Single-line Rule
Single-line rule (line pattern) represents a type of expression serving to parse variables that reside in one or multiple lines of text. The system adopts line-pattern-matching syntax to apply the given line patterns to identify and parse variables.
You can write a line pattern in the following types of Parser components:
 |
Note: Line Pattern does not apply to Table Parser. |
This section introduces the following five types of line patterns in the system, each with its syntax.
Simple Line Pattern
A simple line pattern is the most widely used line pattern to parse variables in one line.
The following table introduces sample pairs of raw text and simple line patterns for each variable type.
| Variable Type | Sample of Raw Text | Sample of Line Pattern |
| String | Version 12.2(53)SE2, RELEASE SOFTWARE | Version $version, RELEASE SOFTWARE |
| Multi-string | R1 uptime is 51 weeks, 4 days, 23 hours, 3 minutes | uptime is $mstring:uptime |
| Integer | MTU 1500 bytes | MTU $int:mtu bytes |
| Float/Double | Next hello sent in 1.824 secs | Next hello sent in $float:hello_time secs |
| Boolean | single-connect=false | single-connect=$bool:single_conn |
| Enumeration |
| $duplex(Full-duplex|Half-duplex|Auto-duplex) |
| Dummy | 0 input errors, 0 CRC, 0 frame, 0 overrun | $int:_dummy input errors, $int:crc CRC, $int:_dummy frame, $int:overrun overrun |
The following two characters can be used in a simple line pattern to match the start/end of a string or a line.
| Character | Description | Sample Line Pattern |
| ^ | Match the start of a line. | ^$intf is $mstring:state, line protocol is $status |
| $ | Match the end of a line. | Neighbor priority is $priority, State is $state, $int:changes state changes$ |
|
Note: When a variable defined in a simple line pattern does not include a specific data type, e.g., $var1, its variable type will be auto-assigned depending on the data type of its parsed values. The system provides this auto-validation mechanism to avoid a numerical value (integer/float/double-type) being mistakenly defined and parsed as a string, which cannot be compared or processed as numbers in further Network Intent Automation.
|
Match Lines by Variable
The system provides a pattern of matching lines by variable (LineByVariable) and parses multiple lines of raw CLI text for specified variables. It follows the following detailed rules:
- Using a comma (,) to separate var1 and var2 only returns the lines where the variables reside.
- Using a hyphen (-) to connect var1 and var2 returns the consecutive lines from the line of var1 to the line of var2. If the end line is not specified in the pattern, for example, “LinesByVariable[$var]:$var1-“, it will return the rest of the paragraph.
| Format | Sample of Raw Text | Sample of Definition |
| LinesByVariable[$var]: $var1, $var2 | 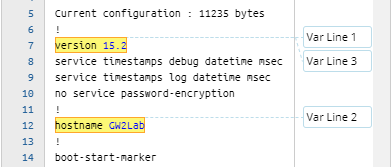 | 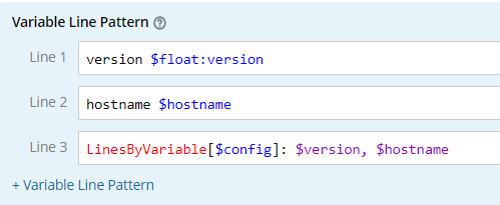 |
Match Lines by Keyword
The system provides a pattern of matching lines by keyword (LinesByKeyword) to parse multiple lines of raw CLI text for a specified keyword. It follows the following detailed rules:
- Return all matched lines between the start/end line of simple variable group or sub-paragraphs of paragraph group.
- Allow simple line patterns, including ^ and $.
| Format | Sample of Raw Text | Sample of Definition |
| LinesByKeyword[$var]: simple line pattern | 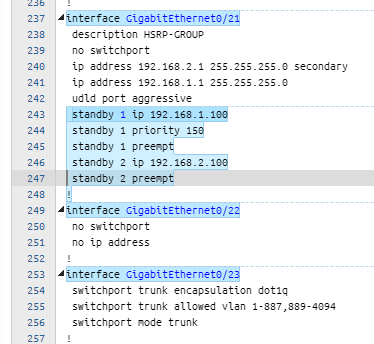 | 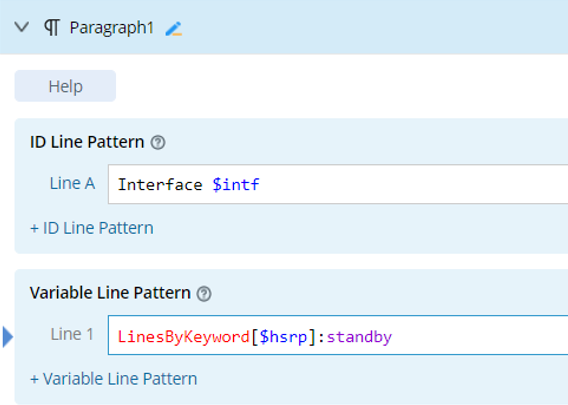 |
For more information, see Parse the Lines of Keyword.
Match Lines by Regex
The system provides a pattern of matching lines by regex (LinesByRegex) to parse multiple lines of raw CLI text for a specified regex. It follows the following detailed rules:
- Return all matched lines between the start/end line of simple variable group or sub-paragraphs of paragraph group.
- Support simple regex.
| Format | Sample of Raw Text | Sample of Definition |
| LinesByRegex[$access]: simple regex | 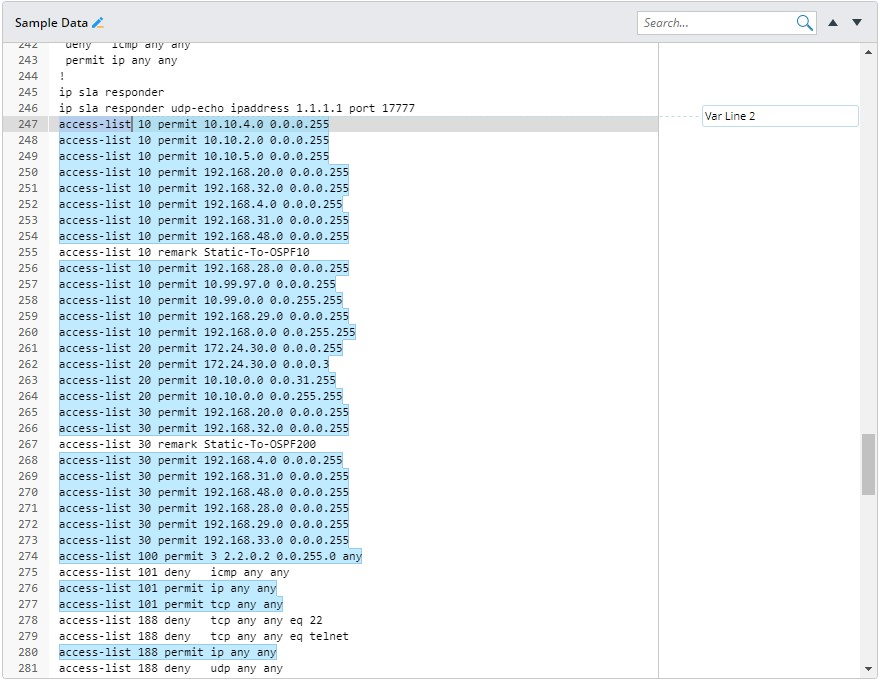 | 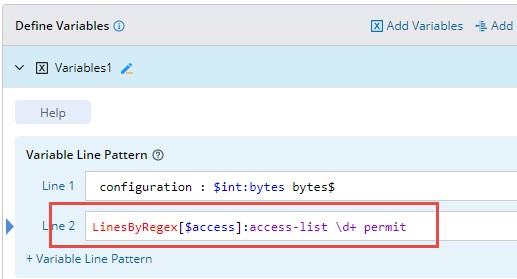 |
Select Variable
The system provides an option (SelectVariable) to parse the values of specified variables in order of appearance. It follows the following detailed rules:
- Use a comma (,) to separate two variables, the value of which will be used as the parsed result depends on the display order and its availability. For example, if the value of the first variable is not null, it will be used as the parsed result; otherwise, the value of the second variable will be parsed, and so on.
- Only the variables defined in the previous line patterns can be used in this pattern. The variables defined in the pattern of matching lines by keyword (LinesByKeyword) and matching lines by variable (LinesByVariable) are allowed.
| Format | Sample of Raw Text | Sample of Definition |
| SelectVariable[$var]: $var1, $var2 | 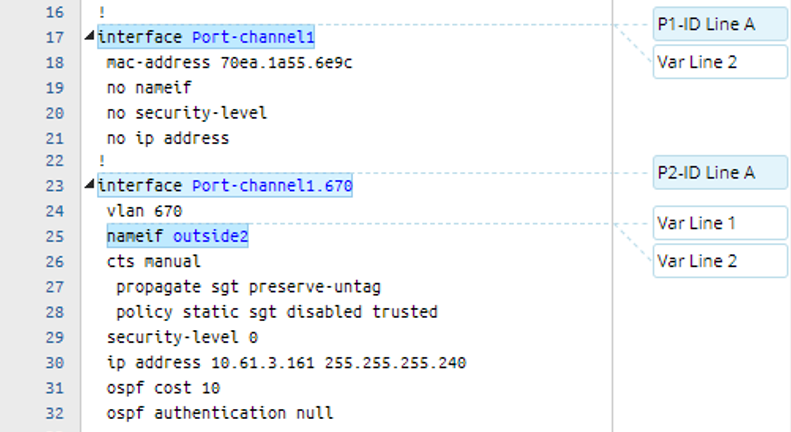 | 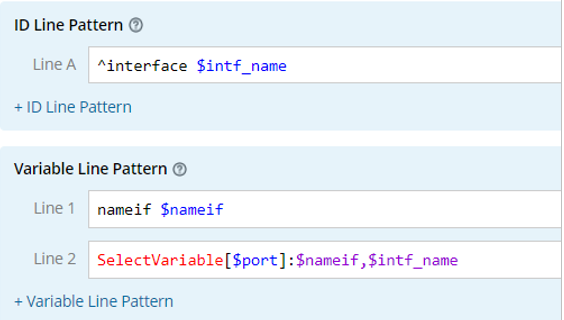 |
|
Note: The pattern of matching value by variables (SelectVariable) can only be used in the variable line pattern of Variable Parser or Paragraph Parser. |
Regex
The system provides a specific regex pattern using the regular expression (Regex for short). Starting with a specific keyword: Regex or mregex, the regex pattern declares all the required variables (separated by a comma) in a pair of square brackets, followed by a colon (:) and Regex that can parse text lines. Each pair of parentheses in a regex represents a capturing group to group listed characters to form a sub-pattern, and their matched values will be assigned to each variable defined inside the pair of square brackets by sequence.
You can use the following two types of regex patterns to define a Visual Parser.
| Pattern | Description | Format | Sample of Raw Text | Sample of Regex |
| Regex for a Single Line | A regular expression to parse strings in one line. | regex[$type1:var1, $type2:var2]:regex expression | 3.255.255.12 em2.0 2.2.2.2:0 12 192.168.1.1 em1.0 2.2.2.2:0 12 172.16.8.12 em3.0 2.2.2.2:0 12 | regex[$nbr_addr,$intf,$label_space_id,$int:hold_time]:^(\d+\.\d+\.\d+\.\d+)\s+(\S+)\s+(\S+)\s+(\d+) |
| Regex for Multiple Lines | A regular expression to parse strings crossing lines. | mregex[$var1]:regex expression | Multicast reserved groups joined: 224.0.0.1 224.0.0.2 224.0.0.13 224.0.0.22 Directed broadcast forwarding is disabled | mregex[$multicast]:Multicast reserved groups joined: (.*?)Directed |
Frequently Used Regex Syntax
The following table introduces the most popular regex syntax in detail.
| Character | Description |
| . | Match any character except a new line. |
| \ | Escape a special character. |
| () | Group all listed characters to form a sub-pattern. |
| ^ | Match the start of a string, or the start of a line in Multiline mode. |
| $ | Match the end of a string or the end of a line in Multiline mode. |
| * | Match the preceding shortest pattern zero-or-more times. For example, "ab*" can match "a", "ab", and "abb". |
| + | Match the preceding shortest pattern once or more times. For example, "be+" can match "been" and "bent". |
| ? | Make the preceding shortest pattern optional. It matches zero or one time. For example, "ab?" can match "a" and "ab". |
| \d | Match any decimal digit from 0 to 9. |
| \s | Match any whitespace character, equivalent to the set [\f\n\r\t\v]. |
| \S | Match any non-whitespace character, equivalent to the set [^ \f\n\r\t\v]. |
Use '#NOT' in Line Pattern
The operator #NOT can be used in visual parser to enhance the parsing ability. #NOT in a line pattern means negation, and has the following two formats:
- # NOT: For example, #NOT( permit| deny) will match lines that do not include permit or deny.
- ^#NOT: For example, ^#NOT( permit| deny) will match lines that do not start with permit or deny.
Example of using ‘#NOT’:
Parse acl_config for every acl_id, use ^#NOT to get correct end of paragraph.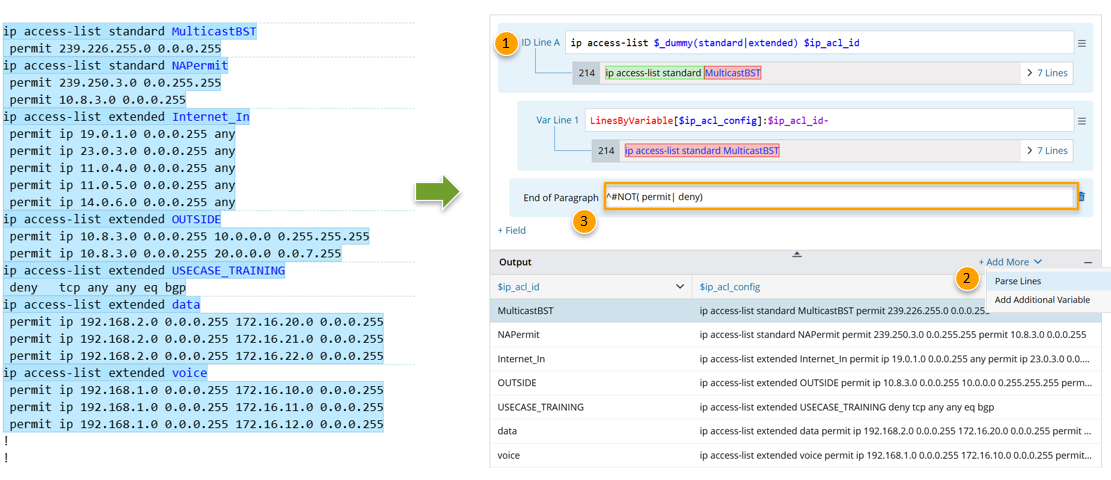
- Parse variable $ip_acl_id, use (standard|extended) in the line pattern to narrow down the correct ip access-list xx content.
- Parse variable $ip_acl_config, define parse lines: Parse Lines > The line between $ip_acl_id to End.

- Add End of Paragraph and fill the line pattern with ^#NOT( permit| deny) to fine the correct paragraph.
Tip: It is required to add space before permit and deny in this example.