BGP の後は何が起こるでしょうか?
ハイブリッドクラウドネットワークにおける完全なパス可視化の実現 現代の企業では、ボーダーゲートウェイプロトコル(BGP)が分散ネットワークの接続において基盤的な役割を果たしています。これは、ルーティングプロトコルであり…

IT の問題が発生した場合、迅速な解決の鍵はデータに隠れています。障害発生時に生成されたデータ、履歴データ、トラブルシューティング中に取得されたライブ データなどです。適切な問題に対して適切なタイミングで適切なデータを入手することが重要です。したがって、IT データはネットワーク運用のあらゆる活動の中心であり、IT 運用チームに毎日届く大量のアラートとチケットの解決を自動化する鍵となります。
図1 – インフラストラクチャの生のマシンデータ
今日の複雑なインフラストラクチャは、これまで以上に多くのデータを保持しており、デバイス内に閉じ込められ、SNMP取得やその他のシステムに分散しており、トポロジ、パフォーマンス、 design intentネットワーク内のすべてのデバイスの現在の状態と動作を表示します。
トラブルシューティングに最も重要なデータは、デバイスの CLI または API を介して取得されます。通常、これらのデータは手動で 1 台ずつ順番に取得されます。実際、トラブルシューティングのほとんどの時間は、これらのコマンドライン診断の操作に費やされます。
これは主に手動のプロセスであるため、チケットの山に取り組むトラブルシューティングの取り組みをどのように拡張できるでしょうか? 人間の能力を超えて拡張するには、ネットワーク自動化を使用する必要があります。
ご存知のとおり、ネットワーク エンジニアリングは手順レベルでは非常に非効率的です。エンジニアは、1 つまたは 2 つの数値または結果を取得するために、多数のデバイスで順番にチェックを実行します。IT ツールには、他にも役立つ分析情報やデータが多数含まれていますが、IT ツール データにアクセスするには、複数の GUI またはコンソールをクリックして、結果を相関させる必要があります。
トラブルシューティングに必要なデータを収集することは、エンジニアにとって非常に時間のかかるプロセスであり、多くの場合、データの分析よりも時間がかかります。さらに、今日のデータは多次元、多形式であり、さまざまなデバイスやシステムに分散しているため、情報を効率的に分析することは非常に困難です。
IT のビッグ データの複雑さに加えて、問題に取り組む際には、エンジニアリング チームはこのデータに対して時系列の視点も持たなければなりません。言い換えれば、問題の根本原因を絞り込んで特定するには、さまざまな時点から取得したコンテキスト データが必要です。
自動化の支援がなければ、エンジニアは必要なデータをタイムリーに手動で取得して収集するのに苦労し、問題やチケットの解決が遅れることになります。
NetBrain 自動化は、(1)ハイブリッド ネットワークを自動的に検出し、(2)その豊富なデータを抽出し、(3)複雑なインフラストラクチャとその膨大な量の情報すべてをベースライン化し、環境全体の動的な数学的データ モデルを作成することで、この問題を解決します。
NetBrain レガシーまたは従来のネットワーク、ソフトウェア定義または仮想ネットワークを含む、あらゆるハイブリッドIT環境をエンドツーエンドでサポートします。 public cloud インフラストラクチャ。自動化されたSNMP、CLI、APIメカニズムと NetBrainの特許取得済みの近隣探索アルゴリズム、 NetBrain スケーラブルな効率で最大規模の環境をクロールできます。
SNMPはプラットフォーム識別やその他の有用なテレメトリに使用されますが、より豊富な診断機能と design intent データは自動化されたCLIまたはAPI取得によって取得されます。これにより、 NetBrainのデータモデルには、構成、プラットフォームの種類、ホスト名、IPアドレスの詳細情報だけでなく、 design intent レイヤー 2、レイヤー 3、ソフトウェア定義、仮想ネットワーク トポロジ。
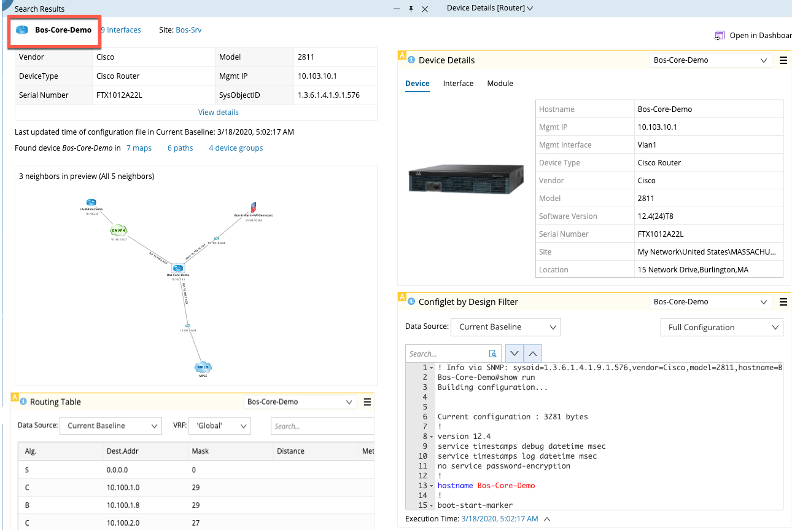
図2 - NetBrainのノード検出
データ分析の最初のステップはデータの抽出です。高品質な分析には、品質の高いデータと多次元データの両方を確保することが不可欠です。
今日のITデータは、次のような形で機械の中に保存されています。 状態テレメトリCPU、メモリ、ネットワークインターフェースの統計などのパフォーマンスメカニズムの健全性を伝え、 状態情報エンドツーエンドのアプリケーション パス、転送テーブル、アクティブ/フェイルオーバー ステータスなど、ネットワークの現在の動作に関するデータが提供されます。ネットワーク障害が発生すると、これら 2 つの重要なデータ タイプが生成されます。

図3 – ネットワーク障害によって生成されたデータ
状態データを使用すると、エンジニアは CPU、メモリ、インターフェース エラーなどのヘルス メトリック全体の変化を確認できます。これは通常、サポート データになりますが、影響範囲と根本原因を特定するのに役立ちます。

図4 – 条件変数のベースライン設定
状態変更データを使用すると、エンジニアは以前にベースライン設定されたネットワーク動作からの変化があるかどうかを判断できます。例としては、ファイアウォールのフェイルオーバー、コントロール プレーンの変更、BGP ピアリングの変更などがあります。
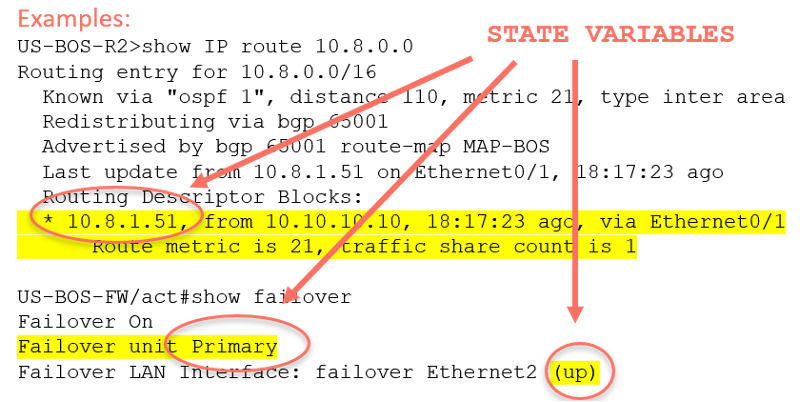
図5 – 状態変数のベースライン設定
組み合わせた条件と状態データを分析することで、エンジニアは根本原因を絞り込むことができます。 NetBrain すべてのネットワーク データの抽出を自動化し、インフラストラクチャの最新かつ完全な概要を常に把握し、関連するネットワークの状態と状態データをすべていつでも簡単に利用できるようにします。
ITチケットを調査する際、エンジニアは見ているデータが 通常のまたは 変化したことこの活動で重要なのは、時系列分析のために複数のデータポイントを時間内に持つことです。エンジニアは(1)を比較する必要があります。 ライブデータ(2)データ イベントの時間、および(3) ベースラインデータ、 時間の経過とともに計算されます。
核となる NetBrainのデータ モデルは、そのデータ ベースライン アルゴリズムです。ネットワーク内の完全な変数の「通常の」状態または値を自動的に計算することにより、エンジニアは以前の正常なネットワーク状態からの逸脱があった場合にすぐに知ることができます。
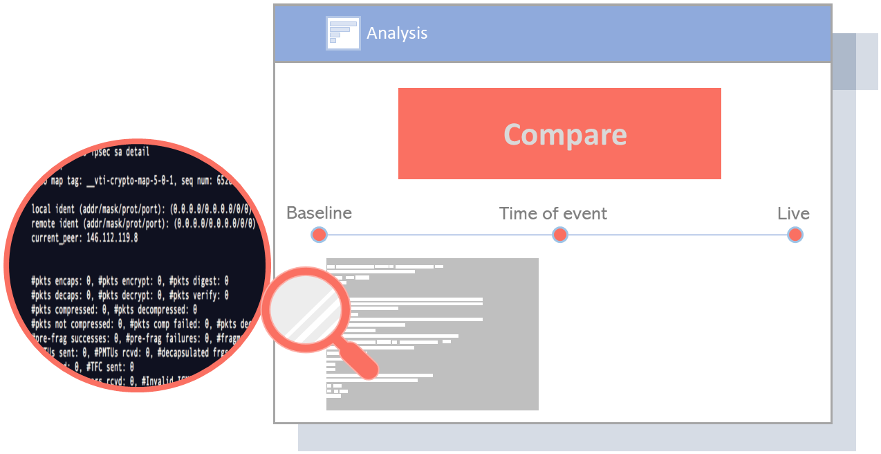
図6 – 時系列分析
これら3つの重要なデータポイント(ライブデータ、イベント発生時刻データ、ベースラインデータ)により、 NetBrain 自動化により、根本原因を特定するために不可欠な 3 つの観点からあらゆる IT チケットに対処できます。
IT の分野では、どのようなデータを分析する場合でも、データの視覚化を適用することが必要なステップであると思われます。 NetBrain ITのビッグデータを吸収し、すべてのノード、リンク、パフォーマンスメトリックの詳細を design intentそれを視覚的にアナログ化したものが NetBrain Dynamic Map.
A Dynamic Map IT インフラストラクチャを診断し、分析対象の診断データをコンテナ化する視覚的なメカニズムとして機能します。ネットワークと IT データの詳細な階層化されたビューを有効にすると、エンジニアは複雑な問題を複数の角度からリアルタイムで確認できます。
NetBrainのデータモデルと、 Dynamic Map IT データの複雑さをユーザーが簡単に理解できるようにし、ネットワーク自動化のユーザー インターフェイスとして機能します。
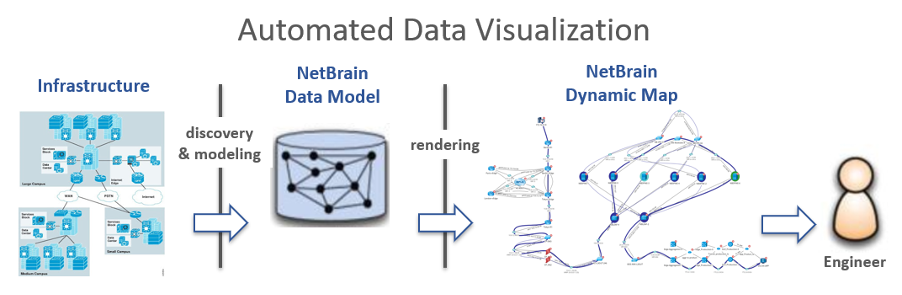
図7 – データ可視化ソフトウェアのアーキテクチャ
結果として NetBrainのディープディスカバリー、データ抽出、自動ベースラインは、ライブ環境の包括的な数学的データモデルであり、 design intent、トポロジー、そしてすべてのピースの内部の仕組みについて説明します。
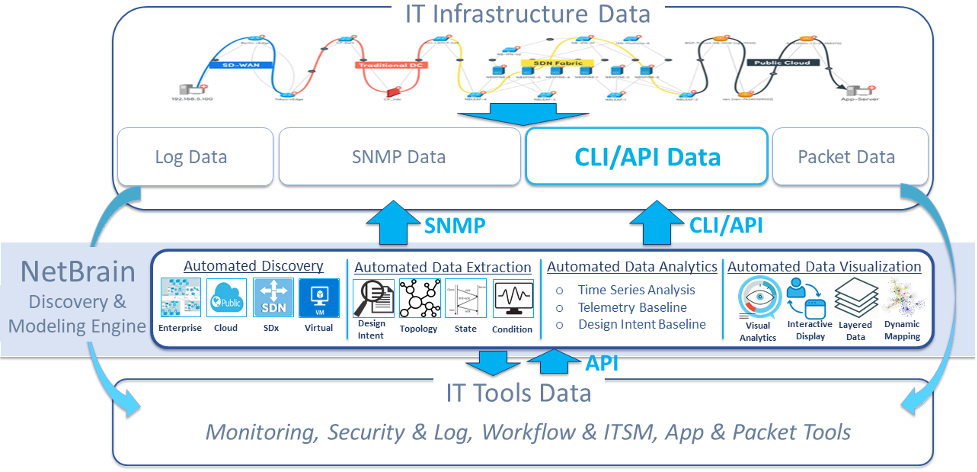
図8 - NetBrainの統合データモデルアーキテクチャ
NetBrainのデータモデルは、すべてのネットワーク自動化とパワーの基盤を提供します NetBrainの2つの基本的な自動化技術 – Dynamic Map 自動データ可視化とネットワーク自動化のためのユーザーインターフェース、そして 実行可能ファイル Runbook すべての診断および運用手順をコード化し、自動化します。
NetBrainのデータ モデルは、ライブ ネットワークの「デジタル ツイン」として機能し、IT 運用チームが複雑な環境全体の診断を自動化し、従来の手動の方法をはるかに超えるスピードと効率ですべての IT チケットに対処するために必要なすべてのデータとベースライン分析が含まれています。