 by Kelly Yue Jan 3, 2022
by Kelly Yue Jan 3, 2022
Een van de meest gebruikte tools in netwerk het oplossen van problemen is misschien wel de traceroute (en zijn kleine broertje ping). Hoe nuttig deze tool ook is, er zijn een paar kritieke uitdagingen bij het gebruik van traceroute om de veel complexere problemen van vandaag aan te pakken. Vergeet niet dat traceroute eind jaren tachtig is gemaakt, toen netwerken veel eenvoudiger waren; alles was fysiek, point-to-point was een rage, er waren minder protocollen om mee om te gaan en schakelaars werden gewoonlijk bridges genoemd, met LAN-naar-WAN-routers die van het ene gebouw naar het andere gingen. (Vergeet niet dat dit een half dozijn jaar was voordat internet bestond)! En wie herinnert zich 'Leased T1980 Lines' nog? De goede oude tijd zeg maar.
Dus hoe houden antieke tools zoals deze stand in de huidige wereld van softwaregedefinieerd en gevirtualiseerd alles? Er moet toch een modernere manier zijn om problemen met de netwerken van vandaag op te lossen? Ja, er is dus blijf lezen ...
Laten we, om te beginnen, wat meer begrijpen over wat een traceroute-opdracht is.
Wat is een Traceroute-commando?
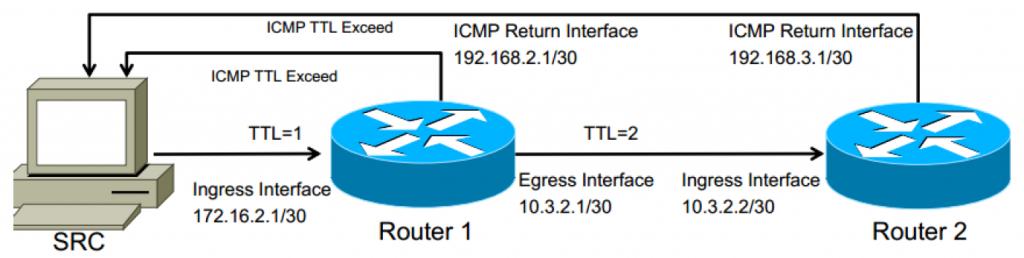
De bronmachine (SRC) stuurt doorgaans 3 testpakketten naar het bestemmings-IP-adres, beginnend met Time to Live (TTL) ingesteld op 1. Ten onrechte wordt aangenomen dat het type testpakket altijd ICMP is, terwijl het in werkelijkheid afhangt van het apparaat afkomstig van de traceroute. Windows-besturingssystemen zullen vaak ICMP gebruiken, terwijl Unix- en routeringsapparaten vaker UDP-berichten naar kortstondige poorten zullen gebruiken (poorten groter dan 1024 die geen bekende services zijn zoals DNS, SMTP, WEB, enz...)
Naarmate het sondepakket wordt ontvangen bij elk laag 3-apparaat, wordt de TTL verlaagd. Wanneer TTL 0 bereikt, verzendt het ontvangende apparaat een ICMP-bericht "TTL Expired" vanaf de interface die dat pakket heeft ontvangen. Zo kent traceroute elke hop onderweg.
In de onderstaande afbeelding zouden 172.16.2.1 en 10.3.2.2 de adressen zijn die worden geretourneerd in de traceroute-resultaten.
Uitdagingen met Traceroute-opdrachten voor de netwerken van vandaag:
# 1: Asymmetrische paden zijn niet gemakkelijk te zien. Standaard wordt alleen A-naar-B gerapporteerd. B-naar-A vereist een andere traceroute vanaf het andere uiteinde om het pad te voltooien.
Asymmetrische routering is tegenwoordig gemeengoed in netwerken. Er zijn veel multi-path (ECMP)-protocollen met gelijke kosten en zelfs multi-path-routeringsprotocollen met ongelijke kosten in het spel, en afhankelijk van het hash-algoritme zal het verkeer waarschijnlijk in elke richting een ander pad nemen. Deze verschillende paden zijn erg moeilijk te detecteren met de uitvoering van een enkele traceroute-opdracht, en daarom erg moeilijk om precies te detecteren waar het vertragingsresultaat vandaan komt.
Zoals je hierboven kunt zien, springt de vertragingswaarde omhoog bij deze specifieke sprong, maar de vraag is "Waar is deze vertraging?" Is het op het voorwaartse pad of op het retourpad?
#2: Interfaces zijn niet bekend, alleen het IP-knooppunt van het apparaat. Er is geen extra detail.
Als we de traceroute hierboven nogmaals bekijken, is de enige verstrekte informatie een hostnaam/IP en een vertraagd resultaat. Als een gebruiker hop 6 zou onderzoeken, zou hij naar de router moeten telnet/ssh om te bepalen aan welke interface dit IP-adres was gekoppeld (laat zien dat IP-route 129.259.2.41 mijn favoriete manier was om dit te bepalen, maar je zou de IP-interface kunnen laten zien en pijp de output naar a parser… kort IP-interface tonen | in 129.150.2.41). Ten tweede, om de uitgaande (uitgaande) interface te bepalen, zou een tweede zoekopdracht moeten worden voltooid om deze informatie te bepalen (toon bijvoorbeeld IP-route 192.41.37.40)
# 3: Traceroute vertrouwt op ICMP-berichten die een langere vertraging kunnen melden dan daadwerkelijk wordt waargenomen door verkeer, aangezien ze worden verwerkt op het "langzame pad" van een apparaat versus het "snelle pad" dat wordt gebruikt om gegevens door te sturen die door de router gaan .
Slow-path kan het gemakkelijkst worden samengevat als wanneer de router de inhoud van het pakket moet verwerken. Vrijwel elk pakket dat bestemd is voor een apparaat wordt op deze manier behandeld. Nieuwere routers hebben interne mechanismen om prioriteit te geven aan welke pakketten ze verwerken (routeringsprotocolupdates vóór ICMP-berichten), maar dit maakt het probleem hier alleen maar groter. Zoals we eerder hebben besproken, gebruiken de meeste systemen een UDP-bericht, maar het genereren van het verlopen ICMP TTL-bericht heeft een lagere prioriteit en dan is het retourpad een ICMP-bericht, dus de vertragingsstatistieken in de resultaten zijn moeilijk accepteren als echte problemen.
TIP: Wanneer u een traceroute ziet die naar een bepaalde stap in het resultaat springt en alle volgende resultaten laag zijn, is dit een indicatie dat de "trage" router vertraging heeft in de verwerking. Als het pad verspringt en vervolgens elke volgende stap op het pad wordt opgehoogd, betekent dit meestal een vorm van wachtrijen vanwege congestie.
# 4: Traceroute-uitvoer is de statische tekst waarop niet gemakkelijk kan worden gereageerd.
Oké, dus nu kennen we het pad naar een specifieke bestemming, maar wat als ik dieper wil duiken in een of meer sprongen langs dat pad? Telnet/SSH-consolesessie vereist dat de gebruiker zich aanmeldt bij deze apparaten. Alleen het IP-adres van de interface wordt verstrekt in het traceroute-antwoord. Dit kan in veel netwerken een uitdaging vormen, aangezien gebruikers vanuit het oogpunt van het beveiligingsbeleid moeten telnet/ssh naar het IP-adres van het beheer. Telnet kan worden geblokkeerd op de specifieke interfaces die worden gerapporteerd in de traceroute, wat enige vorm van handmatige opzoeking vereist om de beheerinterface van een apparaat met dat interfaceadres te bepalen. Zonder DNS-resolutie is dit bijna onmogelijk. Als er een storing is, kan elke seconde tegen je worden geteld.
#5: Paden met gelijke kosten worden niet weergegeven (alleen het daadwerkelijk afgelegde pad wordt gerapporteerd).
Zoals eerder vermeld, zijn routes met meerdere paden met gelijke of ongelijke kosten tegenwoordig gebruikelijk in de meeste netwerken. Traceroute rapporteert alleen over het specifieke pad dat deel uitmaakte van de onderzoekende sondeberichten. Aangezien de meest gebruikelijke traceroute-implementaties 3 testpakketten met verschillende UDP-bestemmingspoorten verzenden, is het mogelijk dat in een ECMP-omgeving elke hop tot 3 verschillende IP-adressen rapporteert. Bijhouden welke respons deel uitmaakt van welk pad kan omslachtig worden.

# 6: Traceroute is Layer-3 (het rapporteert niet over Layer 2-hops)
Zoals we nu begrijpen, werkt traceroute aan het verlagen van de TTL-waarde in een IP-pakket en het genereren van TTL verlopen ICMP-berichten. TTL wordt alleen verlaagd op laag 3-apparaten, dus er is geen ingebouwde zichtbaarheid of de mogelijkheid om eenvoudig het laag-2-pad te bepalen dat uit het resultaat wordt gehaald. In Enterprise- en Data Center-omgevingen wordt er bijna altijd een vorm van Layer-2-toegangsschakelaar gebruikt om eindstations samen te voegen. In sommige ontwerpen is er ook een laag-2-distributielaag voordat een kernrouter wordt bereikt die daadwerkelijk de eerste laag-3-routeringsfunctie uitvoert die kan rapporteren aan een traceroute-verzoek. Als pakketverlies wordt weergegeven in de traceroute-uitvoer, kan dit te wijten zijn aan onjuiste hashing van een Layer 2-poortkanaal of Link Aggregation Group (LAG), spanning tree-probleem, duplexconfiguratie op een switch of een ander probleem dat alleen kan worden ontdekt door het inspecteren van de elementen van laag 2 langs het pad. Het vinden van deze informatie vereist:
- Bepalen van het MAC-adres van het bronapparaat op het laag 2-segment (controleren van de ARP-tabel op de router of op het bronapparaat,
- Documentatie controleren om te bepalen welke schakelaars in gebruik zijn
- Inloggen op elk mogelijk pad en MAC-tabellen controleren op het specifieke MAC-adres,
- Uitvoeren van opdrachten om prestaties en configuratie te controleren
- Bepalen van de trunks die weglopen van het actieve apparaat
- Inloggen op het volgende layer2-apparaat en het proces herhalen totdat de eerste router is bereikt.
Dit proces kan erg tijdrovend zijn, vooral als CDP/LLDP niet is ingeschakeld in het netwerk of als de documentatie verouderd is.
#7: Traceroute mist historische informatie
De resultaten die u ziet met een traceroute zijn de huidige status. Er is geen manier om te bepalen wat het pad was toen het verkeer succesvol was (gisteren bijvoorbeeld). Overweeg de traceroute hieronder, het zou goed zijn om te begrijpen wat hop 4 was voordat de dingen veranderden om het mogelijke probleem te helpen isoleren.
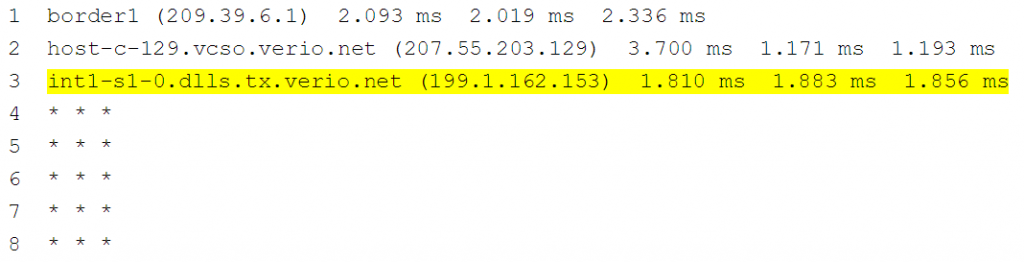
OPMERKING: Het is onze ervaring dat technici op basis van de uitvoer van het bovenstaande traceroute-commando aannemen dat hop 3 het probleem is. Dit is vaak niet het geval. De eerste controle die een gebruiker moet uitvoeren, is inloggen op het apparaat in hop 3 en controleren of het apparaat een routeringsvermelding naar de bestemming heeft. Als dat het geval is, is het probleemapparaat vaak de volgende hop in het routeringsitem. Om grondig te zijn, is het nuttig om de uitgaande interface naar de routing next-hop te controleren om de prestaties op interfaceniveau en de ACL-configuratie te verifiëren.
# 8: Traceroute heeft een cryptisch foutberichtensysteem.
Wanneer ik een traceroute-opdrachtprobleem tegenkom, krijg ik zo nu en dan een personage in de uitvoer dat me verbaast. De onderstaande tabel is afkomstig uit Cisco's implementatie van traceroute. Hoewel ze misschien rechttoe rechtaan lijken, vereist het begrijpen van wat er precies gebeurt bijna altijd extra vervolgonderzoek.
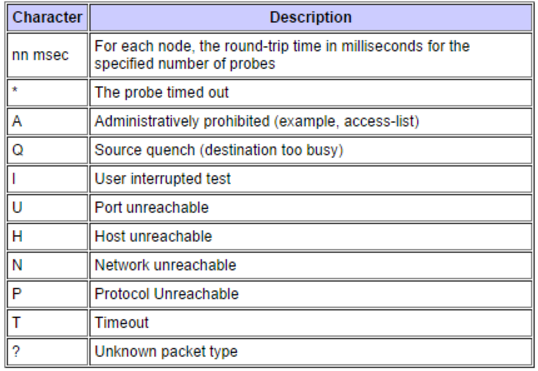
Stel dat ik bijvoorbeeld de letter A ontvang in het traceroute-antwoord, ik kan begrijpen dat er waarschijnlijk een toegangslijst is die de traceroute blokkeert, maar welke toegangslijst is het? Om dit te bepalen, moet ik inloggen op de router, bepalen welke interface het pakket is binnengekomen, de configuratie verifiëren en de toegangslijst onderzoeken wanneer ik het vind. Dit kan een langdurig proces zijn, en aangezien we ons altijd zorgen maken over de tijd als het gaat om het oplossen van problemen, zou het geweldig zijn om een betere manier te hebben om toegang te krijgen tot deze informatie.
OPMERKING: Onze ervaring is dat deze foutmeldingen alleen worden weergegeven op basis van de ingress-interface. Zodra een pakket goed is ontvangen en vervolgens doorgestuurd naar de volgende hop langs het pad als er een ACL op de uitgaande poort is, krijgt u eenvoudig een * * * voor de volgende hop, wat extra stappen betekent om ervoor te zorgen dat de uitgaande interface bekend is, en alle ACL's die ook op die poort zijn gevalideerd.
Wat is de moderne oplossing?
NetBrain bevat een schat aan automatiserings- en visualisatiefuncties die nodig zijn om moderne netwerken te onderhouden. Het begrijpt softwaregedefinieerd, gevirtualiseerd en zelfs de cloud. Het communiceert continu met elk apparaat op het end-to-end-netwerk en bouwt een realtime digitale tweeling van het netwerk. Deze digitale tweeling is een exacte replica van de details van elk apparaat. Het bevat de mogelijkheid om real-time netwerken te visualiseren en bevat een moderne vervanging voor traceroute, ook wel de A/B-padcalculator. Dit adresseert al deze uitdagingen door ingenieurs dynamisch te helpen een netwerk in kaart brengen pad tussen twee willekeurige punten in het netwerk en geeft extreme details van dat pad. Deze functie ondersteunt mapping door middel van moderne technologieën (bijv. SDN, SD-WAN, firewalls, load balancing), underlays en overlays, terwijl rekening wordt gehouden met geavanceerde protocollen (routing, toegangslijsten, PBR, VRF, NAT, enz.). En eenmaal geïmplementeerd, creëert dezelfde structuur die in realtime kan worden gevisualiseerd nu het perfecte platform voor automatisering zonder code van elke taak, groot en klein!
Drie praktijkvoorbeelden van de A/B-padcalculator
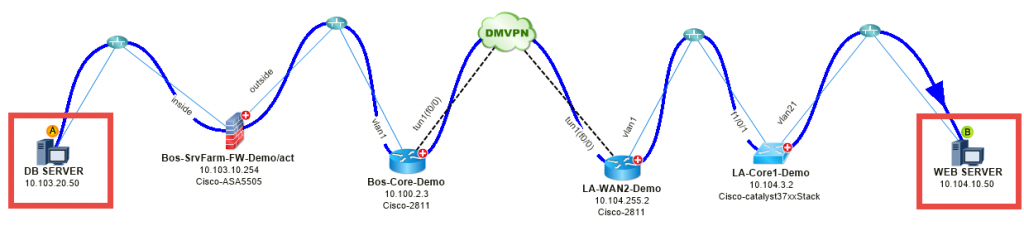
# 1: Wereldmap een trage applicatie – Een webapplicatie is traag tussen Boston en Los Angeles.
# 2: Kaart VoIP-verkeersstroom - Spraakverkeer is zenuwachtig tussen Boston en San Fran.
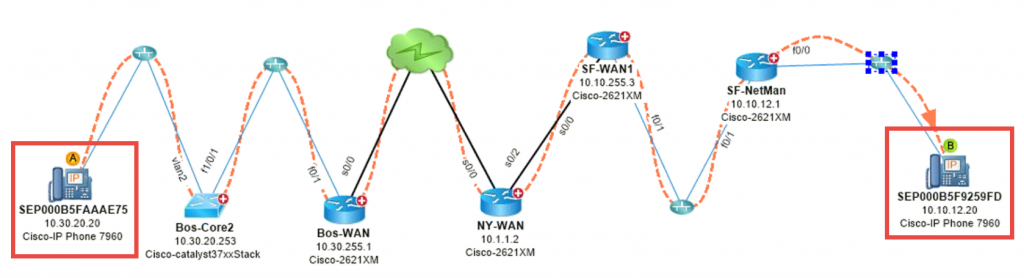
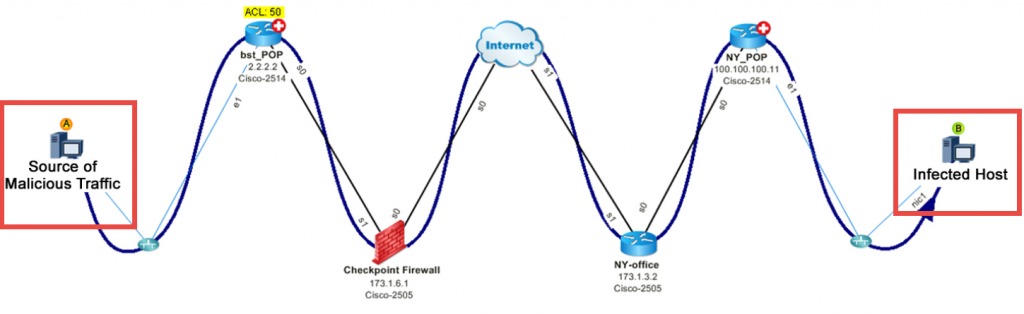
#3: DDoS-aanval in kaart brengen – Een kwaadwillende host injecteert DoS-verkeer op het netwerk. Waar komt het verkeer vandaan en wat is de impact? Door gebruik te maken van NetFlow om de beste spreker te identificeren, kunt u het pad in kaart brengen.
Service-leveringsgarantie
NetBrain's Applicatie zekerheid (AAM) brengt al uw hybride-cloudnetwerkpaden van uw applicatie in één overzicht in kaart, valideert continu end-to-end padprestaties ten opzichte van gezonde padbaselines en waarschuwt proactief de juiste teams zodat ze kunnen reageren op problemen voordat ze uw bedrijf verstoren. Het biedt uw teams de mogelijkheid om snel problemen op te lossen en applicatieprestaties te diagnosticeren op het niveau van de verkeersstroom.
Het is nu mogelijk om prestatieverlies van applicaties te voorkomen met NetBrain's no-code Intent-gebaseerde automatisering.
NetBrain AAM beschermt de gebruikerservaring door:
- Automatisch alle mogelijke applicatiepaden en hun apparaten in kaart brengen
- Gedrag definiëren voor alle applicatiepaden
- Live applicatiepaden baseren op "gouden" paden op kaarten
- De prestaties en geschiedenis van elk applicatiepad visualiseren in één dashboard
- Waarschuwt u voor mogelijke problemen zodra de prestaties van het toepassingspad verslechteren