsdaten von Ihrem 24×7-Überwachungstool (z. B. SolarWinds), offene Tickets von ServiceNow, Splunk-Daten. Wenn es eine API hat, NetBrain kann die Daten aufnehmen und direkt von der Karte aus mit dem Quellsystem zurückverlinken.
NetBrainDie einzigartige Fähigkeit von , (a) Telnet/SSH-Daten von jedem Gerät in einem Multi-Vendor-Netzwerk und (b) relevante Informationen aus anderen Quellen über REST-APIs zusammenzuführen, bedeutet, dass Sie jetzt auch SDN-Konstrukte wie die Cisco ACI-Fabric visualisieren können wie Ihr traditionelles Netzwerk auf einem Dynamic Map. Dies ist beispielsweise bei der Fehlerbehebung einer langsamen Anwendung, die sowohl über die ACI-Fabric als auch über das Legacy-Netzwerk fließt, von unschätzbarem Wert.
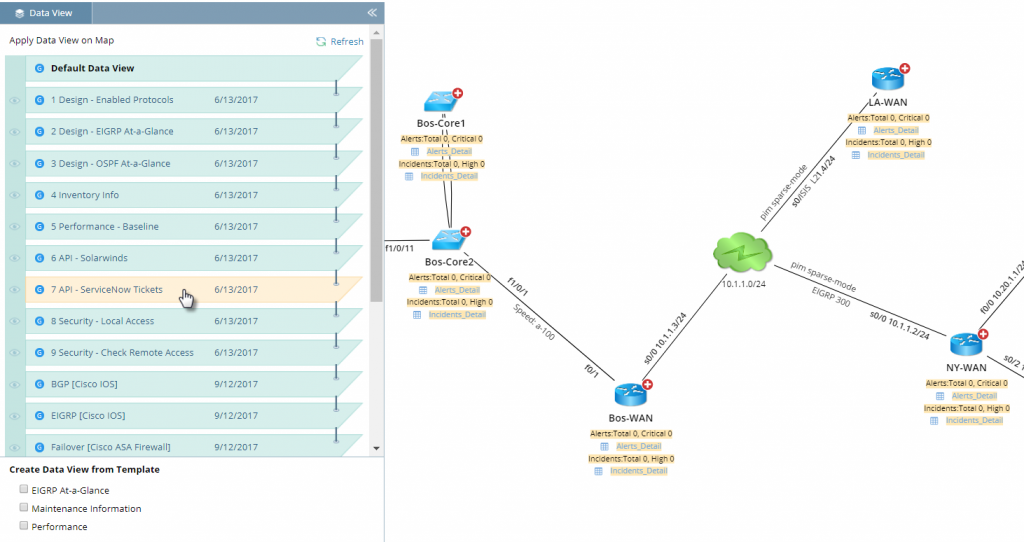 Schalten Sie praktisch alle Netzwerkinformationen – einschließlich anderer NMS-Daten – direkt auf der Karte ein oder aus.
Schalten Sie praktisch alle Netzwerkinformationen – einschließlich anderer NMS-Daten – direkt auf der Karte ein oder aus.
Nie wieder Protokolldateien per E-Mail versenden und textbasierte Datendumps durchwühlen. Kein manuelles Durchsuchen der CLI mehr, ein Gerät nach dem anderen, ein Befehl nach dem anderen, oder das Springen von Bildschirm zu Bildschirm zwischen verschiedenen Tools, um Informationen zusammenzuschustern.
Sie erhalten einen umfassenden Einblick in Ihr Netzwerk auf einer echten einzigen Glasscheibe, auf der jeder und jede die Daten tatsächlich nutzen kann – die Karte.
Sehen Sie, wer was wann gemacht hat
Der typische manuelle, sich wiederholende Workflow zur Fehlerbehebung erfordert eine Menge doppelten Aufwand, um Daten zu überprüfen. Da Fälle zwischen verschiedenen Ebenen von Ingenieuren eskaliert werden, sind die Diagnosedaten normalerweise entweder zu viel oder zu wenig. Wenn wir unter die Lupe genommen werden, hinterlassen wir allzu oft nur flüchtige Notizen für die Ingenieure der nächsten Ebene. Kritische Informationen gehen unterwegs verloren oder werden in Log-Dumps vergraben. Wenn Sie der nächste Mann sind, müssen Sie dieselben Diagnosen wie der vorherige Typ erneut durchführen – entweder weil es schneller ist, als einen Haufen Textdaten zu durchsuchen, oder weil Sie einfach nicht sicher sind, dass er danach gefragt hat richtige Fragen. Am Ende erfinden Sie das Rad neu.
Aber mit Automatisiert Runbooks, können all diese „first best step“-Diagnosen, die Sie immer durchführen, automatisch durchgeführt werden – wobei die Ergebnisse automatisch erfasst und aufgezeichnet werden. Next-Level-Ingenieure können genau sehen, welche Analysen bereits durchgeführt wurden (und wann und von wem), wobei die Diagnoseergebnisse übersichtlich auf dem angezeigt werden Dynamic Map im Zusammenhang. (Lerne mehr über Wie ausführbar Runbooks Arbeit.)
Allzu oft erfinden Sie das Rad neu – Sie führen dieselben Fehlerbehebungsdiagnosen erneut durch, nur weil Sie Erkenntnisse aus dem Datendump des vorherigen Mitarbeiters ziehen können.
Im folgenden Beispiel wird die Runbook kommentierte die QoS-Konfiguration auf dem zugeordneten Teil des Netzwerks, führte automatisch CLI-Befehle auf allen Geräten auf einen Schlag aus, hob die Warteschlangenstrategie hervor und überprüfte die QoS-Leistungsmetriken. Alle Ergebnisse dieser Schritte sind auf der Karte verfügbar. Als Ingenieur der nächsten Stufe haben Sie gerade das Karussell der Wiederholung von Diagnosen vermieden.
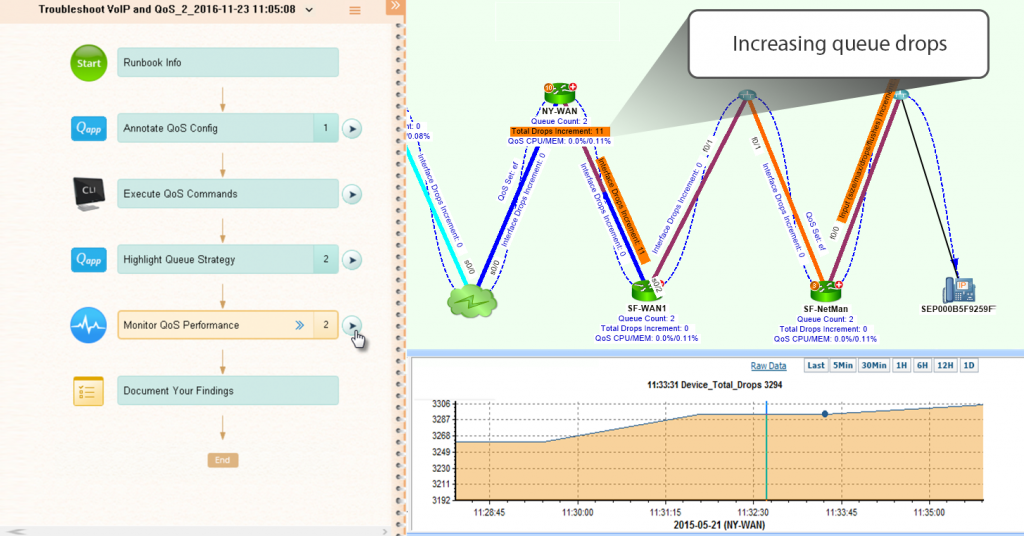 Bei der Fehlerbehebung bei QoS, Runbooks erleichtern das Teilen von Leistungsmetriken auf der Karte (aktuelle Warteschlangenanzahl, Gesamtausfälle, Erreichbarkeit und QoS-CPU/Speicherauslastung).
Bei der Fehlerbehebung bei QoS, Runbooks erleichtern das Teilen von Leistungsmetriken auf der Karte (aktuelle Warteschlangenanzahl, Gesamtausfälle, Erreichbarkeit und QoS-CPU/Speicherauslastung).
Runbooks erleichtern auch die effektive Kommunikation mit anderen Ingenieuren und anderen Teams. Sie können eine bestimmte Person auf ein bestimmtes Gerät oder eine bestimmte Karte aufmerksam machen, wenn Sie Probleme eskalieren. Im folgenden Beispiel habe ich (als Ersthelfer-Ingenieur) den AB-Pfad zwischen einem Webserver und einem Datenbankserver berechnet, einen Ping-Test durchgeführt und einen Overall Health Monitor Qapp (eines der NetBrain's anpassbare Programme, die die Automatisierung nutzen, um Daten von Netzwerkgeräten abzurufen und zu analysieren), die die 5 häufigsten Ursachen für langsame Netzwerke überwacht (Schnittstellenstatus und Verbindungsleistung wie Verzögerung, Fehler und Auslastung). Alles sah in Ordnung aus, also muss ich das Problem an einen Techniker der zweiten Ebene, Jason, weitergeben. Die Funktion @Erwähnung lokalisiert die Hilfeanfrage an Jason, und die Funktion #Erwähnung gibt die eindeutige URL der an Dynamic Map wo er alle Diagnoseergebnisse finden kann. Jetzt habe ich Jason einen schnellen Start gegeben, um herauszufinden, was los ist – er muss nicht bei Null anfangen.
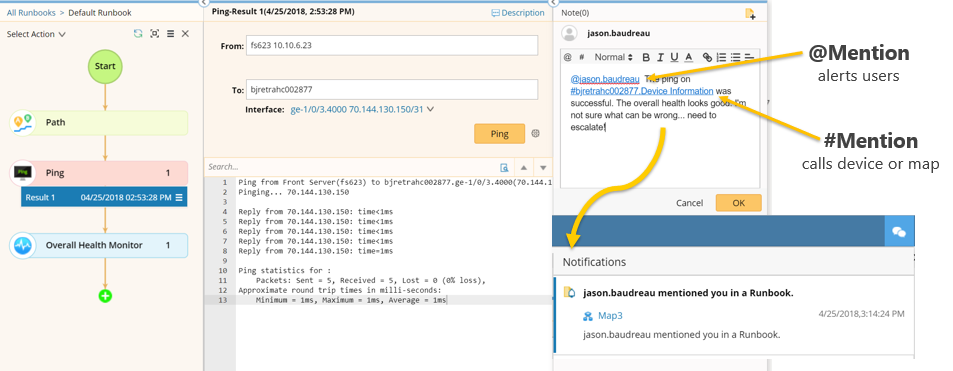 Runbooks erleichtern den Austausch von Erkenntnissen und die Eskalation von Problemen bei der Zusammenarbeit an einem Event.
Runbooks erleichtern den Austausch von Erkenntnissen und die Eskalation von Problemen bei der Zusammenarbeit an einem Event.
Digitalisieren Sie Ihr Stammeswissen
Nachdem das Problem gelöst ist, ist normalerweise jede Post-Mortem-Analyse begrenzt. Die Rohdaten, die wir während der Fehlerbehebung (CLI-Ausgabe) gesammelt haben, gehen verloren, und ich habe möglicherweise etwas gelernt oder auch nicht, das mir helfen würde, wenn diese Art von Problem das nächste Mal wieder auftaucht (was höchstwahrscheinlich der Fall sein wird). Wenn ich Glück hätte, hätte Jason – der Typ, an den ich das Problem eskalieren musste – mir gezeigt, was er tat. Aber Jason ist wie die meisten anderen erfahrenen Netzwerktechniker heutzutage: Sobald dieses spezielle Problem gelöst ist, gibt es noch eine Million mehr an Deck. Er hat einfach keine Zeit zu erklären, wie er es gemacht hat, er hat es einfach geschafft und ist weitergezogen.
Das ist wo NetBrain Runbooks kommen herein. Er könnte seine Fehlerbehebungsschritte im ausführen Runbook (macht die gleichen Dinge, die er manuell tun würde, nur mit NetBrain führen sie automatisch aus), damit sie im Handumdrehen dokumentiert werden. Keine Codierung erforderlich. Wenn diese Art von Problem das nächste Mal auftaucht, kann ich das ausführen Runbook und führen Sie die gleichen nächsten Schritte aus, die Jason getan hat.
Im Grunde haben wir sein Know-how übertragen und es ihm ermöglicht, sein Fachwissen zu teilen, ohne einen Takt zu verpassen.
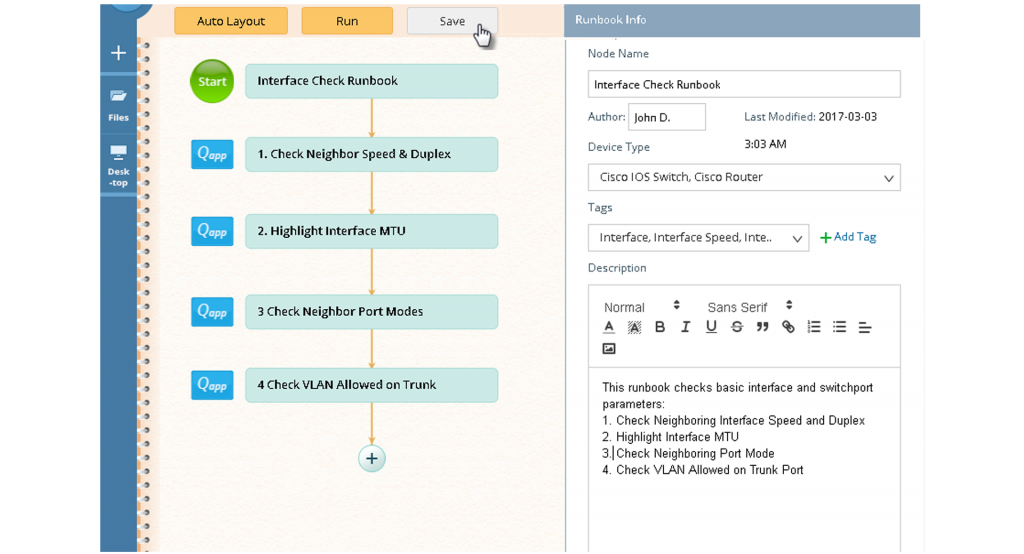 Jeder kann sein spezielles Fachwissen in digitalisieren Runbook Workflows ohne spezielle Programmierkenntnisse.
Jeder kann sein spezielles Fachwissen in digitalisieren Runbook Workflows ohne spezielle Programmierkenntnisse.
Netzwerktechniker müssen sich keine Gedanken mehr darüber machen, wer auf der richtigen Dateifreigabe ist, gedruckte Ordner verteilen oder sich auf ein handgeschriebenes Notizbuch mit Spiralbindung in einer feuerfesten Box im NOC verlassen. Stattdessen sind alle Datenteams, die zusammenarbeiten müssen, in der enthalten NetBrain Plattform.
Will sehen Dynamic Maps und Runbook Automatisierung in Aktion? Haben sie Fragen? Sehen Sie sich eine unserer täglichen Live-Produktdemos mit Frage-und-Antwort-Sitzungen an.
Sehen Sie hier den Zeitplan.