 by Kelly Yue May 3, 2018
by Kelly Yue May 3, 2018
Da Unternehmen bei der Bereitstellung von Diensten und Produkten immer mehr auf das Netzwerk angewiesen sind, wird die Netzwerkautomatisierung immer wichtiger. Das Netzwerk macht keine freien Tage, und in meiner Zeit als Netzwerkingenieur habe ich das auf die harte Tour gelernt. Vor Jahren war ich bei einem Grillfest im Hinterhof, als mein alter Chef verzweifelt anrief: Ein kritischer Dateiserver wurde als wahrscheinliche Folge eines Ransomware-Angriffs gesperrt. Ich rannte sofort zur Konsole und trennte den Ort des Cyberangriffs vom Rest des globalen Netzwerks, um das Risiko zu mindern.
Nachdem sich die Lage beruhigt hatte, rief der CIO an und bat um ein Update: Haben wir Daten verloren? Wie ist die Ransomware eingedrungen? Wie hat es sich verbreitet? Haben wir gute Backups?
Der typische NOC-Workflow ist manuell und repetitiv. Mit einer Level-0-Netzwerkautomatisierung, a NetBrain Die Diagnose wird automatisch über die API-Integration gestartet, sobald Ihr Überwachungs- oder Event-Management-System ein Ereignis registriert.
Ich saß in unserem leeren Büro und setzte meine Detektivmütze auf, um in den unzähligen Scandaten vor mir nach Hinweisen zu suchen, was keine triviale Aufgabe war. Ich brütete über Dutzenden von Diagrammen, sprang in mehreren Tools von Bildschirm zu Bildschirm, loggte mich bei Dutzenden von Geräten ein und musste sogar einige meiner Kollegen anrufen, um mir ein vollständiges Bild des Netzwerks zu machen.
Wenn ich nur zum Zeitpunkt des Cyberangriffs die Informationen darüber hätte, was mit dem Netzwerk passiert ist. Wenn ich nur ein automatisiertes Skript hätte, das in dem Moment gestartet wird, in dem böswillige Aktivitäten erkannt werden. . . dann würde ich immer noch meinen Cheeseburger und Pommes genießen.
Der typische NOC-Workflow
Situationen wie diese passieren ständig. Betrachten Sie den typischen abgestuften Eskalations-Workflow. Wenn ein Event Trouble Ticket eingereicht wird, startet ein Level-1-Ingenieur einen grundlegenden Satz von Diagnose-Workflows, höchstwahrscheinlich basierend auf einem Standard-Playbook. Normalerweise beinhaltet dies eine Menge manueller Datenerfassung über die CLI, gefolgt vom Durchwühlen von Rohtext im „Stare and Compare“-Modus. Wenn der Level-1-Ingenieur dieses Problem nicht lösen kann, wird das Ticket in der Nahrungskette an den Level-2-Ingenieur weitergegeben, der wahrscheinlich die grundlegende Diagnose wiederholt, um die empfangenen Daten zu überprüfen und dann etwas tiefer zu graben. Und dann heißt es spülen und wiederholen, wenn das Problem zu einem Level-3-Ingenieur eskaliert.
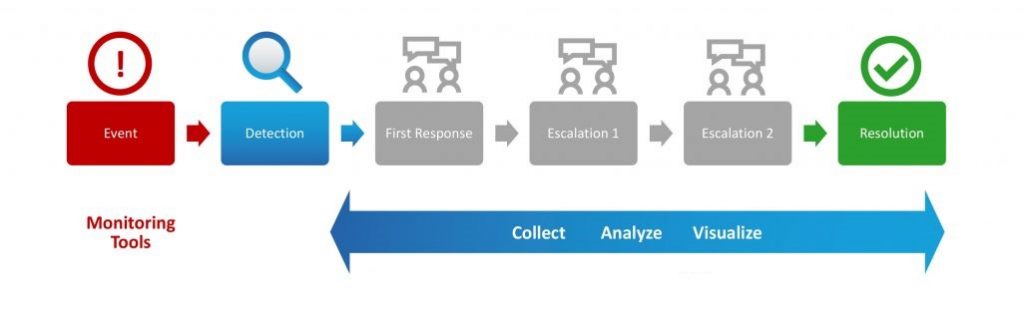
Die automatisierte Überwachung verschwendet praktisch keine Zeit mit der Erkennung eines Ereignisses, aber die Behebung bleibt ein höchst ineffizienter manueller Prozess.
Dieser typische NOC-Workflow ist manuell und repetitiv. Es erfordert viel doppelten Aufwand, um Daten zu überprüfen. Wenn das Ticket eskaliert wird, sind die bereitgestellten Diagnosedaten entweder zu wenig, um irgendwelche Rückschlüsse zu ziehen, oder zu viel (dh ein Protokollauszug). Sicherlich muss es einen effizienteren Weg geben.
NetBrain Stellt die Level-0-Netzwerkautomatisierung vor
NetBrain definiert den NOC-Eskalationsworkflow neu, um mit einer ereignisgesteuerten Diagnose zu beginnen. Wir nennen dies eine Level-0-Diagnose. Mit einer Level-0-Diagnose, a NetBrain Die Diagnose wird automatisch über die API-Integration gestartet, sobald Ihr Überwachungs- oder Event-Management-System ein Ereignis registriert. Die Daten werden sofort erfasst, wenn das Ereignis erkannt wird, und die Ergebnisse der Diagnose werden in das Ticket geschrieben, damit die Fehlerbehebung sie überprüfen und nutzen kann.
Netzwerkteams können Level-0-Diagnosen mit jeder API-fähigen Plattform einrichten, einschließlich Event-Management-Systemen, Ticketing-Systemen, IDS und anderen Überwachungssystemen.
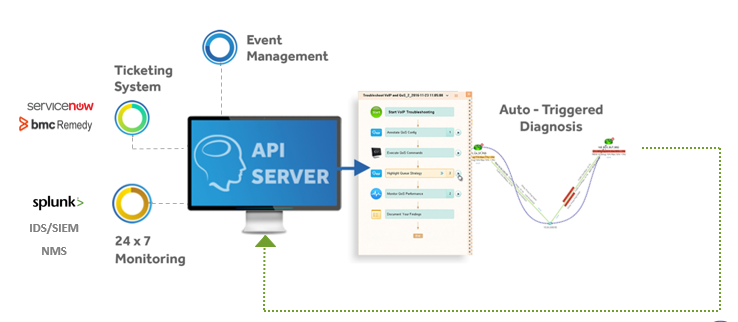
Ein Systemereignis eines Drittanbieters löst einen API-Aufruf aus NetBrain um das Problem in Echtzeit abzubilden und zu analysieren, während es passiert.
Nehmen wir an, Sie integrieren NetBrain mit Ihrem Einbruchmeldesystem. Wenn das IDS einen Einbruch meldet und einen Alarm auslöst, NetBrain bildet automatisch den Cyber-Angriffspfad entlang des Netzwerks ab, sammelt alle relevanten Daten und bewertet die Auswirkungen in Echtzeit. Als Ergebnis haben Sie eine Reihe von Daten, die während des Eingriffs gesammelt wurden – auch wenn Sie das Problem erst später analysieren können. Dies eröffnet Sicherheitsteams eine völlig neue Welt: Jetzt können sie analysieren, was während des Sicherheitsereignisses tatsächlich passiert ist, Schwachstellen finden und schneller als je zuvor beheben.
Und dieselbe ereignisgesteuerte Level-0-Diagnose kann von Ihren Überwachungstools (SolarWinds und anderen), Ihrem Ticketing-System (ServiceNow, BMC Remedy), Splunk oder irgendetwas mit einer API gestartet werden.
Vereinen Sie alle API-fähigen Systeme Ihres Teams durch NetBrain ermöglicht nahezu unbegrenzte Möglichkeiten und eine erheblich verbesserte Wirksamkeit; nicht nur für NetBrain sondern für jede einzelne Plattform im Ökosystem.