 by Phillip Gervasi Nov 9, 2017
by Phillip Gervasi Nov 9, 2017
With huge flat screen TVs mounted on the walls displaying various maps and blinking lights, a network operations center can look like mission control at NASA. But the main purpose of a network operations center, or NOC, isn’t to run a mission to the moon but to maintain and optimize operations for a network infrastructure.
If you think that’s a broad statement which needs elaboration, you’d be right. The idea of centralized network operations can be ambiguous and the purpose multi-faceted, so let’s break it down into three areas: monitoring, logging, and taking action.
Monitoring
Monitoring is a struggle for many NOCs. Some stitch together a patchwork of log aggregators and alerting systems into some semblance of a unified monitoring solution. These types of projects start with great enthusiasm but quickly unravel into a seldom-used collection of platforms that don’t speak to each other and that no one logs into anymore.
But whether a network operations team uses an out-of-band tap network or the built-in functionality of their switches and routers, alarms and alerts are the lifeblood of NOC technicians.
Imagine this scenario: one tool is needed to get information from the legacy switches, but that tool doesn’t work with the new data center switches. Another tool is needed for those. And yet another is needed for the firewalls because they don’t support CDP or LLDP.
It’s not easy to monitor a variety of divergent platforms all at once. Typically, engineers are beholden to pre-packaged software that contains whatever modules the developers thought their customers need. This limits what the NOC can do and how effective it can be at monitoring an infrastructure.
Nevertheless, monitoring is what provides technicians network awareness, or in other words, a clear sense of what the network is doing at any given time.
Logging
Logs memorialize everything going on in the network, providing clues for troubleshooting and evidence for security incidents. Unfortunately, they can be extremely onerous to use effectively — making logging both a curse and a blessing to a typical NOC.
Part of making use of log information is creating benchmarks of network state at meaningful intervals. This is critical for determining trends and mapping application flows. This idea shows up in blogs, whitepapers, and best-practice documents, yet benchmarks are seldom done by even the largest NOCs because of how difficult they are to do.
An e-commerce company might create and store an incredible amount of log information, but it could also create benchmark snapshots of the network during times of peak activity such as Black Friday, weekends, and during promotional events. This information gives network technicians visibility into application flows when the network is under strain to track load balancing and expose bottlenecks.
The problem is that creating benchmarks is not easy and is neglected as a result. It requires capturing network data from a variety of platforms at once and with relation to each other. However, capturing this data over time gives NOC technicians a model from which to work and from which to build their network awareness. And having this information instantly available to the entire team fosters a culture of collaboration.
Taking Action
NOCs monitor networks to catch anomalous activity and take some action on it. They monitor infrastructure health and security and take actions to ensure optimal network performance, resolve incidents, and maintain a transparent change management process.
When an alert comes in, the NOC responds. A ticket is created to track the incident, an engineer takes ownership of it, and the process of troubleshooting begins.
When business continuity is affected, a NOC requires a sense of urgency, clear workflows, and optimized operations. There’s no time to log into random devices and hunt down the issue by taking shots in the dark.
Automation and information sharing is vital to remediating the incident as quickly as possible.
Mean time to repair, or MTTR, is the average time it takes to remediate an incident. An optimized NOC will use automation to reduce MTTR to restore business continuity as soon as possible.
This might include running a script to find configuration differences between running configs and benchmarks. It might also include the capability to programmatically roll back changes in order to restore services quickly. And if devices must be configured to fix the problem, the NOC must have the confidence that they’re not making matters worse. This means that an optimized NOC needs a validation mechanism to test changes before they’re implemented.
How NetBrain Solves These Problems
Relying heavily on automation, NetBrain easily integrates into a NOC’s workflow to provide the means to execute in each of the three main areas.
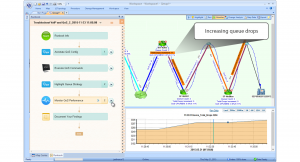 First, NetBrain doesn’t lock engineers into a few specific modules. Executable Runbooks, for example, allow technicians to create custom logic which can be deployed to entire groups of devices. In this way, engineers can create custom reporting and alerting to meet their unique needs and for their particular platforms. Easy customization is necessary for end-to-end visibility.
First, NetBrain doesn’t lock engineers into a few specific modules. Executable Runbooks, for example, allow technicians to create custom logic which can be deployed to entire groups of devices. In this way, engineers can create custom reporting and alerting to meet their unique needs and for their particular platforms. Easy customization is necessary for end-to-end visibility.
Second, though most enterprise NOCs appreciate the value of good logging, NetBrain goes a step further to give engineers the ability to create Benchmarks of their network either at planned intervals or even on-demand.
Engineers seeking to optimize NOC operations can create a Benchmark before and after a change, at regular intervals such as every week, during times of peak activity, or possibly at the beginning and end of a shift. This is an incredible way for a NOC to track network changes.
NetBrain gives everyone on the team working on an incident easy access to the same information in real-time. Dynamic Maps and Executable Runbooks provide the ability for the team to both memorialize information and also instantly share data in an easily consumable format 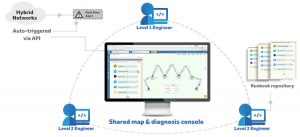 helping to build collaboration among engineers.
helping to build collaboration among engineers.
Third, NetBrain is an asset in reducing mean time to repair. No longer are engineers in the middle of an outage scrambling to log into devices searching for diffs and looking up commands; instead, the cumulative effect of Executable Runbooks, Dynamic Maps, and on-demand Benchmarks means that technical teams can find and resolve issues quickly as well as test new configuration efficiently. For example, NetBrain automates CLI commands and selects meaningful information from the output to display on a Dynamic Map — ultimately saving hours of troubleshooting and reducing the overall time it takes a NOC to find a resolution.
Additionally, shooting from the hip with command line tools such as traceroute are limiting and tedious to use. Traceroute, in particular, can’t provide information about layer 2 hops — severely limiting visibility — and trying to map a network in this way can take hours rather than seconds with NetBrain.
Today’s enterprise IT departments don’t run missions to the stars, but they are critical in maintaining a healthy network. This means automated monitoring, logging, and the ability to take swift action in the event of failure. Perhaps one day networks will truly be self-healing, but until then, our network operations centers are the heroes of keeping the lights on.