 by 1 de Agosto, 2018
by 1 de Agosto, 2018
Cuando estoy bajo ataque de amenazas a la seguridad de la red, tiene una gran cantidad de herramientas (sistemas de detección de intrusiones (IDS), sistemas de prevención de intrusiones (IPS), software antivirus, tecnologías de gestión de eventos e información de seguridad (SIEM) que no pierden tiempo en enviarle una alerta de que algo anda mal.
Cuando se identifica una amenaza potencial, la velocidad es esencial. Cuanto más rápido se puedan localizar, aislar y mitigar las amenazas a la seguridad de la red, menos posibilidades habrá de que se produzcan daños o pérdidas reales. Si bien el proceso de alerta está completamente automatizado, razón por la cual casi no se pierde tiempo en detectar problemas, el flujo de trabajo típico de respuesta de seguridad sigue siendo en gran medida manual y requiere mucho tiempo. Aquí es donde entran en juego la visibilidad y la automatización.
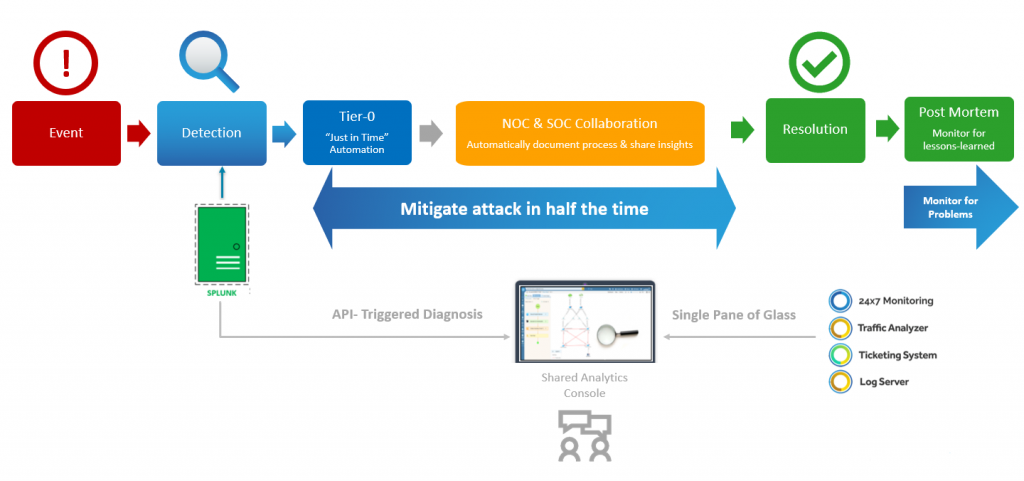 Cuando cada segundo cuenta, la automatización "justo a tiempo" activa un diagnóstico de nivel 0 que reduce drásticamente el tiempo de mitigación de ataques.
Cuando cada segundo cuenta, la automatización "justo a tiempo" activa un diagnóstico de nivel 0 que reduce drásticamente el tiempo de mitigación de ataques.
Ganar visibilidad sobre el impacto de las amenazas a la seguridad de la red
En primer lugar, hay que comprender el impacto de las amenazas a la seguridad de la red. Su IDS/IPS o SIEM no le brindarán mucha información, aparte de informarle que hay tráfico potencialmente malicioso. Sus diagramas de red le dan una idea de cómo está conectada la red, por lo que verá cuál es el impacto potencial. Pero con demasiada frecuencia los diagramas están incompletos o desactualizados. Tiene que confiar en su memoria, lo que se vuelve cada vez más desafiante en entornos complejos, de múltiples proveedores, definidos por software e híbridos, o emitir manualmente un montón de comandos CLI y examinar minuciosamente una gran cantidad de resultados de texto. Esto le brinda visibilidad de la configuración y el diseño a nivel de dispositivo, pero no a nivel de red. Es mucho tiempo para tener una visión muy limitada de la situación. Y cuando todo lo demás falla, deberá derivar el asunto a un ingeniero de nivel superior. Pero como todos sabemos, encontrar al experto que pueda detener el sangrado es más fácil de decir que de hacer. Los “silos de datos” tradicionales entre el NOC y el SOC hacen que la colaboración y la escalada sean menos fluidas: diferentes equipos dependen de diferentes herramientas, diferentes sistemas y diferentes conjuntos de datos.
Automatización “justo a tiempo” para mitigar las amenazas a la seguridad de la red
Digamos que un atacante intenta abrumar un dispositivo objetivo con paquetes de solicitud de eco ICMP (inundación de ping). Su IPS detecta la amenaza y genera una trampa SNMP para Splunk. Splunk recibe la trampa y, mediante un mecanismo de búsqueda y alerta, activa una llamada a la API para NetBrain con parámetros de entrada Origen (atacante) y Destino (víctima).
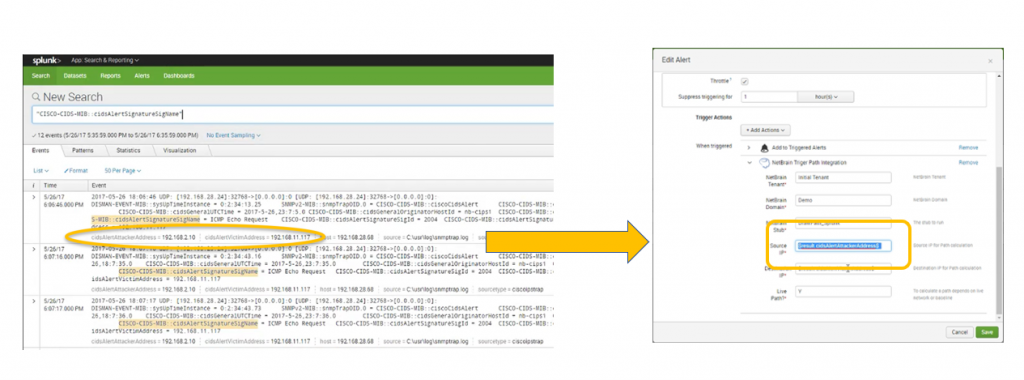 Tan pronto como Splunk detecta amenazas a la seguridad de la red, las llamadas API se activan NetBrain para mapear automáticamente el área del problema y diagnosticar el problema en tiempo real.
Tan pronto como Splunk detecta amenazas a la seguridad de la red, las llamadas API se activan NetBrain para mapear automáticamente el área del problema y diagnosticar el problema en tiempo real.
NetBrain entonces hace dos cosas automáticamente:
- Calcula la ruta entre el atacante y la víctima, construye un Dynamic Map de la ruta de ataque y proporciona automáticamente la URL de este mapa a Splunk.
- ejecuta un Runbook — una serie de procedimientos programables (y personalizables) para recopilar y analizar datos específicos de la red — que realiza los pasos iniciales de solución de problemas, captura estadísticas de rendimiento y documenta el estado de la red en el momento en que se detectó la amenaza.
A esto lo llamamos diagnóstico de nivel 0 porque toda esta clasificación y análisis ocurre automáticamente, antes de que cualquier ser humano intervenga. Las capacidades de automatización "justo a tiempo" le brindan información y análisis en tiempo real sobre las amenazas a la seguridad de la red mientras ocurren.
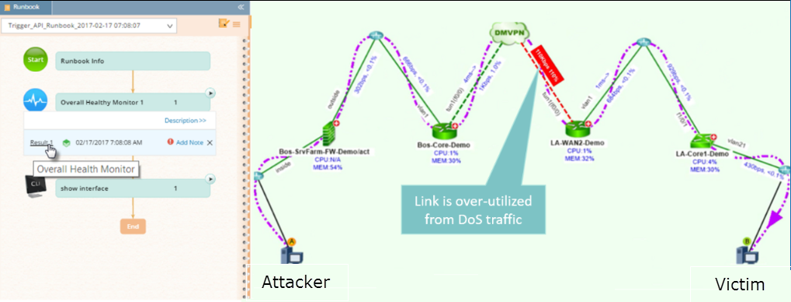
NetBrain crea automáticamente un Dynamic Map de la ruta de ataque, y Ejecutable Runbookrecopilamos y analizamos automáticamente todos los datos por usted.
Todos los resultados de diagnóstico se registran dentro de la Runbook. Esta consola de análisis compartida permite que todos vean quién hizo qué y cuándo, lo que elimina la necesidad de reinventar la rueda durante la escalada (ejecutar los mismos análisis que hicieron los ingenieros anteriores) y poner a diferentes equipos (NOC y SOC) en sintonía para mitigar un ataque. De hecho, un NetBrain encuesta descubrió que la falta de colaboración entre la red y los equipos de seguridad era el principal desafío al solucionar problemas de seguridad de la red. Los equipos de NOC y SOC pueden documentar automáticamente los procesos (personalizando Runbooks sobre la marcha con los siguientes mejores pasos que se deben tomar) y compartir información crítica que reduce drásticamente el tiempo de resolución.
Durante mucho tiempo, las organizaciones han tenido la capacidad de generar alertas automáticamente cuando amenazas aparentes a la seguridad de la red atacan su red. ¿No es hora de que los ingenieros encargados de mitigar estos ataques tengan el mismo nivel de automatización en su arsenal?
Obtenga más información sobre cómo NetBrain puede ayudarte en tu esfuerzos de seguridad.
Mira nuestro blog en Garantizar la seguridad y la colaboración en red efectivas.