 by Augustus 1, 2018
by Augustus 1, 2018
Wanneer hij wordt aangevallen door netwerkbeveiligingsbedreigingen, beschikt u over een groot aantal tools – inbraakdetectiesystemen (IDS), inbraakpreventiesystemen (IPS), antivirussoftware, beveiligingsinformatie en gebeurtenisbeheer (SIEM)-technologieën – die geen tijd verspillen door u een waarschuwing te sturen dat er iets mis is.
Wanneer een potentiële dreiging wordt geïdentificeerd, is snelheid van essentieel belang. Hoe sneller bedreigingen voor de netwerkbeveiliging kunnen worden gelokaliseerd, geïsoleerd en beperkt, hoe kleiner de kans is dat daadwerkelijke schade of verlies optreedt. Hoewel het waarschuwingsproces volledig geautomatiseerd is, waardoor er bijna geen tijd wordt verspild aan het opsporen van problemen, is de typische workflow voor beveiligingsreacties nog steeds grotendeels handmatig en tijdrovend. Hier komen zichtbaarheid en automatisering om de hoek kijken.
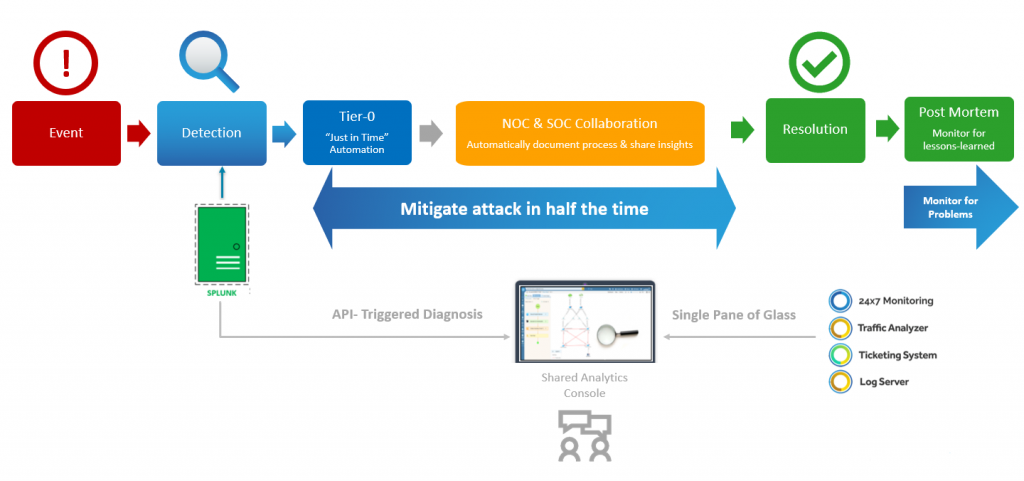 Wanneer elke seconde telt, activeert "just in time"-automatisering een tier-0-diagnose die de tijd om aanvallen te beperken drastisch verkort.
Wanneer elke seconde telt, activeert "just in time"-automatisering een tier-0-diagnose die de tijd om aanvallen te beperken drastisch verkort.
Inzicht verkrijgen in de impact van netwerkbeveiligingsbedreigingen
Eerst en vooral moet u de impact van netwerkbeveiligingsbedreigingen begrijpen. Uw IDS/IPS of SIEM bieden u niet veel inzicht, behalve dat u wordt geïnformeerd dat er mogelijk kwaadaardig verkeer is. Uw netwerkdiagrammen geven u een idee van hoe het netwerk is verbonden, zodat u ziet wat de potentiële impact is. Maar diagrammen zijn maar al te vaak onvolledig of verouderd. Je moet óf op je geheugen vertrouwen – wat steeds uitdagender wordt in complexe, softwaregedefinieerde en hybride omgevingen met meerdere leveranciers – óf je moet handmatig een aantal CLI-opdrachten geven en door stapels tekstuitvoer bladeren. Hierdoor krijgt u inzicht in de configuratie en het ontwerp op apparaatniveau, maar niet op netwerkniveau. Dat is veel tijd om een zeer beperkt beeld van de situatie te krijgen. En als al het andere faalt, moet je de zaken escaleren naar een ingenieur op hoger niveau. Maar zoals we allemaal weten, is het gemakkelijker gezegd dan gedaan om de deskundige te vinden die het bloeden kan stoppen. Traditionele ‘datasilo’s’ tussen het NOC en het SOC zorgen ervoor dat de samenwerking en escalatie niet bepaald naadloos verlopen: verschillende teams vertrouwen op verschillende tools, verschillende systemen en verschillende datasets.
“Just in Time”-automatisering om bedreigingen voor de netwerkbeveiliging te beperken
Stel dat een aanvaller probeert een gericht apparaat te overweldigen met ICMP-echoverzoekpakketten (pingflood). Uw IPS detecteert de dreiging en genereert een SNMP-trap naar Splunk. Splunk ontvangt de valstrik en activeert met behulp van een zoek- en waarschuwingsmechanisme een API-aanroep naar NetBrain met invoerparameters Bron (aanvaller) en Bestemming (slachtoffer).
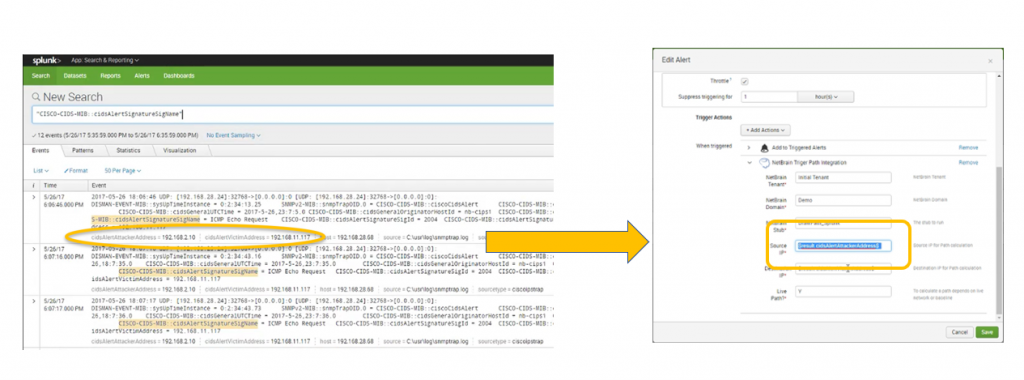 Zodra Splunk netwerkbeveiligingsbedreigingen detecteert, worden API-aanroepen geactiveerd NetBrain om het probleemgebied automatisch in kaart te brengen en het probleem in realtime te diagnosticeren.
Zodra Splunk netwerkbeveiligingsbedreigingen detecteert, worden API-aanroepen geactiveerd NetBrain om het probleemgebied automatisch in kaart te brengen en het probleem in realtime te diagnosticeren.
NetBrain doet dan twee dingen automatisch:
- Het berekent het pad tussen aanvaller en slachtoffer, bouwt een Dynamic Map van het aanvalspad en geeft automatisch de URL van deze map terug aan Splunk.
- Het voert een Runbook — een programmeerbare (en aanpasbare) reeks procedures voor het verzamelen en analyseren van specifieke netwerkgegevens — die de eerste stappen voor probleemoplossing uitvoert, prestatiestatistieken vastlegt en de netwerkstatus documenteert op het moment dat de dreiging werd gedetecteerd.
We noemen dit een niveau-0-diagnose omdat al deze triage en analyse automatisch plaatsvindt, voordat er ook maar een mens bij betrokken raakt. De 'just in time'-automatiseringsmogelijkheden geven u realtime inzicht in en analyses van netwerkbeveiligingsbedreigingen terwijl ze zich voordoen.
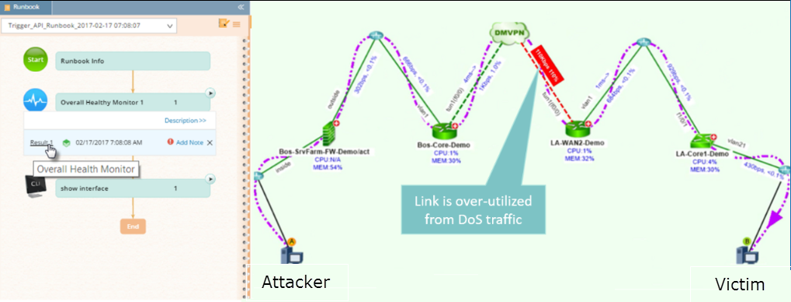
NetBrain maakt automatisch een Dynamic Map van het aanvalspad en uitvoerbaar Runbooks automatisch alle gegevens voor u verzamelen en analyseren.
Alle diagnostische resultaten worden direct in het Runbook. Deze gedeelde analyseconsole stelt iedereen in staat om te zien wie wat wanneer heeft gedaan - waardoor het niet meer nodig is om het wiel opnieuw uit te vinden tijdens escalatie (voer dezelfde analyses uit als de vorige ingenieurs) en om verschillende teams (NOC en SOC) op dezelfde pagina te krijgen om een aanval te beperken. Sterker nog, een NetBrain klanttevredenheid ontdekte dat het gebrek aan samenwerking tussen netwerk- en beveiligingsteams de grootste uitdaging was bij het oplossen van netwerkbeveiligingsproblemen. NOC- en SOC-teams kunnen processen automatisch documenteren (door maatwerk Runbooks on the fly met welke volgende beste stappen er ook moeten worden genomen) en deel kritische inzichten die de tijd tot een oplossing drastisch verkorten.
Organisaties hebben al lange tijd de mogelijkheid om automatisch waarschuwingen te genereren wanneer duidelijke bedreigingen voor de netwerkbeveiliging hun netwerk aanvallen. Wordt het niet eens tijd dat de ingenieurs die belast zijn met het beperken van deze aanvallen hetzelfde niveau van automatisering in hun arsenaal hebben?
Lees meer over hoe NetBrain kan u helpen bij uw veiligheidsinspanningen.
Bekijk onze blog op Zorgen voor effectieve beveiliging en netwerksamenwerking.