 by kelly.yue Oct 12, 2018
by kelly.yue Oct 12, 2018
Today’s 24×7 network monitoring tools have gotten really good at alerting on issues on the network, but even the best ones don’t really help teams solve network problems. Monitoring tools raise alerts and help to identify symptoms but not the underlying causes of the problem. You’re left looking for that proverbial needle in a haystack. 24×7 network monitoring solutions have moved the industry a step forward on proactive monitoring but the process of investigating a problem after an alert is raised is still a slow and manual process that requires additional tools.
The Strength of Network Monitoring Tools
Traditional 24×7 monitoring solutions, such as SevOne, Solarwinds, NetScout, or ExtraHop, to name a few; monitor the network for many symptoms. They provide the network teams with alerts when conditions deviate from baseline network traffic. These alerts can consist of a down interface, high bandwidth utilization, packet loss, and more. One of the strengths of these tools is the ability to allow users to identify what they want to be alerted on from a wide range of metrics that transcend network performance, like volume capacity of storage devices, application and server issues, SLA service times and cloud-based infrastructure performance. These solutions let you know there’s a problem via dashboards, but most of them fail to deliver the right level of detail needed for subsequent troubleshooting. It’s still up to you to further investigate the root cause of the problem, identify the solution and apply the fix, resulting in “swivel-chair” data gathering across other tools and wasted time.
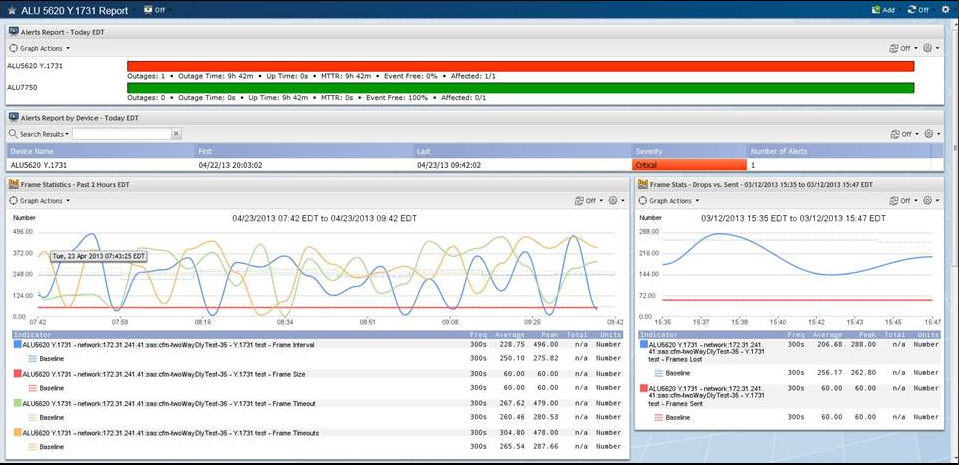
Example of network monitoring dashboard: Network Monitoring Solutions provide users with predictive alerts when conditions deviate from baseline network traffic.
The Value of Visualization & Automation in Troubleshooting
Today, following an alert from a monitoring solution, your team usually performs manual data collection and analysis box by box through the command line interface (CLI). However, finding the source of the problem is usually the hardest but most crucial part of troubleshooting a network problem. With NetBrain, once the alert is received, you can quickly understand the impacted area with detailed, layered visualization of diagnostic data. NetBrain helps you to visualize the results of its own diagnostics as well as data from the monitoring solution and other tools you may be using; which means you have contextualized the problem at hand, right on a Dynamic Map.
For example, an alert is received about a critical application running slow. With NetBrain, you can instantly generate a map of the application path from just the user IP address and the IP address of the application’s server. The system looks at live network data like routing tables, NAT, policy-based routing, access lists, VRFs, etc., to build the map. The map is specific, includes data in context, and since it only took a few seconds to create, probably saved hours of time. Now you can get to solving the problem, instead of just trying to find it.
From the map, you can run automated applications that pull relevant data from all devices along the path — memory and CPU utilization, interface issues such as collisions, CRC errors and more — to drill into what could be causing the problem. Virtually any repetitive, time-consuming data collection and analysis task can be automated in an Executable Runbook —a series of predefined, automatically executed workflow steps.
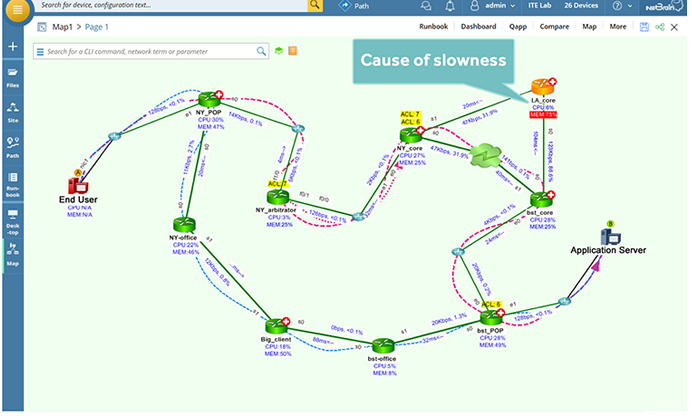
Visualize and analyze a slow application path to pinpoint root-cause problems — here, an overutilized router due to asymmetric application traffic paths.
Integrate NetBrain with your Monitoring Solution for a True Single Pane of Glass Experience
NetBrain can integrate with other tools via RESTful API. This integration layers data from various sources – including data from virtually any monitoring solution – onto a Dynamic Map. This makes NetBrain a modern User Interface for effective troubleshooting and network management. Let’s say that an alert is raised by your monitoring system, the related results are displayed right on a Dynamic Map, with a link that takes you to the source, if needed. The map presents the layers of data in context and interactively so it eliminates the need to jump from screen to screen, CLI to CLIO or stitch together disparate data sets. What makes this “single pane of glass” so powerful is that it is presented in an intuitive map, rather than a chart or a dashboard.
This single pane of glass is presented to you regardless of your network infrastructure. NetBrain brings unprecedented visibility into traditional, virtualized, hybrid and SDN environments, which reduces troubleshooting time and helps your team to easily execute many network-related tasks. In this troubleshooting case, the tasks can be accomplished without the “swivel-chair” approach that forces engineers to hop from tool to tool, losing context.

A Dynamic Map is the modern User Interface that offers a true single pane of glass experience.
Integrate NetBrain with your Monitoring Solution to Achieve “Just-In-Time” Automation
Imagine if all this visualization and diagnosis occurred automatically as soon as an alert is detected. By integrating NetBrain with your 24×7 monitoring solution, you can configure this to happen automatically. The monitoring tool can be set up to trigger a NetBrain diagnosis as soon as an alert is raised. NetBrain automatically maps around the problematic device and collects diagnostic data. This type of event-triggered automation is called “just in time” automation because it kicks off as the event is happening before your incident-response team even gets to see it.
This just-in-time automation provides real-time visibility and diagnostics from the moment the incident occurred. This data visualization informs your team on how to respond quickly, saving critical time otherwise spent collecting and analyzing data. NetBrain can provide you with instant access to a Dynamic Map of the problem area and Runbook data which provide actionable insights. This is the most effective way to tackle those (increasingly commonplace) intermittent problems that seem to have disappeared into thin air before they’re found.
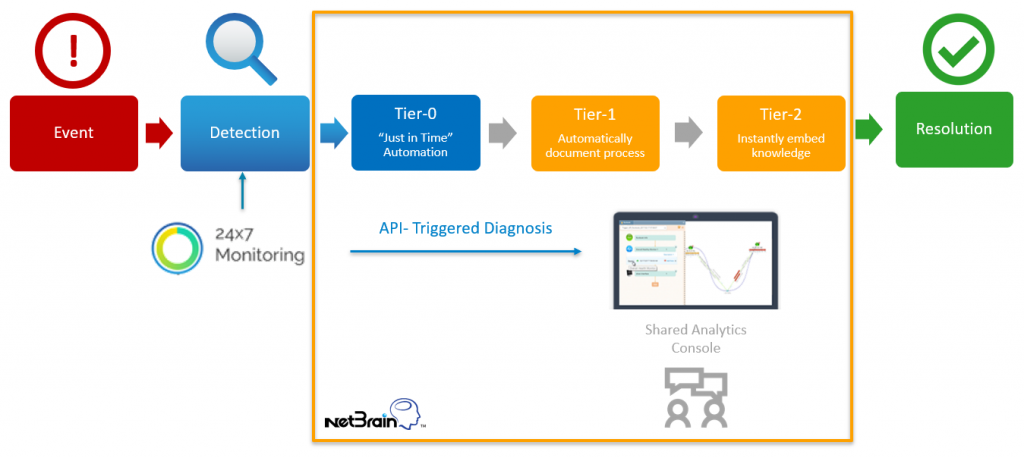
Organizations typically see the most value by integrating NetBrain with their existing network monitoring solutions.
Problem-based Monitoring Can Do More than Just Find Symptoms
Once the problem is resolved, it’s easy to move on to the next issue. But, taking a minute to schedule NetBrain to continuously monitor for this underlying problem gives you the peace of mind that this problem will not be a recurring nuisance. NetBrain Qapp Scheduler can automate those next best steps to resolve issue that you just took when you became aware of the problem the first time instead of simply waiting to get alerted about the situation again.
To illustrate this point let’s imagine that the monitoring system has detected high utilization on a link between the data center and the headquarters office. The alert was raised promptly, but you still do not know why there is a high utilization on this link, this fact-finding will take time. After troubleshooting, the problem has turned out to be that a firewall failed over in the data center. The backup kicked in properly, but it was not configured the same as the primary and it couldn’t handle the high bandwidth demands. Your team wonders if there could be a similar problem elsewhere in the network. To uncover any similar problems, they will need to inspect all the configs in the backup firewalls, which could take a long time depending on how many of these firewalls are in the network.
A NetBrain Qapp can automate this task and inspect all of the configs on the backup firewalls. NetBrain can now automatically compare configs between Active & Standby firewalls periodically as specified by your team, effectively monitoring for this problem in the future.
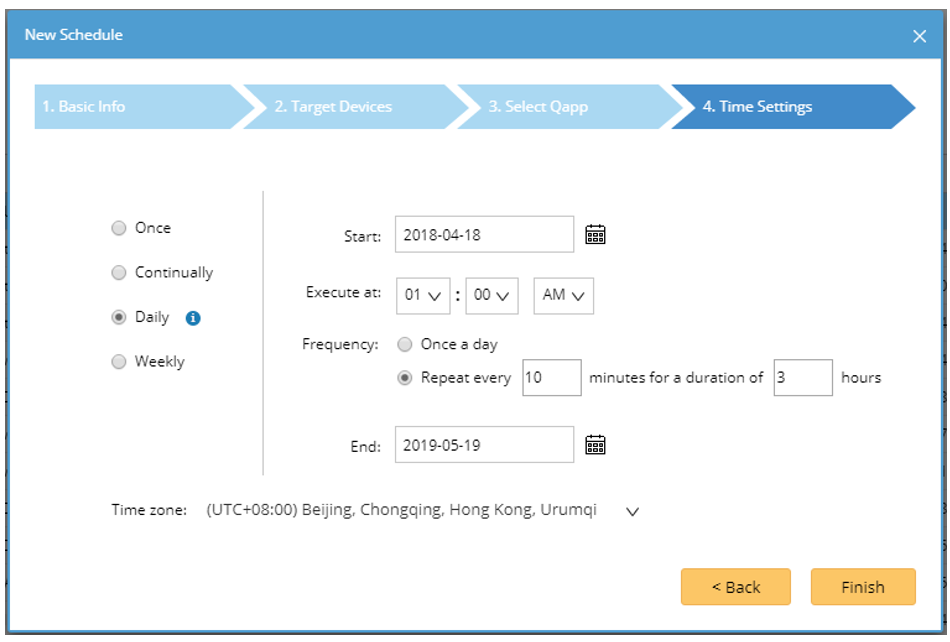
NetBrain monitors the network for underlying problems like comparing configs between Active and Standby firewalls. The user can schedule a Qapp to run every 10 minutes, for example, and alert on defined parameters.
NetBrain customers typically see the most value by integrating NetBrain with their existing network monitoring solutions. This helps them to achieve “just in time” automation and address the challenges of manual troubleshooting once an alert is reported. Integration also enables enhanced visualization of the problem area and the ability to monitor for specific problems -instead of symptoms- in the future.