 by Philippe Gervasi Le 7 juillet 2017
by Philippe Gervasi Le 7 juillet 2017
Le rôle de l'ingénieur réseau évolue, mais avant de rouler des yeux et de dire "oh non, pas un autre article sur l'automatisation du réseau", écoutez-moi. Il existe d'excellents articles sur la façon dont l'automatisation du réseau fait partie de ce changement, mais depuis que j'ai quitté le monde VAR il y a quelques années et que je travaille en interne dans quelques grandes entreprises, mon travail quotidien semble se concentrer davantage et plus sur une chose : l'analytique.
L'analyse est la collecte et l'interprétation des données, et l'analyse du réseau est la collecte et l'analyse des données de notre infrastructure réseau, en particulier en ce qui concerne les performances des applications. J'ai toujours occupé des postes d'ingénieur réseau relativement traditionnels, donc je ne suis pas concerné par l'analyse des données simplement parce que j'aime les données. Au lieu de cela, je veux utiliser ces informations pour trouver des modèles, des corrélations et quelque chose significatif et exploitable pour améliorer le réseau d'une manière ou d'une autre.

Le changement pour moi au cours des deux dernières années a exigé que je me concentre moins sur la configuration d'un basculement du cœur d'un centre de données et plus sur la détermination de ce qui se passe réellement sur le réseau au jour le jour. Cela a eu à voir spécifiquement avec le dépannage de la mauvaise livraison des applications, la sécurité des informations et la planification des capacités. Et tout cela nécessitait des analyses de données réseau.
Peu de temps après avoir accepté un poste dans une grande entreprise, j'ai reçu un e-mail d'un scientifique qui gérait les clusters de calcul haute performance de son équipe. À peu près à la même heure chaque nuit, la transmission des données à nos clients externes a échoué et a ensuite pris plusieurs minutes pour se rétablir. Ces scientifiques ont collecté une énorme quantité de données atmosphériques tout au long de la journée qu'ils ont ensuite analysées pour les clients qui ont acheté les rapports, les données brutes ou les deux. Certains de ces clients étaient de très grandes institutions scientifiques qui extrayaient ces informations extrêmement urgentes via FTP.
L'application qui gérait le cluster vivait sur un serveur bare metal situé en haut du rack et connecté au cluster via une connectivité propriétaire, mais était également connecté au réseau local à des fins de gestion et pour servir les rapports terminés. L'échec se produisait avec plusieurs clients, j'ai donc écarté le fait que le problème était de leur côté. Il devait être sur le nôtre. Quelque chose se passait sur l'un de nos hôtes, le contrôleur de cluster ou quelque part sur notre chemin réseau.
Le responsable scientifique s'est approprié l'incident et a vérifié si l'application et les serveurs fonctionnaient correctement. Tout semblait ok de son côté, il soupçonnait donc un problème de réseau. Nous ne pouvions pas facilement identifier une activité réseau qui aurait été en conflit, j'ai donc commencé par examiner la configuration de tous les périphériques réseau sur le chemin. Je me suis connecté aux commutateurs, pare-feu et routeurs, mais je n'ai rien vu d'anormal.
Que se passait-il ici? Les journaux révéleraient la réponse. En utilisant le logiciel que nous avions à l'époque, j'ai constaté que nous collections très peu d'informations à partir de très peu d'appareils. Il n'y avait pas grand-chose d'autre à regarder. Nous avions besoin d'une sorte d'information significative. Bien sûr, j'aurais pu fouiner dans les appareils toute la nuit pour voir ce qui se passait en temps réel, mais je savais que je ne serais pas en mesure de corréler facilement quoi que ce soit. Au lieu de cela, j'ai configuré notre outil de collecte de données pour collecter de tout sur le réseau. J'ai configuré SNMP sur certains appareils, NETFLOW sur d'autres, et pour ceux qui ne supportaient ni l'un ni l'autre, j'ai configuré l'outil de collecte pour envoyer un ping continu à ces adresses IP et analyser leurs ports ouverts.
Après quelques jours d'appels téléphoniques, de recherches sur Google et de discussions avec le scientifique principal, un client est devenu très impatient et en colère que ses importations échouent presque tous les soirs. C'est devenu un problème très médiatisé et une priorité absolue pour moi. J'ai dédié plus d'espace de stockage au logiciel de collecte de données et je l'ai laissé fonctionner pendant une semaine. Lorsque j'ai fouillé dans les résultats, j'ai repéré un pic inhabituel dans le processeur du contrôleur d'application à peu près à la même heure chaque nuit - l'heure à laquelle le problème a commencé. C'était un bon début, mais il n'y avait aucune raison que le scientifique principal puisse trouver sur le serveur lui-même qui en serait la cause. Les liaisons réseau n'ont connu aucune congestion inhabituelle et aucun de nos commutateurs sur le chemin n'a montré quoi que ce soit d'inhabituel.
Parce que notre outil de collecte était médiocre, j'ai dû passer moi-même pas mal d'heures à me pencher sur toutes ces nouvelles données. Mon collègue m'a aidé en écrivant un script pour rechercher l'utilisation du processeur, des liens et de la mémoire, puis en le présentant sous forme graphique via une sorte de connecteur de messagerie intelligent. Après tout ce temps et ces efforts, un drapeau rouge est apparu, nous indiquant un commutateur d'accès qui avait un pic de CPU chaque nuit. Je me suis connecté au commutateur et j'ai vu que la disponibilité reflétait un redémarrage probable à l'heure fatidique de la nuit précédente.
Avant de quitter le travail, j'ai remplacé le commutateur, vérifié que l'adresse IP était l'un des widgets de notre tableau de bord de surveillance et mis en place un simple ping persistant. Mon collègue a écrit un script pour nous envoyer un e-mail en cas de chute des pings, et nous avons configuré le logiciel de surveillance pour envoyer une alerte en cas de pic du processeur. À notre grande consternation, le lendemain matin, nous avons reçu des e-mails nous informant que les pings avaient chuté et que les notifications du logiciel de collecte avaient augmenté. Nous avons vérifié l'interrupteur - il était allumé. J'ai vérifié la disponibilité - j'ai montré un redémarrage au milieu de la nuit. Nous étions certains que la réponse se trouvait dans les données. Mais c'était tellement fastidieux de le parcourir et cela prenait beaucoup trop de temps pour notre client. Quelque part là-dedans, il devait y avoir un schéma ou une corrélation que nous n'avions pas trouvé, alors nous avons continué à chercher. Nous avions besoin d'une meilleure façon de le faire, mais pour l'instant, nous avons travaillé dur en utilisant le logiciel et les scripts personnalisés du mieux que nous pouvions. Puis nous avons trouvé quelque chose. Un périphérique inconnu à une adresse IP inconnue est devenu très bavard lorsque le commutateur a redémarré. Ce n'était pas une adresse en double, et ce n'était pas sur le même sous-réseau, mais c'était quelque chose qui se produisait à la même heure chaque nuit.
Retrouver l'appareil était facile. Ce n'était pas dans DNS, mais c'était une réservation dans DHCP. Il s'est avéré que c'était le contrôleur de la climatisation de secours qui fonctionnait tous les soirs. Cela ne serait normalement pas un problème, mais lorsque nous sommes descendus dans la salle des serveurs, nous avons constaté que l'unité AC était branchée sur le même PDU que le commutateur. Il n'y avait rien d'autre sur le PDU, et ce n'était pas quelque chose que nous avions examiné auparavant.
Lorsque l'unité AC a démarré, il y avait suffisamment de drain sur le circuit pour que le commutateur redémarre. C'était du moins notre théorie. Nous avons déplacé le commutateur vers une autre PDU et avons appelé les gens du CVC. Le commutateur n'a pas redémarré cette nuit-là, et d'après ce que je comprends, les gens du CVC ont trouvé un problème avec un capteur et l'électricien a résolu le problème d'alimentation.
Pour comprendre cela, il a fallu collecter de nombreuses données et les analyser intelligemment. C'est là que mes collègues ingénieurs réseau et moi-même nous retrouvons ces jours-ci à travailler dans l'informatique d'entreprise. Bien sûr, il y a la mise à niveau occasionnelle du pare-feu ou le remplacement du commutateur MDF, mais la plupart du temps, je collecte et analyse des données en essayant de dépanner les performances des applications ou de travailler sur une tâche de sécurité des informations.
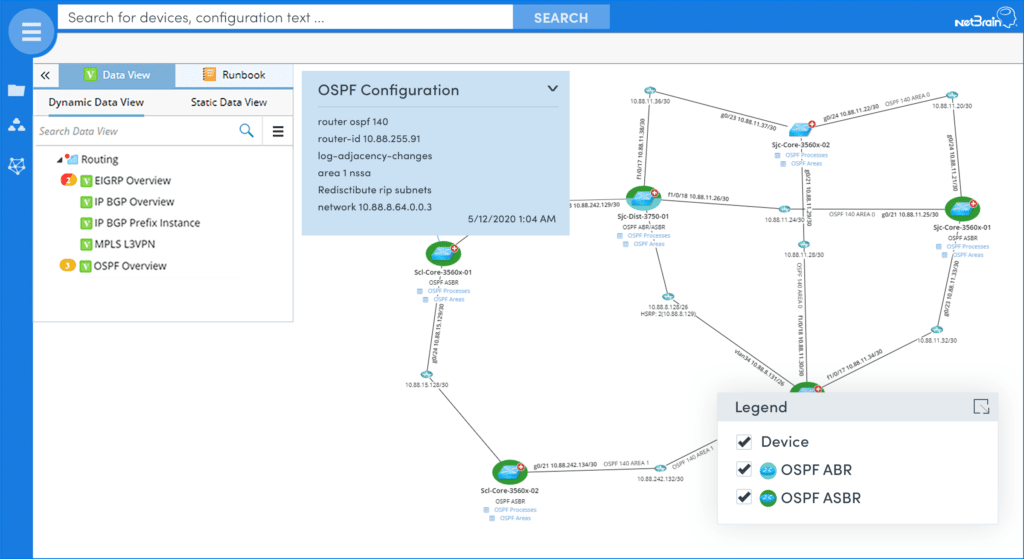
Je ne crois pas que le rôle d'un ingénieur réseau évolue au point que nous devions devenir des programmeurs et des scientifiques des données, mais ce que je vois, c'est une tendance croissante à être très habile à savoir comment collecter et analyser une énorme quantité de données dynamiques et informations éphémères.
NetBrain a récemment annoncé une technologie très prometteuse qui vise à relever ce défi d'analyse - ils l'appellent Exécutable Runbooks. Fondamentalement, un Runbook offre un moyen de collecter et d'analyser automatiquement les données du réseau. Depuis ces Runbooks peuvent être adaptés (par les programmeurs et les non-programmeurs), ils peuvent être utilisés pour effectuer des analyses pour n'importe quelle fonction du réseau. L'exemple ci-dessous est un Runbook qui a été écrit pour analyser la conception de routage OSPF.