Was sind unsere größten Herausforderungen für die Netzwerkautomatisierung? Ich rede von heutigen Netzwerken in der realen Welt – keine Herausforderungen auf der Straße. Ich spreche von unseren aktuellen täglichen Arbeitsabläufen und Aufgaben: Fehlerbehebung, change management, Sicherheit und Dokumentation in SDN-, Multi-Cloud- und hybriden Netzwerken.
Es gibt zwei grundlegende Dinge, die die Netzwerkautomatisierung zu einer Herausforderung machen. Das erste ist das Netzwerk selbst. Netzwerke sind heute sehr komplex. Wir haben die Virtualisierung gerade hinter uns gelassen, und dann kommen softwaredefinierte Netzwerke wie Cisco ACI und jetzt haben wir SD-WAN. Das Zweite sind unsere Tools und Daten. Wir verwenden viele Tools – Ticketsysteme wie ServiceNow, 24×7-Überwachungslösungen, Splunk, SEIM und IDS und sogar APM. Jedes Tool erledigt seine eigene Aufgabe, funktioniert aber auf einer „Insel“. Wir landen mit vielen Datensilos. So viele Tools mit einer Fülle von Daten bedeuten, dass die Fehlerbehebung automatisiert wird bzw change management ist nicht so einfach.
Abgesehen davon gibt es 5 „versteckte“ Herausforderungen der Netzwerkautomatisierung für die alltägliche praktische Netzwerkautomatisierung, die ich im Laufe der Jahre gelernt habe.
Die menschliche Dimension
Wenn Menschen „Netzwerkautomatisierung“ hören, haben sie oft eine von zwei Reaktionen. Entweder sagen sie: „Das ist es nicht wert“, oder sie denken: „Du versuchst mir meinen Job wegzunehmen.“ Im ersten Fall glauben Netzwerkmanager, dass sie viel Geld ausgeben werden, ohne eine große Rendite für ihre Investition zu erzielen. Sie möchten nicht daran denken, eine weitere Lösung zu kaufen, Zeit damit zu verbringen, eine neue Vorgehensweise zu finden oder ein weiteres Skript zu schreiben. Am anderen Ende hören einige Netzwerkingenieure – in der Regel die NOC-Leute der ersten Ebene – „Jobeliminierung“, wenn Sie das Wort „Automatisierung“ sagen.
Sondern Automatisierung is lohnt sich und wird dir deinen Job nicht wegnehmen. Es stellt die Gleichung auf den Kopf: Die Automatisierung nimmt die Jobs weg, die sich nicht lohnen. Automatisierung kann – und wird – die Arbeit der Menschen nicht beseitigen. Aber es eliminiert all die Sackgassenarbeit, die niemand tun möchte. Es gibt allen Zeit, um anspruchsvollere Aufgaben zu übernehmen.
Scripts
In den heutigen Netzwerken reicht Scripting nicht mehr aus. Jeder, der ein Python- oder Java-Skript geschrieben hat, weiß, dass die größte Herausforderung bei der Netzwerkautomatisierung bei Skripten nicht darin besteht, sie zu schreiben. Es pflegt sie. Sie haben einmal ein Skript geschrieben, aber dann, wenn sich das Netzwerk ändert, müssen Sie viel Debugging durchführen. Und das Teilen dieses Skripts mit anderen Leuten ist nicht so einfach.
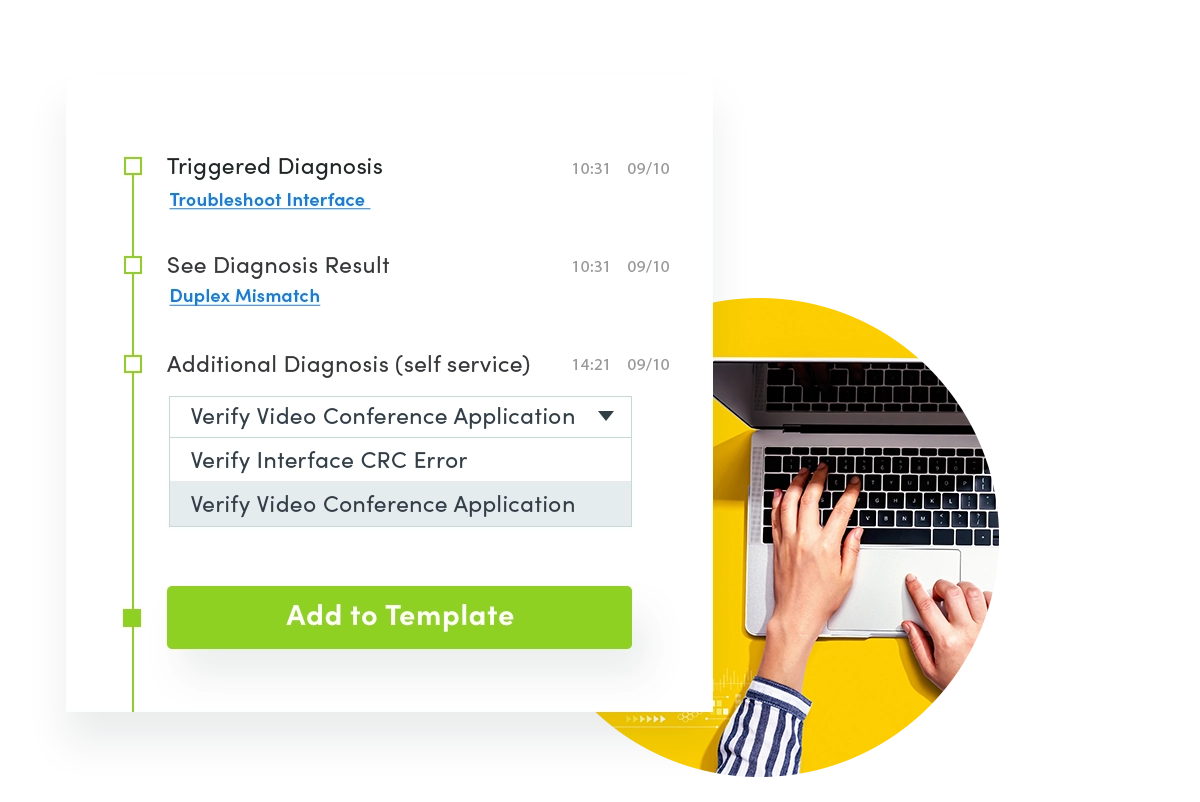
Auch heute noch hört man viel darüber, wie Netzwerker Programmierer werden müssen. Ich sehe nicht wirklich, dass es für uns ein natürlicher Schritt ist, vom Netzwerktechniker zum Entwickler zu werden – oder eine Lösung für die Netzwerkautomatisierung.
Wann auf den Knopf drücken?
Was meinen wir mit „Wann auf den Knopf drücken“? Die Leute denken, dass wir mit der Automatisierung es einmal schreiben, es veröffentlichen sollten und alles wird sich von selbst erledigen. Aber in der realen Welt funktioniert das nicht so. Irgendjemand muss diese Automatisierung auslösen – für die Fehlersuche, change management, Sicherheit, was auch immer. Wenn mitten in der Nacht ein Ausfall auftritt, wer startet dann die Automatisierung, die das Problem diagnostiziert? Und wann? Heute ist dies eine große Herausforderung für die Netzwerkautomatisierung, die wir lösen müssen.
Anpassung an hybride Netzwerke
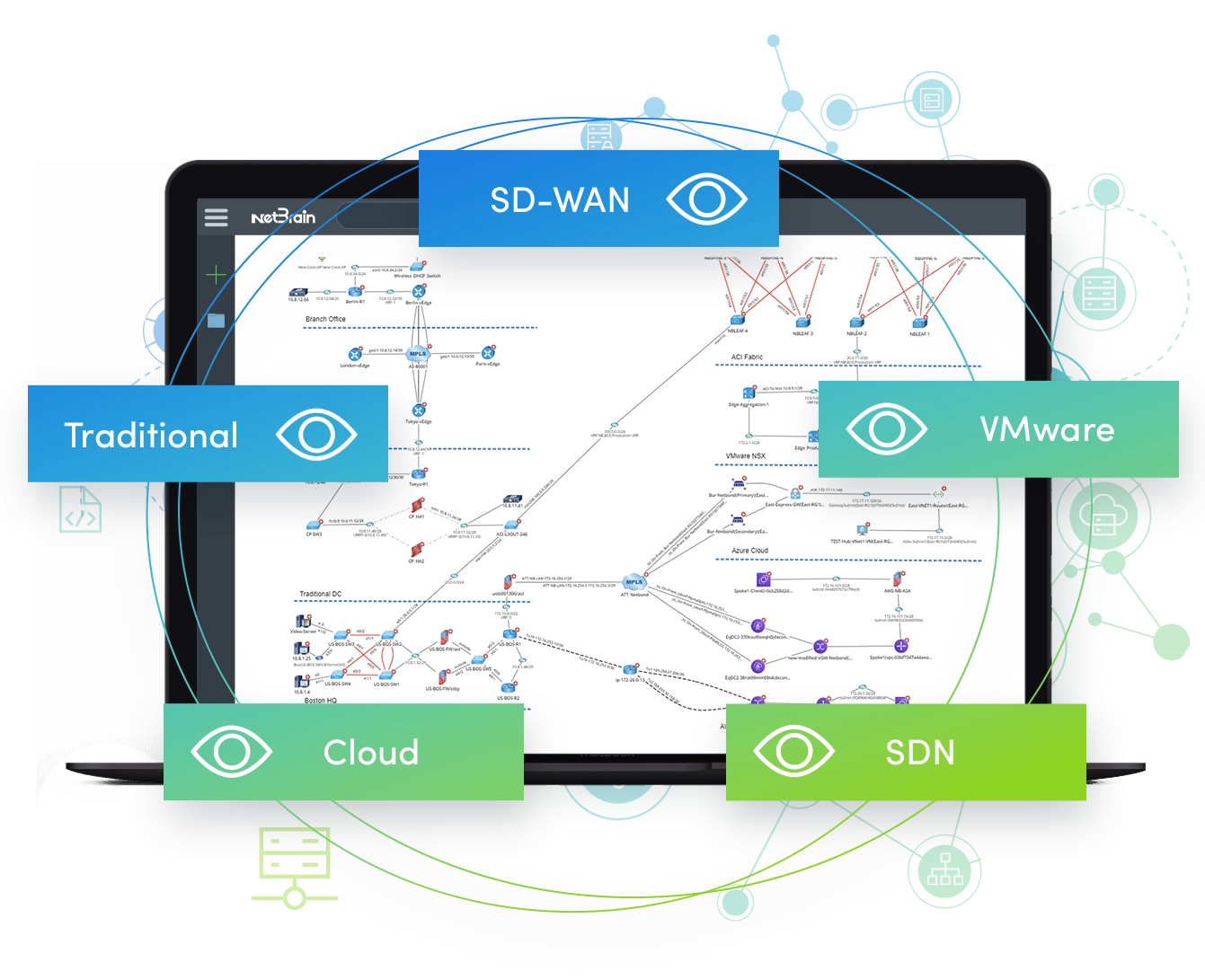
We sind zum Hybriden gehen. Ob es Ihnen gefällt oder nicht, es kommen weitere ACI-, NSX- und andere SDN-Rechenzentren. Es kommt noch mehr SD-WAN. Das traditionelle Netzwerk, das wir kennen und mit dem wir uns gerade beschäftigt haben, reicht nicht mehr aus. „Schreiben Sie es einmal, verwenden Sie es einmal“ für den größten Teil der Automatisierung in einem traditionellen Netzwerk? Damit sind wir heute ständig konfrontiert. Sie könnten sagen: „Okay, wir trennen die Automatisierung für das herkömmliche Netzwerk vom neuen Netzwerk.“ Aber was ist mit dem Verkehrsfluss? Wenn der Übergang von Ihrem traditionellen Netzwerk zu Ihrem SDN langsam ist, wie gehen Sie damit um? Wir müssen also herausfinden, wie wir innerhalb des hybriden Netzwerks automatisieren können – dasselbe gilt für ein Multi-Vendor-Netzwerk.
Wir haben bereits viele Tools – oder Lösungen. Aber jedes Tool spricht seine eigene Sprache; Sie sind ihre eigene „Dateninsel“. Sie haben ein Leistungsüberwachungstool, das nicht mit dem Ereignisverwaltungstool kommuniziert, das nicht mit dem Angriffserkennungssystem kommuniziert, und so weiter. Alle wichtigen Informationen, die Sie benötigen – gebündelt – sind in Datensilos voneinander isoliert.
Wie also meistern wir diese Herausforderungen? Wir haben versucht, die Hardware aufzurüsten, die Software zu ändern, die Leute auszutauschen – das ist nicht die Lösung. Wir brauchen Automatisierung, die anders denkt. Wir brauchen adaptive Automatisierung.
Adaptive Automatisierung
Das Konzept der adaptiven Automatisierung ist nichts Neues. Im Bereich Maschinenbau gibt es eine CAD-Lösung (Computer Aided Design); die Elektronikindustrie hat EDA (Electronic Design Automation); In der Vernetzung gibt es etwas Ähnliches: Wir nennen es Adaptive Automation. Die Idee dahinter ist, dass Sie, wenn Sie eine Reihe von Aufgaben haben, die Sie in einem komplexen Netzwerk ausführen müssen und die verschiedene Dateninseln integrieren müssen, zwei Dinge benötigen, um das Problem zu lösen.
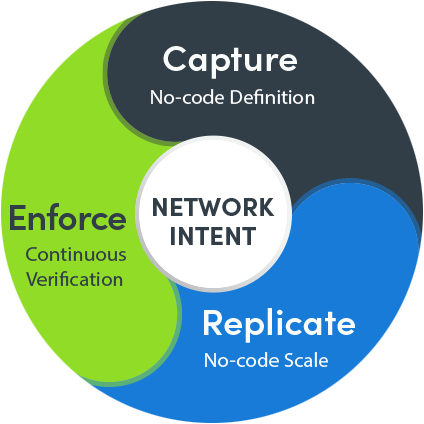
Einer ist eine Karte. In CAD oder EDA ist das Diagramm (oder die Karte) eigentlich ein Datenmodell, das Dinge in einem visuellen Format abstrahiert. Sie brauchen also eine Karte, um Ihre Aufgabe abstrahieren zu können. Eine Karte ermöglicht es Ihnen, die zu definieren Umfang Ihrer Aufgabe.
Das andere Puzzleteil ist a runbook – kein Skript – mit dem Sie organisieren können, was Sie tun müssen. Das runbook erlaubt Ihnen, die zu definieren Schritte Ihrer Aufgabe.
Zusammen verwirklicht die Karte die Idee, Ihr Netzwerk zu dokumentieren, eine zentrale Ansicht Ihres Netzwerks zu erstellen und die runbook realisiert „Just-in-Time“-Automatisierung und „Write Once, Execute Everywhere“-Fähigkeit.
Diese adaptive Automatisierung behandelt die Netzwerkautomatisierung Schritt für Schritt, Schritt für Schritt, für die 5 oben genannten Herausforderungen. Schauen wir uns ein Beispiel an, wie das aussehen würde.
Fehlerbehebungs-Workflow unter Adaptive Automation
Angenommen, Sie erhalten eine Benachrichtigung in Ihrer Ereigniskonsole – beispielsweise ein Ticket in ServiceNow, dass eine App langsam ist. Im Adaptive Automation-Framework wird als Erstes eine „Just-in-Time“-Automatisierung über die API ausgelöst, um eine Dynamic Map von dieser Langsamkeit. Dann eine „Level-0-Diagnose“ runbook tritt automatisch in Aktion, um Leistungsdaten, CLI-Befehlsdaten oder Daten aus Ihrem Leistungsverwaltungstool zu sammeln und die Informationen an das ServiceNow-Ticket anzuhängen. Dies alles geschieht automatisch in dem Moment, in dem das Ereignis erstellt wird, wenn die Langsamkeit erkannt wird – beispielsweise mitten in der Nacht –, ohne dass ein menschliches Eingreifen erforderlich ist. (Deshalb wird es als „Level-0-Diagnose“ bezeichnet.) Das ist Schritt 1.
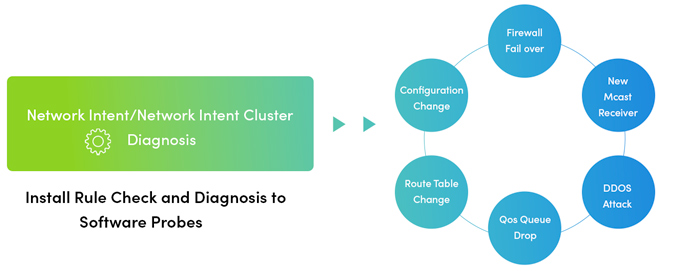
Schritt 2: Morgens, wenn Sie zur Arbeit kommen, gibt es das ServiceNow, das mitten in der Nacht erstellt wurde. Jetzt führen Sie verschiedene Slowness-Performance- oder QoS-Troubleshootings durch runbookS. Diese Runbooks wurden von Ihren leitenden Netzwerkingenieuren auf der Grundlage ihres Know-hows, sowohl ihres Domänenwissens als auch ihrer Fachkompetenz, erstellt. Falls erforderlich, kann der Level 1-Techniker das Problem dann an einen Level 2- oder 3-Techniker eskalieren. Wenn das Ticket eskaliert wird, wird alles, was der Level 1-Techniker getan hat, in der erfasst runbook So muss der Techniker der nächsten Stufe das Rad nicht neu erfinden und dieselben grundlegenden Diagnosen erneut durchführen. Um tiefer in das Problem einzudringen, können Sie eine einzige Glasscheibe nutzen, um Informationen aus allen anderen Tools (Splunk, Protokolldateien, Lösungen zur Leistungsüberwachung rund um die Uhr) anzuzeigen.
Sobald Sie das Problem identifiziert haben – und das nimmt etwa 80 % unserer Fehlerbehebungszeit in Anspruch – können Sie das Problem beheben. Das Beheben von Problemen ist ziemlich einfach: Ändern Sie möglicherweise die QoS-Konfiguration, leiten Sie den Datenverkehr möglicherweise um. Und Sie haben ein Automatisierungstool, das die Änderungen nicht nur übertragen, sondern auch die Auswirkungen dieser Änderungen automatisch überprüfen kann. Dies ist eigentlich wichtiger, als die Änderungen automatisch zu pushen.
Mit Adaptive Automation können Sie dieses Problem dann proaktiv überwachen, sodass Sie es sofort erfassen können, wenn es erneut auftritt (was wahrscheinlich der Fall sein wird), ohne darauf warten zu müssen, dass jemand eine Entscheidung darüber trifft, wie es angegangen werden soll. Die Schritte Ihres Level 2-Ingenieurwerkzeugs können in a kodiert werden runbook die ausgelöst werden können, um automatisch rund um die Uhr ausgeführt zu werden.
 by Jan 9, 2023
by Jan 9, 2023 