Automatisation du réseau
Automatisation sans code
Network Intent
Network Intent révolutionne la conception de réseau en offrant une approche sans code pour la découverte automatique des périphériques et des chemins de réseau multifournisseurs, en établissant des lignes de base de conception et en garantissant l'application de la conception de réseau. Avec Network Intent, les ingénieurs peuvent documenter les références de conception, les états opérationnels et les conditions sans codage. Plus important encore, Network Intent permet la validation et la vérification automatisées des conceptions de réseau. Pour le dépannage du réseau, Network Intents, en tant que logiciel d'automatisation de réseau, sont modélisés pour une vérification inter-réseaux évolutive des violations de conception. Pas de code intent-based network automation empêche de manière proactive les perturbations du réseau et réduit considérablement le temps moyen de résolution (MTTR) lorsque des problèmes similaires se reproduiront à l'avenir.
- Network Intent décrit une conception de réseau et l'état opérationnel prévu
- Cela inclut des références telles que la configuration et l'état de fonctionnement pour vérifier qu'une conception fonctionne correctement
- Ils incluent une logique de diagnostic basée sur des commandes booléennes pour une analyse facile à vérifier par rapport aux lignes de base

Cela offre un moyen rapide et visuel de voir si le réseau a dévié de la design intent et base opérationnelle
Types d' Network Intents
-
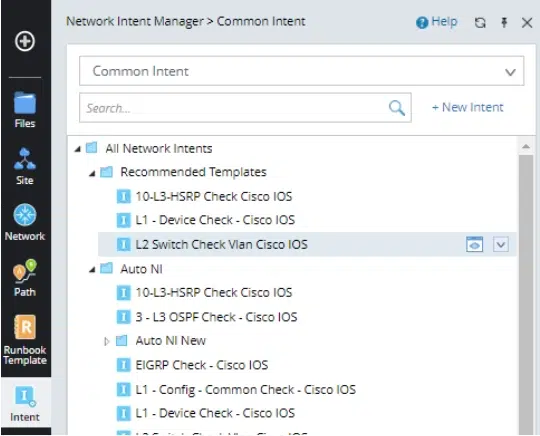
- Autonome – automatisation du réseau Intention commune Réside dans un dossier du gestionnaire d'intentions
-
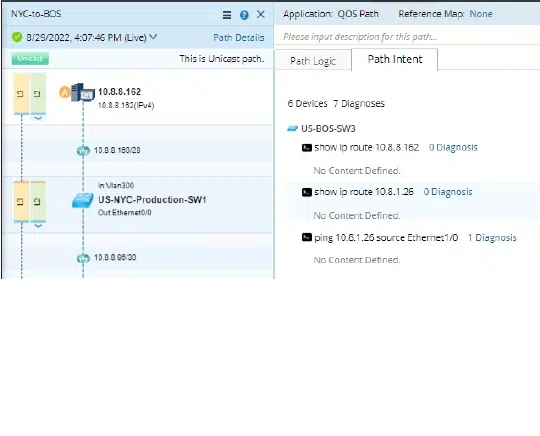
- Intention de chemin – Coexister avec un chemin
-
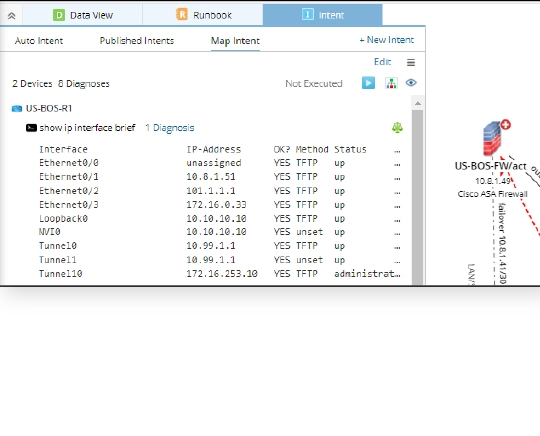
- Map Intent – Coexister avec une carte
Création de la Network Intent - Visuel Parser – Passerelle vers la programmabilité sans code
NetBraindu visuel Parser vous permet de transformer rapidement la sortie de la commande CLI/SNMP/API de l'appareil ou le texte du fichier de configuration en variables programmables sans codage pour activer "Ce que vous voyez est ce que vous pouvez programmer". Les ingénieurs réseau peuvent analyser le fichier de configuration et la sortie de la commande CLI/SNMP/API pour de nombreux problèmes et produire une automatisation de diagnostic sans code qui peut être utilisée par n'importe quel ingénieur réseau.
Pour prendre en charge les données ACI et cloud à l'aide du visuel parser, prise en charge de l'API Parser :
- API vSupport dans la définition de la source de données
- Fonction de récupération de données vDefine pour l'API Parser
- vFournir le groupe JSON pour analyser le résultat JSON
La logique booléenne permet une correspondance complexe des critères dans un seul bloc de diagnostic. Le diagnostic d'intention prend en charge les opérateurs ET et OU pour correspondre à plusieurs conditions.
Le système vous permet de définir les multiples types suivants de parser or parser groupes pour analyser les variables. Pour chaque type de parser groupe, un ensemble de parser les règles fonctionnent ensemble pour définir comment les variables sont extraites du texte brut. Avec des règles valides, le parser le résultat s'affiche instantanément dans le volet de sortie et les données brutes correspondantes sont mises en surbrillance au survol de la souris.
Network Intent en tant qu'unité d'automatisation

Chaque réseau a le sien design intent et les normes de configuration. En tirant parti intent-based automation, NetBrain peut vérifier l'encodé design intent et les normes de configuration dans le Network Intents contre le réseau en direct automatiquement et périodiquement. Ces intentions peuvent être modélisées, stockées et partagées avec toute l'équipe pour l'évolutivité.
Modélisation du réseau dans des tables de données d'automatisation
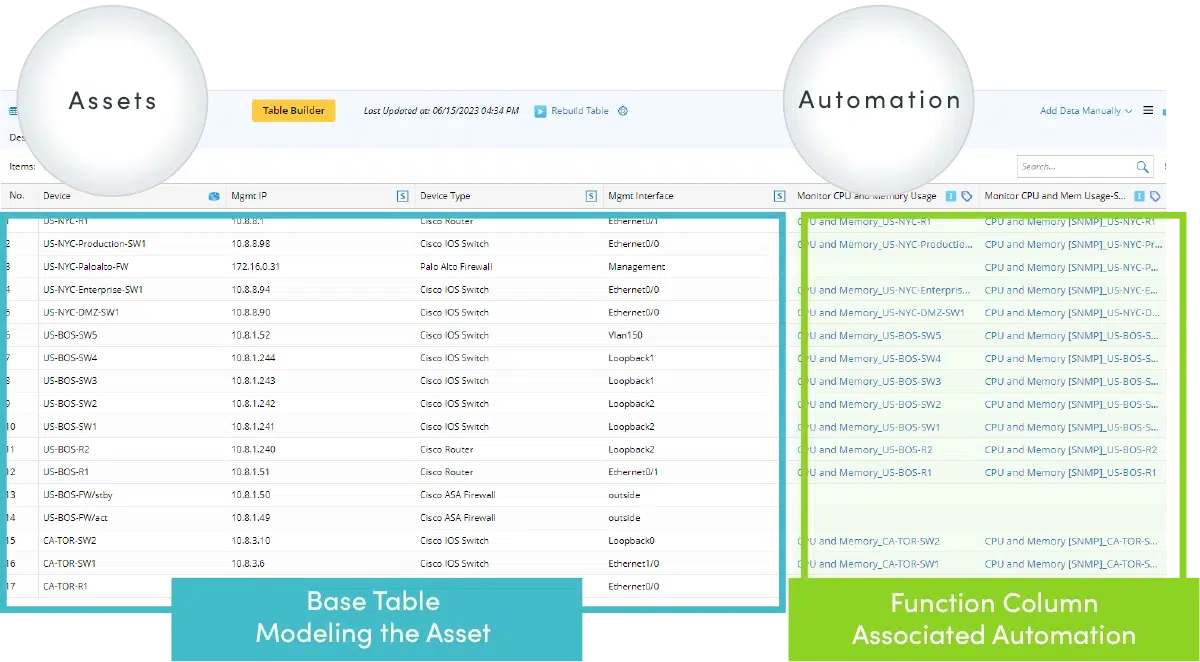
L'Automation Data Table (ADT) est une base de NetBrain NextGen qui modélise les actifs réseau critiques et vous aide à gérer les intentions associées tout en prenant en charge la création et la réplication d'intentions. Chaque colonne représente une nouvelle automatisation. NetBrainLa bibliothèque d'automatisation de est le backend qui construit la base d'automatisation des intentions pour les ADT.
- Il n'y a qu'un seul ADT par fonction/tâche (c.-à-d. Toutes les vérifications d'application, tout flux de travail - préventif, sécurité, vérifications de l'état, anti-dérive (préventif), basculement, problèmes BGP, problèmes d'interface, application lente, routes critiques, modifications récentes, politiques de pare-feu)
- Il vous permet de créer, d'organiser et de partager des intentions d'automatisation sur le réseau de cloud hybride
- Personnalisez les ressources d'automatisation du réseau dans Automation Data Table Manager, telles que l'application et le chemin critiques, la liaison WAN critique, le basculement de périphérique critique, le sous-réseau critique et la route critique, puis associez les intentions et le résultat du diagnostic pour résoudre les problèmes de réseau.
Escaliers intérieurs Network Intent
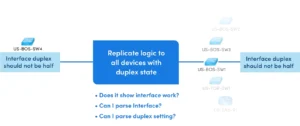
Vous pouvez résoudre des milliers de problèmes similaires avec un seul effort de diagnostic ou de correction. Capturez une seule intention et répliquez-la automatiquement sur un millier d'appareils « similaires » dans n'importe quel réseau hybride multifournisseur.
NetBrain's Intent-Based Automation valide de manière proactive que votre réseau hybride fait le travail attendu de lui et de toutes ses applications, en détectant les problèmes avant qu'ils n'affectent l'entreprise et en effectuant une analyse immédiate des causes profondes pour permettre une résolution plus rapide des incidents.
Si une intention de départ correspond à une variable critique, elle peut être associée à cet appareil. Le NetBrain le moteur de décodage dans le backend essaie l'intention sur chaque appareil pour en trouver un pour le répliquer à l'aide de la logique de diagnostic associée. À partir de n'importe quelle instance d'un chemin ou d'une panne, générez une intention pour capturer les connaissances et la conception. Créez une intention pour un site et reproduisez-la sur n'importe quel site. Élaborez un diagnostic pour une zone et répliquez-le dans toutes les zones.
Façons de reproduire l'intention :
- LENTE – network intent modèle
- CIN – network intent grappe
Network Intent Template (NIT) vous permet de créer un modèle d'intention à partir d'un Network Intent. Chaque intention est également un modèle. Le modèle d'intention clone le Network Intent pour appliquer la logique à d'autres appareils pour le contrôle de réplication programmable. Un utilisateur peut définir NIT pour n'importe quel NI avec le diagnostic d'appareil unique.
Network Intent Le cluster (NIC) est la réplication pour device groups d'une conception de réseau à une conception de réseau similaire. Le NIC est conçu pour étendre la logique d'un NI (appelé un NI de graine) d'un ou d'un ensemble de dispositifs (par exemple, des paires) à l'ensemble du réseau. Par exemple, créez un NI pour surveiller si le basculement se produit entre une paire de périphériques HRSP causant le problème de performances tel que l'application lente). Ensuite, utilisez NIC pour répliquer la logique sur toutes les paires HRSP du réseau sans aucun codage.
NetBrain Plate-forme NextGen
Le réseau est une hiérarchie d'actifs critiques. NetBrainLa plate-forme NextGen de vous permet d'assembler l'automatisation dans une méthode modulaire, réutilisable et sans code. Réutilisez les automatisations de l'ensemble de la pile réseau (n'importe quel fournisseur) - pour n'importe quel problème. Plusieurs problèmes peuvent réutiliser le même diagnostic et les mêmes fonctions qui sont stockés dans un système de base de données appelé table de données d'automatisation qui mappe les actifs du réseau aux automatisations ou intentions. Ajoutez facilement de nouvelles automatisations à utiliser instantanément par tous les incidents.
Une plate-forme de modules qui est :
- Réutilisable
- Modulaire
- Evolutif
- Facile à entretenir
NetBrain L'automatisation sans code de NextGen valide de manière proactive que votre réseau hybride fait le travail attendu de lui et de toutes ses applications, en détectant les problèmes avant qu'ils n'affectent l'entreprise et en effectuant une analyse immédiate des causes profondes pour permettre une résolution plus rapide des incidents.
Intent-Based Automation (IBA) Centre
La Intent-Based Automation Center est la console centrale permettant d'exploiter la bibliothèque d'intentions d'automatisation. Il contient également des intentions prédéfinies prêtes à l'emploi qui répondent aux scénarios les plus courants, ainsi que pour des vérifications proactives de la conformité, de la sécurité et des performances des applications au niveau de la conception. Vous pouvez publier des intentions sur le centre IBA pour une utilisation et une gestion automatisées, y compris pour l'intention automatique.
Grâce à des mécanismes sans code intégrés à la plate-forme, vos propres experts en la matière peuvent créer la situation supplémentaire et les routines d'automatisation spécifiques au site sans aucun codage et les ajouter à la bibliothèque d'automatisation. Une fois les intentions publiées sur le centre IBA, tout ingénieur réseau ou opérateur peut utiliser les routines d'automatisation pour résoudre rapidement et avec précision les problèmes lorsqu'ils se reproduisent sans code.
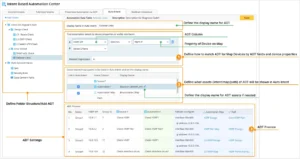
La NetBrain IBA Center est exploité sur l'ensemble de la plateforme. Couplé à un système ITSM/ITOM, NetBrain L'automatisation déclenchée NextGen s'appuiera sur le centre IBA pour mettre en œuvre l'ensemble de diagnostics le plus utile en réponse à des événements spécifiques.
Affichage des données d'intention - Utilisation de cartes et de données pour dépanner visuellement
Intent Data View offre la possibilité de visualiser les intentions sur n'importe quelle carte, y compris la conception du réseau et l'état de l'intention (rouge ou vert). La vue des données d'intention est conçue pour afficher les données de diagnostic et les résultats sur une carte d'intention ou sur n'importe quelle carte, afin que les utilisateurs puissent visualiser la conception du réseau ou surveiller l'état du réseau sur la carte.
Automatisation déclenchée
NetBrain Next-Gen automatise chaque aspect du flux de travail des incidents, de la création du ticket au diagnostic en passant par la notification. Network Intents peuvent servir d'encapsuleurs pour appeler des intents et des ADT.

Diagnostic de suivi
Le triplet d'intention permet une échelle massive de NI. Il imbrique des NI pour effectuer des diagnostics complexes sur le réseau.
1st Intention
Network Intent utilisés comme « conteneurs » pour appeler des diagnostics de suivi tels que les ADT.
- Généralement basés sur le type d'automatisation, ils appellent :
- Dépannage
- Prévention
- Impact sur les applications
- Sécurité
- Modifier
- Cartographie
2nd Intention
Une intention (intention d'accueil) peut s'appeler le modèle d'intention de suivi, dans lequel la même logique sera appliquée aux appareils en aval calculés à partir de l'intention d'accueil. Cette technologie appelée Follow-up Self calcule et cartographie les appareils voisins ou de chemin et répète le même diagnostic et exécute la même intention sur chaque saut de ses voisins et voisins de voisins.
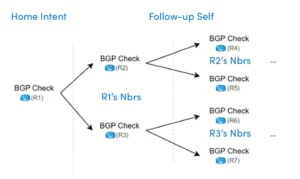
3rd Intention
Il s'agit du diagnostic appelé depuis l'ADT (où) à l'aide des balises d'automatisation (A-tag) (pour définir quelle automatisation).
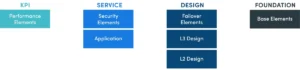
Cadre d'automatisation déclenchée
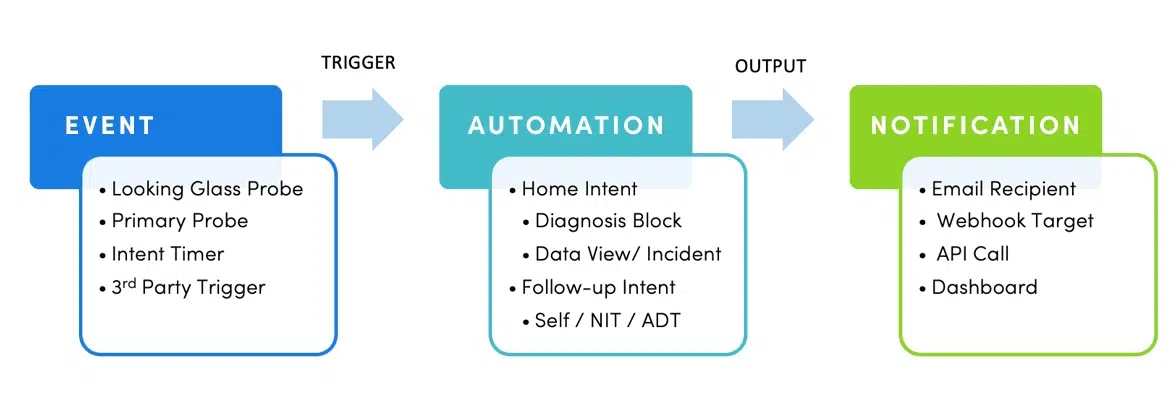
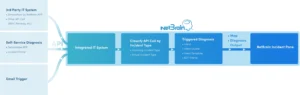
Les problèmes de réseau sont souvent organisés par un système de tickets sous la forme d'incidents. Dans le monde réel, 95 % des problèmes de réseau sont répétitifs dans la nature - un problème identique ou similaire se produit encore et encore mais est diagnostiqué de la même manière à chaque fois sans automatisation. NetBrain fournit Triggered Automation Framework (TAF) dans NetBrain pour combler cette lacune.
Triggered Automation Framework (TAF) fournit un diagnostic puissant déclenché par événement en exécutant Network Intent automatiquement pour les tickets entrants. Il existe deux manières de déclencher le diagnostic :
- un ticket externe du système tiers (un appel API de machine à machine)
- un appel libre-service de Chatbot, e-mails, application ServiceNow et Incident Portal (un appel API de l'homme à la machine).
Pour les deux types de déclencheurs, TAF les associe à une intention appropriée basée sur des critères prédéfinis pour effectuer un diagnostic déclenché. Les résultats sont affichés dans le volet Incident.
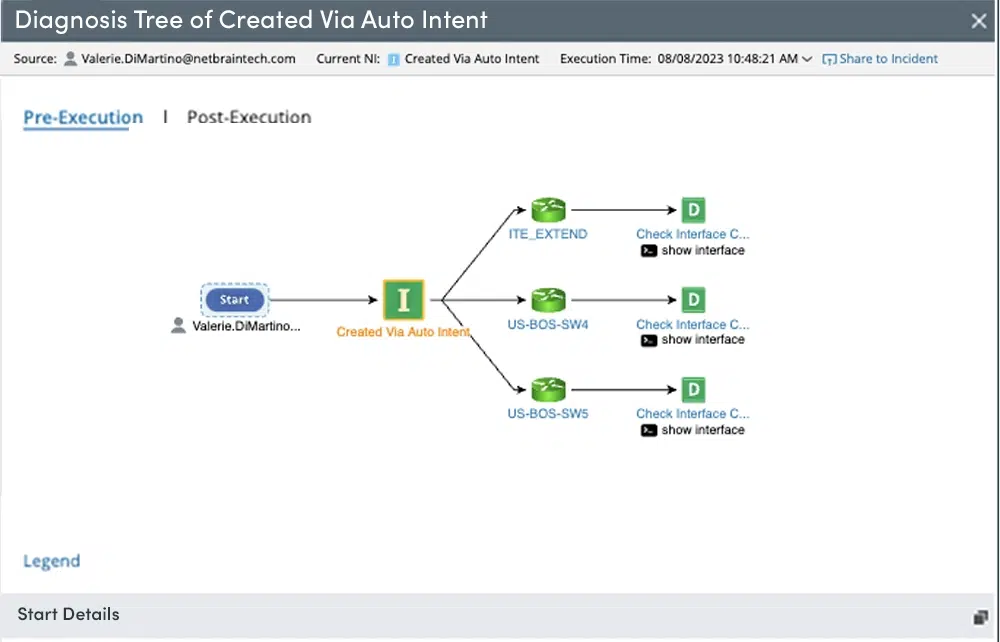
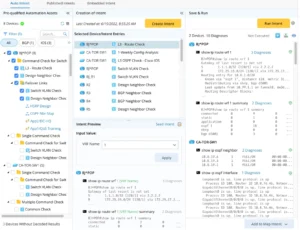
Arbre de diagnostic
Les humains ont besoin d'arbres de décision, mais il est très lent de les créer. NetBrain minimise le nombre d'actions que vous devez effectuer et en crée instantanément une entièrement interactive. La machine le crée rapidement en parallèle de votre travail, il est donc plus efficace et vous pouvez même le pré-programmer.
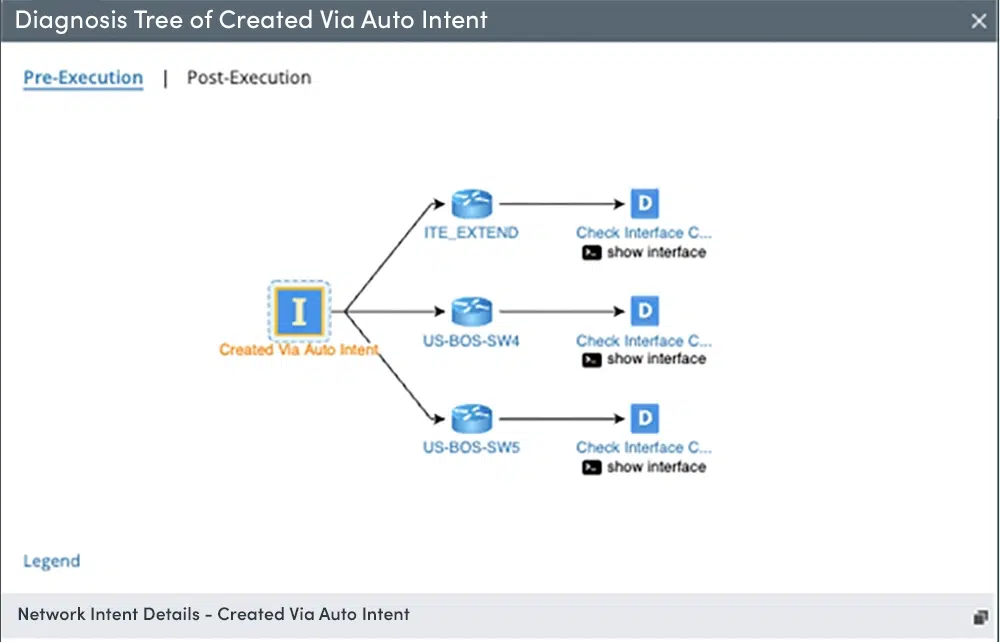
Double-cliquez sur n'importe quel appareil pour voir les détails et la CLI. Double-cliquez sur le diagnostic et voyez ce qui a été regardé et comparez et décochez modifié et inchangé pour une meilleure facilité d'utilisation.
Arbre de diagnostic (pré-exécution) : reflète la logique de diagnostic et la conception du dépannage.
Arbre de diagnostic post-exécution : affiche l'état d'exécution du diagnostic de suivi en fonction de l'arbre de diagnostic conçu (pré-exécution). Après l'exécution d'un NI, vous pouvez afficher son arbre de diagnostic (post-exécution). Chaque résultat d'exécution à un moment différent a son propre arbre de diagnostic indépendant (post-exécution).
Intégration du diagnostic déclenché avec les systèmes ITSM
Intégrer NetBrain Next-Gen avec des systèmes ITSM tels que ServiceNow, Jira ou BMC Remedy permettant aux prochains tickets d'être diagnostiqués par le moteur d'automatisation.
Intégration entre NetBrain NextGen et le système ITSM pourraient être réalisés selon l'une des deux méthodes :
- Grâce à une application d'intégration spécialement conçue, telle que ServiceNow App, Splunk App.
- Via une bibliothèque RestAPI, telle que l'intégration BMC.
Après l'intégration du système de tickets, un nouveau ticket dont les champs correspondent aux règles de déclenchement enverra un appel API à NetBrain avec une charge utile prédéfinie ; NetBrain lancera à son tour les actions suivantes :
- Les appels d'API entrants seront classés dans un "type d'incident" prédéfini
- Les incidents entrants seront fusionnés dans un NetBrain incident ou un incident nouvellement créé.
- A dynamic map est créé ou ouvert pour l'incident
- Diagnostic correspondant exécuté
Dépannage basé sur le chemin pour les performances des applications
- Calculez et comparez tous les chemins d'accès aux applications par rapport aux chemins de référence du site au cloud
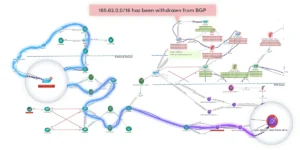
Dépannage basé sur le chemin du flux de trafic d'application avec intention
- Diagnostiquer et dépanner visuellement les chemins d'application via Path Intent
- L'intention de chemin permet aux ingénieurs de créer des vérifications spécifiques au chemin pour chaque appareil et d'enregistrer ces vérifications avec le chemin et la carte
- Une vérification peut inclure la connectivité, les performances et la sécurité
- L'intention de chemin permet aux ingénieurs de créer des vérifications spécifiques au chemin pour chaque appareil et d'enregistrer ces vérifications avec le chemin et la carte
- Cloner des intentions pour des milliers de chemins
- Utiliser l'intention automatique pour créer une intention spécifique à l'appareil pour l'intention de chemin (Un appareil à la fois)
- Utiliser le modèle d'intention spécifique au chemin pour répliquer l'intention (Un chemin à la fois)
- Utilisez ADT et le modèle d'intention spécifique au chemin pour répliquer l'intention (Plusieurs chemins à la fois)
- Surveillez en continu des milliers de chemins pour le diagnostic et la prévention des incidents avec Calculate Path et Execute Path Intent
- Afficher les résultats dans les lots de chemins
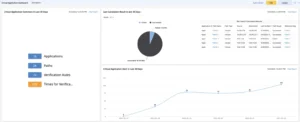
- Afficher la vérification du chemin et la surveillance du chemin pour les performances des applications dans un tableau de bord
Avertir les utilisateurs ou les systèmes tiers avec des alertes
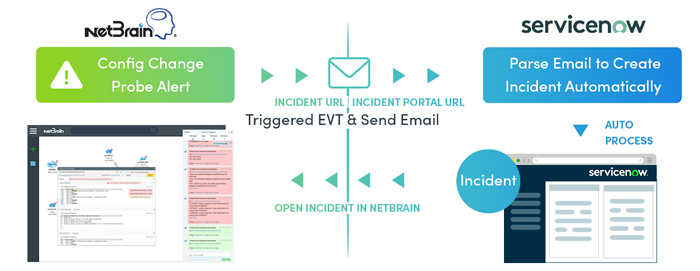 Générer intent-based automation alertes et partagez-les avec d'autres utilisateurs par e-mail. Vous pouvez vous abonner à certains types d'alertes et les diffuser vers votre système de gestion des alertes ou des incidents pour traitement.
Générer intent-based automation alertes et partagez-les avec d'autres utilisateurs par e-mail. Vous pouvez vous abonner à certains types d'alertes et les diffuser vers votre système de gestion des alertes ou des incidents pour traitement.
Les alertes par e-mail peuvent être utilisées pour créer des tickets pour des systèmes tiers (par exemple, ServiceNow). NetBrain crée des tickets internes avec les résultats du diagnostic NIT. Affichez le ticket créé dans le système de ticket et utilisez le lien pour ouvrir l'incident dans NetBrain.
Webhooks aux systèmes ITSM
Les webhooks sont des API qui permettent à deux systèmes de communiquer entre eux. Il s'agit d'une API plus simple que vous pouvez appeler pour informer un récepteur d'une charge utile dynamique (par exemple, un identifiant de ticket pour fermer un ticket). NetBrain envoie automatiquement un e-mail contenant les détails de l'exécution de l'intention au système de billetterie. Cela permet de créer, de mettre à jour et même de fermer des tickets en fonction des résultats du Network Intent.
Automatisation en libre-service
Les problèmes de performances du réseau et d'autres incidents de niveau de service peuvent être portés à l'attention de diverses équipes de support en dehors des canaux NetOps typiques, permettant ainsi à toute équipe de support d'interagir avec NetBrainL'intelligence est impérative. Les utilisateurs peuvent déclencher l'automatisation du diagnostic des problèmes directement à partir des solutions ITSM (telles que ServiceNow), via Microsoft Teams, ou même avec rien de plus qu'un e-mail pour réduire rapidement le temps de collecte des données, MTTR, et d'autres escalades.
L'automatisation en libre-service renforce tous les niveaux du processus d'assistance. Grâce aux options de libre-service, tout personnel d'assistance, et pas seulement les ingénieurs réseau, peut participer au diagnostic de haut niveau du réseau et résoudre les problèmes bien avant que les ingénieurs réseau ne soient affectés. Les ingénieurs du système, de la sécurité, des applications et même du service d'assistance de niveau 1 peuvent accéder à l'automatisation du réseau pour diagnostiquer rapidement les problèmes en temps réel, pendant que le problème est observé. Les options de libre-service peuvent être personnalisées par rôle et les résultats peuvent être fournis à partir de la console de gestion ou du incident portal permettant l'accès à tous les niveaux du chemin d'escalade.
Libre-service de l'ITSM
L'automatisation en libre-service réside dans les systèmes de collaboration basés sur les incidents, y compris NetBrain's Incident Portal et le volet des incidents ou des outils ITSM intégrés comme ServiceNow. Tout comme les cas où l'ITSM se déclenche NetBrain automatiquement, le libre-service permet de résoudre le problème en une fraction du temps nécessaire à une réponse NetOps typique.
L'intégration avec le système ITSM sert deux objectifs liés aux ressources :
- Pour les tickets non structurés créés manuellement, lorsque les règles de déclenchement automatisé ne sont pas activées, les utilisateurs peuvent lancer manuellement un diagnostic avec un effet similaire au déclencheur automatisé.
- Pour les ingénieurs réseau expérimentés résolvant un problème informatique pour partager des fonctions de diagnostic automatisées avec des ingénieurs réseau juniors ou des ingénieurs non réseau sans se connecter au NetBrain système.

Automatisation interactive
Automatisation interactive
L'automatisation interactive, c'est quand NetBrain intelligence enregistre les étapes de diagnostic des ingénieurs réseau pour créer une automatisation pour leur propre usage, leur permettant d'être plus productifs en obtenant des données de plusieurs appareils, en recherchant des changements en exécutant une comparaison automatiquement, et en surveillant et en recevant des alertes pour les changements de seuil. Il offre des garde-fous permettant à tout opérateur ou ingénieur de prendre des décisions éclairées en fonction de l'état du réseau en temps réel.
À mesure que les réseaux deviennent plus grands et plus complexes, la documentation automatisée devient plus importante, d'autant plus que les réseaux intègrent des technologies telles que SDN, SD-WAN et public cloud. NetBrain fournit non seulement une visibilité de bout en bout sur les réseaux hybrides, mais également la possibilité d'explorer chaque segment et d'isoler les problèmes de réseau sur un Dynamic Map pouvant être mis à jour en temps réel. Cela accélère considérablement l'identification et la résolution des problèmes. Et lorsque de nouveaux appareils sont ajoutés ou supprimés du réseau, la documentation est rapidement reflétée dans une carte du réseau mise à jour qui est exportable sous forme de diagrammes vers Microsoft Visio et Word.
Avec NetBrain, les professionnels NetOps tirent parti de leur propre expertise pour enregistrer automatiquement des procédures standardisées dans un runbook à mesure qu'ils détectent, diagnostiquent et corrigent les problèmes. Les étapes qu'ils utilisent pour diagnostiquer les problèmes, y compris l'utilisation de commandes CLI sur plusieurs appareils, sont automatisées dans Runbooks.
Intention automatique
L'intention automatique permet aux utilisateurs de créer des intentions, de les répliquer sur d'autres appareils et de les exécuter pour des appareils sur une carte.
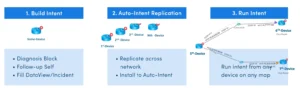
Géré dans le centre IBA, activez les modèles d'intention pour l'intention automatique, afin que les utilisateurs finaux puissent répliquer les modèles d'intention et personnaliser les variables de macro si nécessaire pour créer l'intention appropriée pour les appareils cartographiques.
Dans l'intention automatique, saisissez une variable de macro et une intention de départ. Pour créer une carte multidiffusion, placez l'adresse multidiffusion en tant que macro-variable. Pour faire un ping, mettez la cible en tant que variable. La plate-forme utilise une logique programmable pour appeler n'importe quelle intention à la volée avec une automatisation déclenchée.
Automatisation collaborative
L'automatisation collaborative est l'endroit où les ingénieurs et les opérateurs tirent parti des connaissances de leurs pairs avec un logiciel qui capture les connaissances des experts en la matière pour créer des unités d'automatisation exécutables que d'autres peuvent ensuite ajouter à leurs propres diagnostics. L'expertise est disponible même lorsque l'expert ne l'est pas. NetBrain aide lors du dépannage d'un problème, de l'évaluation de l'état du réseau ou de la compréhension d'une technologie complexe. Il permet au personnel NetOps de rassembler, d'analyser et de visualiser des milliers de KPI en quelques secondes. Il peut être associé à nos capacités de collaboration pour permettre à plusieurs équipes opérationnelles (SecOps, DevOps, NetOps, ServerOps) pour résoudre de manière interactive les problèmes qui couvrent plusieurs domaines technologiques sans avoir besoin de transferts chronophages qui entraînent des retards. Tout le monde peut se connecter en même temps et interagir et apporter des mises à jour et des corrections au modèle via une console d'analyse partagée.
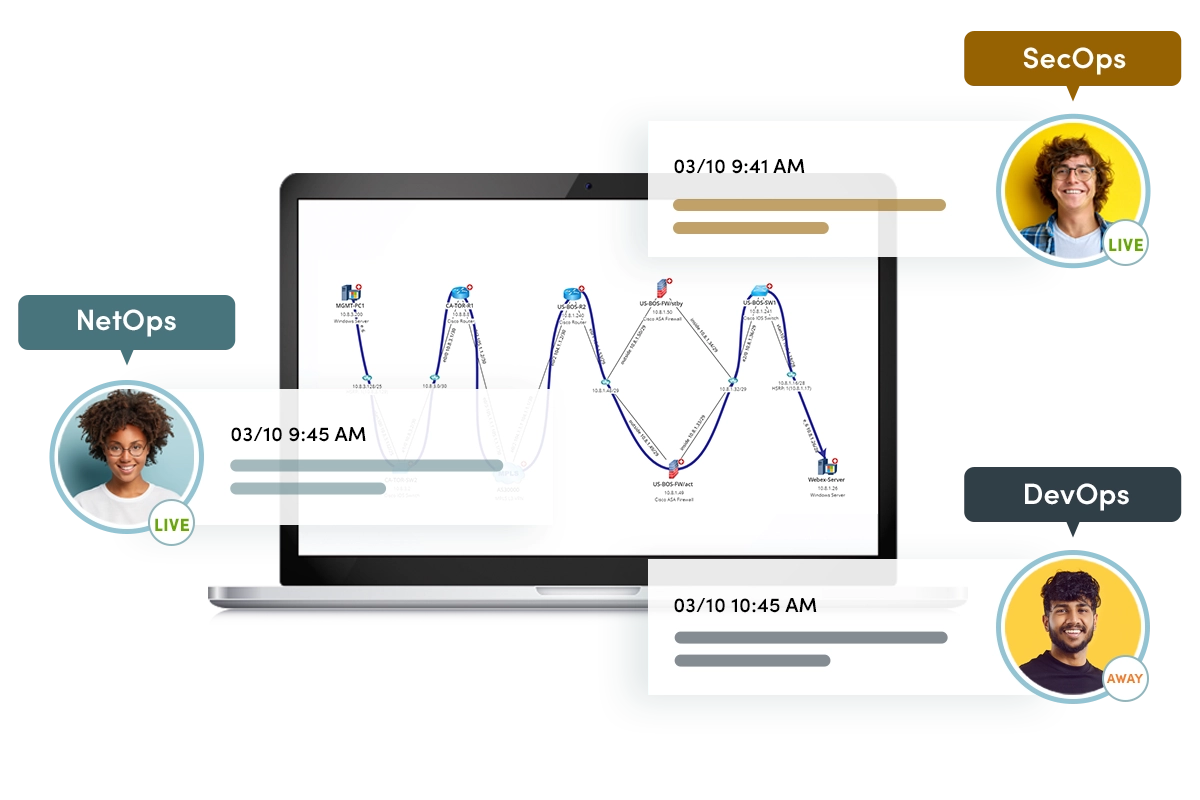
NetBrain capture et codifie les connaissances des PME en utilisant Runbooks, vues de données et Network Intents. La capture automatique de ces informations permet aux ingénieurs expérimentés de codifier et de partager leurs connaissances avec le personnel subalterne, transférant efficacement les connaissances vers la gauche, des utilisateurs expérimentés aux membres de l'équipe moins expérimentés. La prochaine fois que le problème se produit, le runbook est exécuté par des intervenants sans connaissances ni formation approfondies. Même les problèmes de réseau complexes ne doivent plus être traités exclusivement par des experts. Vous utilisez essentiellement les connaissances de ces travailleurs hautement qualifiés de niveau 3 lorsqu'ils ne sont pas disponibles (en raison de l'emplacement ou de la disponibilité).
Incident Portal
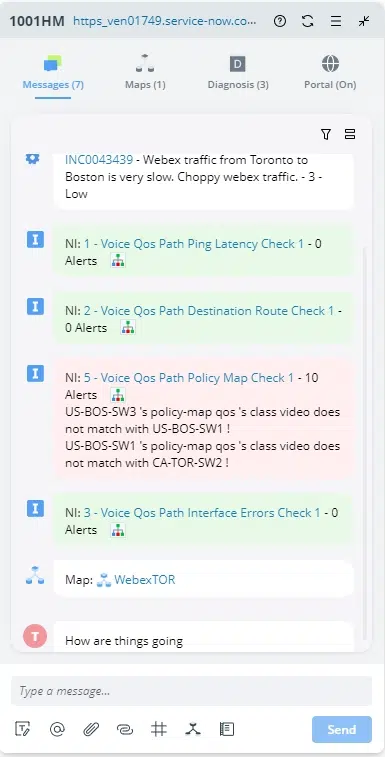
NetBrain's Incident Portal permet la collaboration entre plusieurs utilisateurs travaillant sur la même tâche de dépannage. Un incident représente un ticket dans NetBrain pour suivre un problème de réseau ou un changement de réseau. Les utilisateurs finaux peuvent organiser et partager des cartes, des appareils, des informations individuelles et des résultats ciblant une tâche de dépannage spécifique et collaborer avec davantage de collègues pour résoudre les problèmes en réduisant MTTR.
Par ailleurs, Incident Portal propose une page portail indépendante pour chaque incident. Utilisateurs externes sans NetBrain Les licences de poste de travail peuvent accéder à un portail pour rejoindre la session de collaboration en affichant des cartes et en publiant des messages, etc.
La Function Portal permet aux ingénieurs réseau de collaborer avec leurs collègues NetOps et avec les membres d'autres équipes opérationnelles qui ne sont pas initialement impliqués dans un ticket de service.
Il s'agit de l'une des principales approches pour atteindre l'objectif de réduction des frais généraux liés aux tickets de service et d'amélioration de la productivité de l'équipe et MTTR. Avec Function Portal, les utilisateurs de plusieurs équipes (ingénieurs informatiques, ingénieurs en sécurité, etc.) travaillent ensemble pour résoudre des problèmes complexes qui nécessiteraient autrement des transferts et attendent que des ressources soient disponibles.
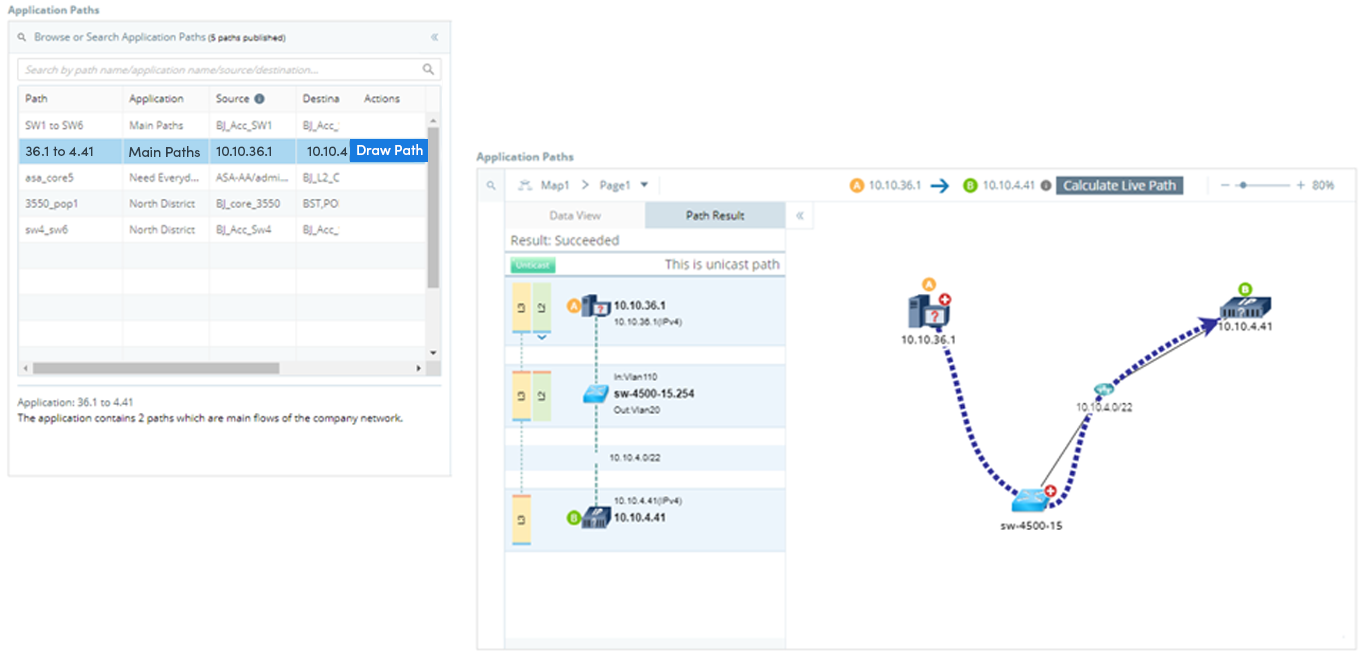
Runbooks
- Runbooks documenter les procédures de documentation, d'évaluation et de dépannage à l'aide d'outils CLI familiers
- Runbook des modèles peuvent être utilisés pour standardiser les processus
RunbookLes s sont un ensemble d'étapes opérationnelles visuelles que les ingénieurs créent en capturant leurs flux de travail étape par étape avec des intentions pour permettre l'automatisation du diagnostic des problèmes futurs, de la collecte de données réseau et des tâches de dépannage. Runbooks fournissent un moyen visuel de codifier le processus de dépannage du réseau dans un workflow exécutable, réutilisable et documentable. Les experts en la matière peuvent numériser leurs connaissances dans un runbook modèle pour capturer les meilleures pratiques et les mesures correctives que d'autres opérateurs peuvent utiliser. Une fois que Runbooks sont exécutés, les résultats peuvent être partagés avec n'importe qui dans l'organisation, facilitant la collaboration et permettant aux ingénieurs de niveau supérieur de coder leurs connaissances avancées dans des unités d'automatisation reproductibles.
Runbooks contiennent des actions qui peuvent effectuer automatiquement des tâches réseau complexes, fournissant à l'utilisateur :
- Automatisation de la ligne de commande
- Collaboration améliorée sur les incidents
- Partage simplifié des connaissances
Runbooks peuvent tirer parti des ensembles de données d'outils tiers, permettant aux utilisateurs de visualiser les informations de tous leurs outils existants dans son Dynamic Map.
Runbooks En un coup d'œil
• Automatiser les opérations réseau à grande échelle
• Collaborez sans effort avec plusieurs ingénieurs utilisant le même Dynamic Map
• Partagez et enregistrez des informations sur le réseau concernant les bases d'un dépannage futur
SmartCLI
SmartCLI intègre un outil familier (CLI via telnet/SSH) dans NetBrain. Il fournit un dépannage interactif avec des outils CLI traditionnels tels que les commandes show, ping et traceroute.
Automatisation préventive
Présentation du cadre d'automatisation préventive (PAF)
NetBrainL'automatisation préventive de résout les problèmes d'erreur humaine, les problèmes bien connus et les appareils non conformes sont considérés comme les principales causes profondes de l'impact et des temps d'arrêt du réseau.
Network Intents vérifie en permanence et automatiquement l'état opérationnel du réseau pour résoudre les problèmes avant qu'ils ne provoquent des pannes.
Le diagnostic automatisé et la vérification des règles sont déclenchés par des alertes précoces provenant d'un ensemble de sondes logiques. Ensemble, le PAF est différent des systèmes de surveillance traditionnels, en ce que :
- PAF est conçu pour appliquer automatiquement les vérifications de conception et de règles de sécurité, sans surveiller les erreurs système
- Le PAF doit être personnalisé en fonction de la conception du réseau, et non d'une taille unique pour tous.
- PAF peut servir de nouvelle génération compliance check solution - c'est un 24X7 compliance check.
Détection d'alerte précoce via des événements
Événements préventifs
- Looking Glass Probe - Concept similaire à BGP Looking Glass. Localisez stratégiquement votre appareil Looking Glass pour superviser votre infrastructure (zone de routage OSPF, routage BGP, etc.). Réduisez la consommation de ressources système pour les vérifications à haute fréquence.
- Sonde principale - Sonde régulière qui vérifie les événements de périphérique, tels que les valeurs de variables ne correspondant pas à la ligne de base, les modifications de configuration, les événements d'interface, etc.
- Intent Timer - Sonde basée sur le temps. Exécutez l'automatisation en fonction de la fréquence.
- Sonde externe – Événement système tiers (SolarWinds, SNOW, etc.).
Sondes
Le PAF déclenche des sondes virtuelles qui exécutent des NI pour identifier les anomalies du réseau et vous alerter de la première occurrence et des problèmes transitoires. Celles-ci consistent en :
Sondes internes
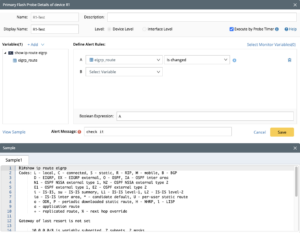
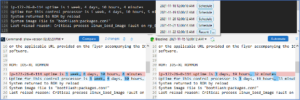
- Sondes primaires : Utilisation des sondes primaires Network Intents pour vérifier les anomalies (par exemple, les changements de configuration de l'appareil et les erreurs d'interface) et interroger à n'importe quelle fréquence souhaitée. NetBrain prend en charge deux types de sondes principales :
- Alert-based Probe : déclenchée par une anomalie générée par l'appareil (informations relatives à la configuration).
- Sonde basée sur le temporisateur : déclenchée par un temporisateur d'intervalle et peut être utilisée pour les tâches CLI et NI planifiées.
- Sondes secondaires : Les sondes secondaires ne sont déclenchées que par les sondes primaires en raison d'une alerte lorsque des investigations diagnostiques plus détaillées sont nécessaires.
Sondes externes sont utilisés pour l'intégration avec d'autres systèmes de surveillance. Une fois l'intégration terminée, l'alerte déclenchée par des systèmes tiers peut générer implicitement des sondes externes.
Quand NetBrain les sondes détectent les alertes, elles envoient automatiquement des notifications aux ingénieurs.
Il peut être mis à l'échelle horizontalement comme :
- Analyse distribuée sur les serveurs frontaux : la récupération des données et le calcul de la sonde flash sont exécutés localement sur les serveurs frontaux, ce qui peut être étendu à un très grand réseau avec des serveurs frontaux distribués.
- Analyse hiérarchique de la sonde primaire -> sonde secondaire-> Network Intent: la conception hiérarchique permet au système d'utiliser efficacement les ressources pour exécuter Network Intent automatisation sur l'ensemble du réseau.
Minuteur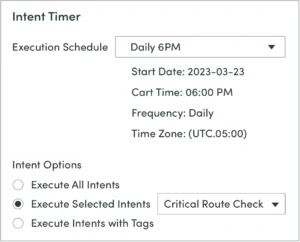
Un minuteur d'intention peut exécuter des intentions ADT à certains intervalles définis par rapport à des lignes de base établies à l'appui de la conformité et des audits du réseau. À tout intervalle souhaité, avant que la détérioration des conditions ne génère des alertes, il teste network intents par rapport aux lignes de base et fournit un avertissement avancé.
Automatisation préventive du centre IBA via ADT - Intent Timer
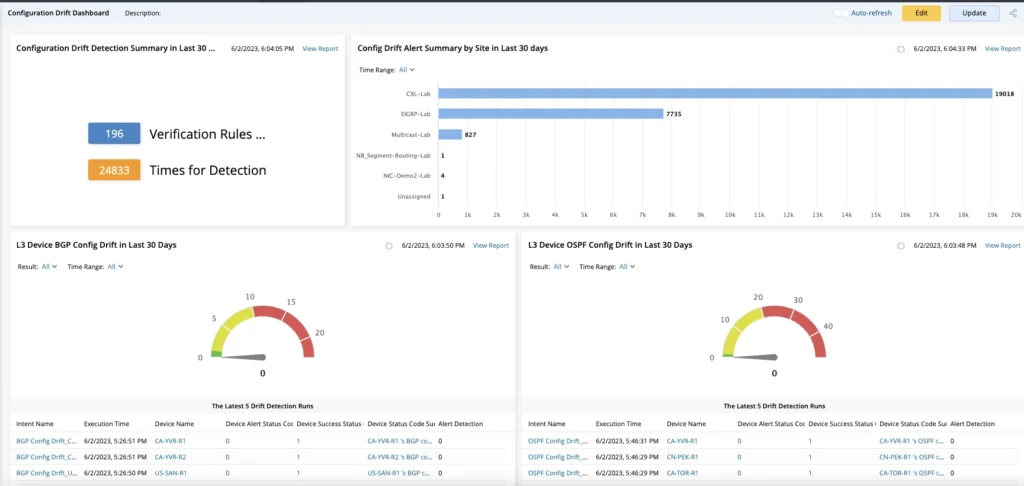
Tableau de bord de rapport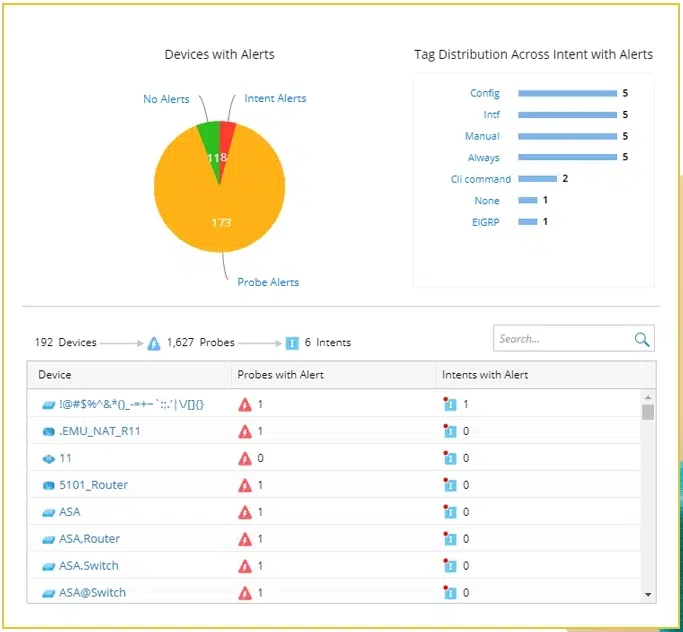
NetBrain affiche les données des sondes dans un tableau de bord d'automatisation préventive facile à utiliser indiquant le nombre d'alertes de périphérique par sonde et par intention.
Automatisez les contrôles de conformité et de sécurité
L'automatisation préventive vous permet de définir les règles de conformité et de contrôle de sécurité au sein Network Intents et étendre le contrôle à l'ensemble du réseau via Network Intent Cluster, que le système exécute automatiquement.