ID Line

Contents
Identifier (ID) Line is used as the key to identify recurring paragraphs. For those duplicate variables reside in recurring paragraphs, you can use ID Line Pattern to divide lines of text into segmented paragraphs first, and then use Variable Line Pattern to define more variables.
Note: ID Line Pattern is only applicable to paragraph parser, and multiple ID Line Patterns are allowed.
The default and mandatory ID Line is labeled as ID Line Pattern A, which divides lines of text into paragraphs. As shown below, the line of text that matches ID Line A’s line pattern is highlighted in each paragraph and labeled with numberings. The parsed values of variables are differentiated with a foreground color. When you click on a variable’s value in the parsed result, the value text will be highlighted in the sample text.
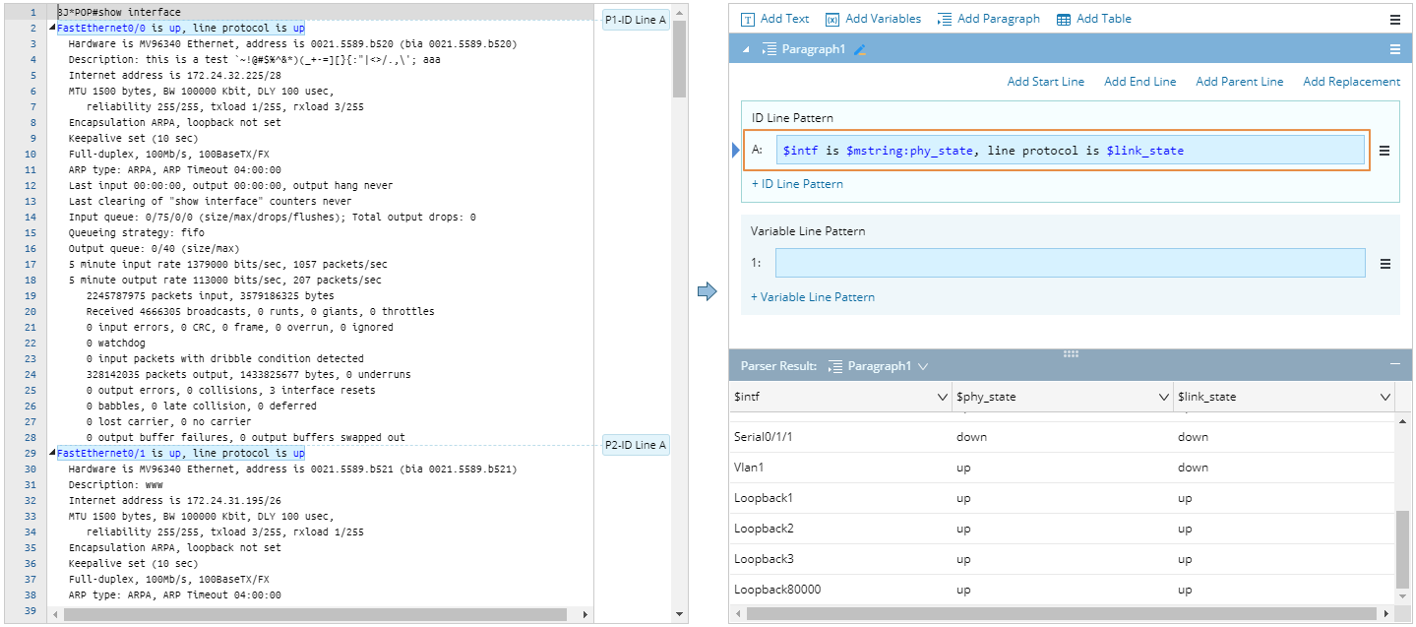
Beyond the ID Line Pattern A, you have options to add more ID Line Patterns B~Z as filters to filter out unqualified paragraphs.
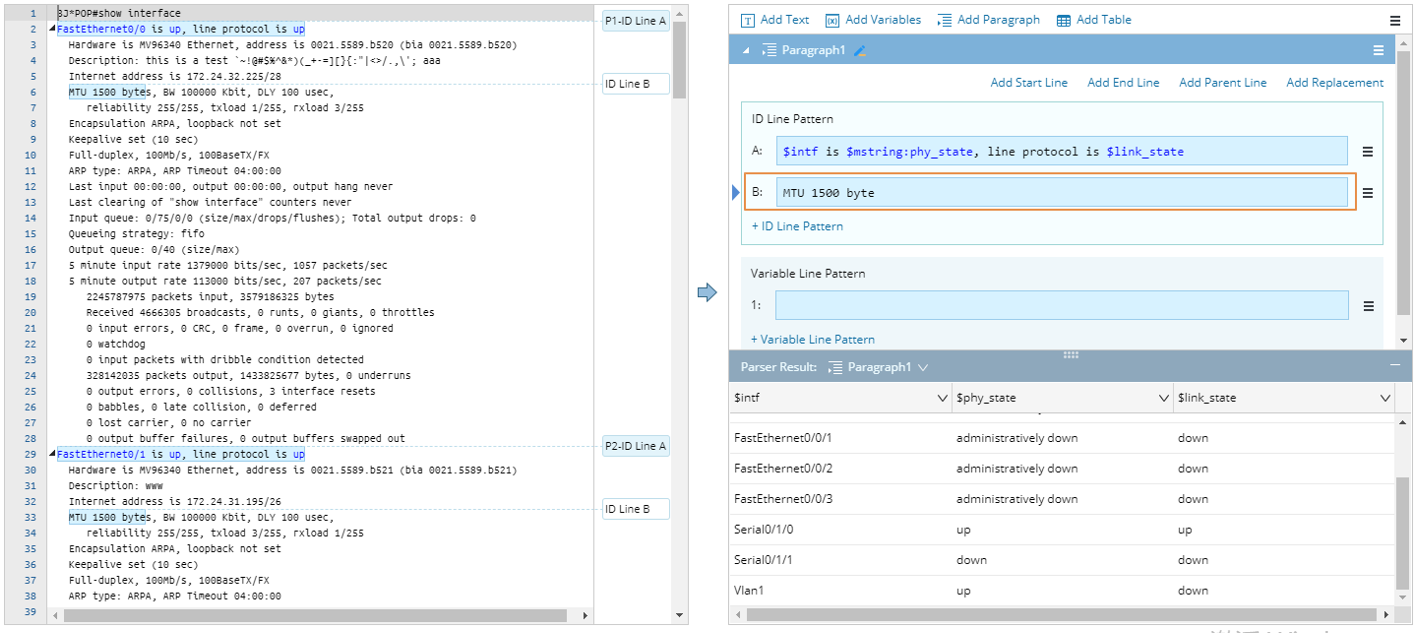
For example, the ID Line Pattern A of the following paragraph parser uses interface name as the identifier to separate paragraphs, and the ID Line Pattern B further defines the condition that only the paragraphs for those interfaces, of which the MTU’s value is 1500 bytes, will be used for parsing. The lines of text that match the line pattern of ID Line B~Z are also highlighted and marked with a label. The labels for ID Line B~Z do not contain numbering because their numbering keeps the same as the paragraph numbering of ID Line A.
Define ID Line Using Regex Pattern
Besides NetBrain-specific patterns, you can use Regex Pattern to define an ID Line, especially when there are no regular keywords before and after a target variable in that ID line.
For example, the target ID Line A of the following raw text contains a variable $intf (interface name). In this case, using Regex Pattern is more suitable to define the ID Line Pattern. For more information about the syntax, refer to Regex Pattern.

Use ID Line to Parse Wrapped Table Text
Generally, Table Parser is recommended to parse table-formatted text. However, when it comes to a table with wrapped text in a cell, you need a workaround, that is, using a paragraph parser (with ID Line Pattern) to parse wrapped text.
For example, the first cell of the table column (Ports) has wrapped text, which cannot be completely parsed by table parsers. You can use Regex to finish a two-step definition:
1.Define the first three table columns (VLAN, NAME, STATUS) as the ID Line using regex, which means every first three cells in each row of the table is an independent paragraph.
2.Parse multiple lines of text inside each paragraph.
